 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Embodied Agents
Apr 17, 2024



Embodied agents operating in complex and uncertain environments face considerable challenges. While some advanced agents handle complex manipulation tasks with proficiency, their success often hinges on extensive training data to develop their capabilities. In contrast, humans typically rely on recalling past experiences and analogous situations to solve new problems. Aiming to emulate this human approach in robotics, we introduce the Retrieval-Augmented Embodied Agent (RAEA). This innovative system equips robots with a form of shared memory, significantly enhancing their performance. Our approach integrates a policy retriever, allowing robots to access relevant strategies from an external policy memory bank based on multi-modal inputs. Additionally, a policy generator is employed to assimilate these strategies into the learning process, enabling robots to formulate effective responses to tasks. Extensive testing of RAEA in both simulated and real-world scenarios demonstrates its superior performance over traditional methods, representing a major leap forward in robotic technology.
Mipha: A Comprehensive Overhaul of Multimodal Assistant with Small Language Models
Mar 15, 2024Multimodal Large Language Models (MLLMs) have showcased impressive skills in tasks related to visual understanding and reasoning. Yet, their widespread application faces obstacles due to the high computational demands during both the training and inference phases, restricting their use to a limited audience within the research and user communities. In this paper, we investigate the design aspects of Multimodal Small Language Models (MSLMs) and propose an efficient multimodal assistant named Mipha, which is designed to create synergy among various aspects: visual representation, language models, and optimization strategies. We show that without increasing the volume of training data, our Mipha-3B outperforms the state-of-the-art large MLLMs, especially LLaVA-1.5-13B, on multiple benchmarks. Through detailed discussion, we provide insights and guidelines for developing strong MSLMs that rival the capabilities of MLLMs. Our code is available at https://github.com/zhuyiche/Mipha.
LLaVA-Phi: Efficient Multi-Modal Assistant with Small Language Model
Jan 15, 2024In this paper, we introduce LLaVA-$\phi$ (LLaVA-Phi), an efficient multi-modal assistant that harnesses the power of the recently advanced small language model, Phi-2, to facilitate multi-modal dialogues. LLaVA-Phi marks a notable advancement in the realm of compact multi-modal models. It demonstrates that even smaller language models, with as few as 2.7B parameters, can effectively engage in intricate dialogues that integrate both textual and visual elements, provided they are trained with high-quality corpora. Our model delivers commendable performance on publicly available benchmarks that encompass visual comprehension, reasoning, and knowledge-based perception. Beyond its remarkable performance in multi-modal dialogue tasks, our model opens new avenues for applications in time-sensitive environments and systems that require real-time interaction, such as embodied agents. It highlights the potential of smaller language models to achieve sophisticated levels of understanding and interaction, while maintaining greater resource efficiency.The project is available at {https://github.com/zhuyiche/llava-phi}.
Make A Long Image Short: Adaptive Token Length for Vision Transformers
Dec 06, 2021The vision transformer splits each image into a sequence of tokens with fixed length and processes the tokens in the same way as words in natural language processing. More tokens normally lead to better performance but considerably increased computational cost. Motivated by the proverb "A picture is worth a thousand words" we aim to accelerate the ViT model by making a long image short. To this end, we propose a novel approach to assign token length adaptively during inference. Specifically, we first train a ViT model, called Resizable-ViT (ReViT), that can process any given input with diverse token lengths. Then, we retrieve the "token-length label" from ReViT and use it to train a lightweight Token-Length Assigner (TLA). The token-length labels are the smallest number of tokens to split an image that the ReViT can make the correct prediction, and TLA is learned to allocate the optimal token length based on these labels. The TLA enables the ReViT to process the image with the minimum sufficient number of tokens during inference. Thus, the inference speed is boosted by reducing the token numbers in the ViT model. Our approach is general and compatible with modern vision transformer architectures and can significantly reduce computational expanse. We verified the effectiveness of our methods on multiple representative ViT models (DeiT, LV-ViT, and TimesFormer) across two tasks (image classification and action recognition).
Training BatchNorm Only in Neural Architecture Search and Beyond
Dec 01, 2021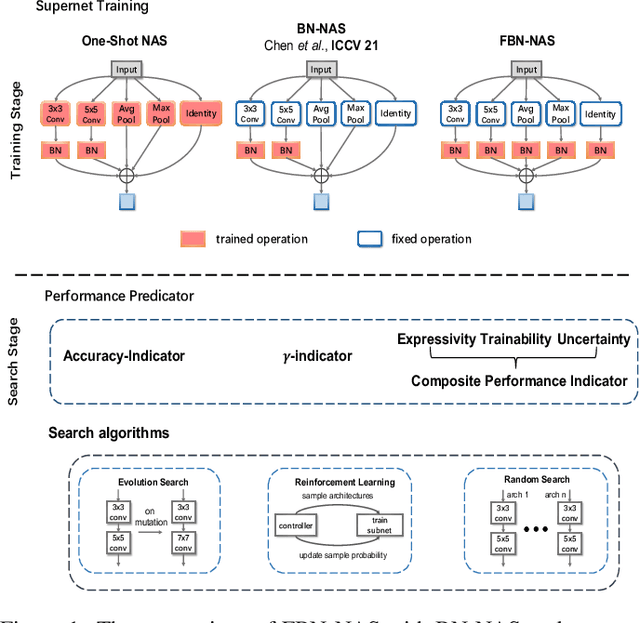

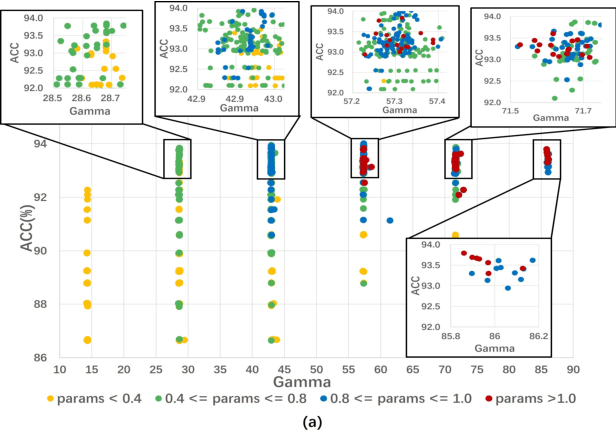

This work investigates the usage of batch normalization in neural architecture search (NAS). Specifically, Frankle et al. find that training BatchNorm only can achieve nontrivial performance. Furthermore, Chen et al. claim that training BatchNorm only can speed up the training of the one-shot NAS supernet over ten times. Critically, there is no effort to understand 1) why training BatchNorm only can find the perform-well architectures with the reduced supernet-training time, and 2) what is the difference between the train-BN-only supernet and the standard-train supernet. We begin by showing that the train-BN-only networks converge to the neural tangent kernel regime, obtain the same training dynamics as train all parameters theoretically. Our proof supports the claim to train BatchNorm only on supernet with less training time. Then, we empirically disclose that train-BN-only supernet provides an advantage on convolutions over other operators, cause unfair competition between architectures. This is due to only the convolution operator being attached with BatchNorm. Through experiments, we show that such unfairness makes the search algorithm prone to select models with convolutions. To solve this issue, we introduce fairness in the search space by placing a BatchNorm layer on every operator. However, we observe that the performance predictor in Chen et al. is inapplicable on the new search space. To this end, we propose a novel composite performance indicator to evaluate networks from three perspectives: expressivity, trainability, and uncertainty, derived from the theoretical property of BatchNorm. We demonstrate the effectiveness of our approach on multiple NAS-benchmarks (NAS-Bench101, NAS-Bench-201) and search spaces (DARTS search space and MobileNet search space).