 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectVLA: End-to-End Open-World Object Manipulation Without Demonstration
Feb 26, 2025Imitation learning has proven to be highly effective in teaching robots dexterous manipulation skills. However, it typically relies on large amounts of human demonstration data, which limits its scalability and applicability in dynamic, real-world environments. One key challenge in this context is object generalization, where a robot trained to perform a task with one object, such as "hand over the apple," struggles to transfer its skills to a semantically similar but visually different object, such as "hand over the peach." This gap in generalization to new objects beyond those in the same category has yet to be adequately addressed in previous work on end-to-end visuomotor policy learning. In this paper, we present a simple yet effective approach for achieving object generalization through Vision-Language-Action (VLA) models, referred to as \textbf{ObjectVLA}. Our model enables robots to generalize learned skills to novel objects without requiring explicit human demonstrations for each new target object. By leveraging vision-language pair data, our method provides a lightweight and scalable way to inject knowledge about the target object, establishing an implicit link between the object and the desired action. We evaluate ObjectVLA on a real robotic platform, demonstrating its ability to generalize across 100 novel objects with a 64\% success rate in selecting objects not seen during training. Furthermore, we propose a more accessible method for enhancing object generalization in VLA models, using a smartphone to capture a few images and fine-tune the pre-trained model. These results highlight the effectiveness of our approach in enabling object-level generalization and reducing the need for extensive human demonstrations, paving the way for more flexible and scalable robotic learning systems.
ChatVLA: Unified Multimodal Understanding and Robot Control with Vision-Language-Action Model
Feb 21, 2025Humans possess a unified cognitive ability to perceive, comprehend, and interact with the physical world. Why can't large language models replicate this holistic understanding? Through a systematic analysis of existing training paradigms in vision-language-action models (VLA), we identify two key challenges: spurious forgetting, where robot training overwrites crucial visual-text alignments, and task interference, where competing control and understanding tasks degrade performance when trained jointly. To overcome these limitations, we propose ChatVLA, a novel framework featuring Phased Alignment Training, which incrementally integrates multimodal data after initial control mastery, and a Mixture-of-Experts architecture to minimize task interference. ChatVLA demonstrates competitive performance on visual question-answering datasets and significantly surpasses state-of-the-art vision-language-action (VLA) methods on multimodal understanding benchmarks. Notably, it achieves a six times higher performance on MMMU and scores 47.2% on MMStar with a more parameter-efficient design than ECoT. Furthermore, ChatVLA demonstrates superior performance on 25 real-world robot manipulation tasks compared to existing VLA methods like OpenVLA. Our findings highlight the potential of our unified framework for achieving both robust multimodal understanding and effective robot control.
Fresh-CL: Feature Realignment through Experts on Hypersphere in Continual Learning
Jan 04, 2025



Continual Learning enables models to learn and adapt to new tasks while retaining prior knowledge.Introducing new tasks, however, can naturally lead to feature entanglement across tasks, limiting the model's capability to distinguish between new domain data.In this work, we propose a method called Feature Realignment through Experts on hyperSpHere in Continual Learning (Fresh-CL). By leveraging predefined and fixed simplex equiangular tight frame (ETF) classifiers on a hypersphere, our model improves feature separation both intra and inter tasks.However, the projection to a simplex ETF shifts with new tasks, disrupting structured feature representation of previous tasks and degrading performance. Therefore, we propose a dynamic extension of ETF through mixture of experts, enabling adaptive projections onto diverse subspaces to enhance feature representation.Experiments on 11 datasets demonstrate a 2\% improvement in accuracy compared to the strongest baseline, particularly in fine-grained datasets, confirming the efficacy of combining ETF and MoE to improve feature distinction in continual learning scenarios.
Improving Vision-Language-Action Models via Chain-of-Affordance
Dec 29, 2024



Robot foundation models, particularly Vision-Language-Action (VLA) models, have garnered significant attention for their ability to enhance robot policy learning, greatly improving robot generalization and robustness. OpenAI recent model, o1, showcased impressive capabilities in solving complex problems by utilizing extensive reasoning chains. This prompts an important question: can robot models achieve better performance in multi-task, complex environments by reviewing prior observations and then providing task-specific reasoning to guide action prediction? In this paper, we introduce \textbf{Chain-of-Affordance (CoA)}, a novel approach to scaling robot models by incorporating reasoning in the format of sequential robot affordances to facilitate task completion. Specifically, we prompt the model to consider the following four types of affordances before taking action: a) object affordance - what object to manipulate and where it is; b) grasp affordance - the specific object part to grasp; c) spatial affordance - the optimal space to place the object; and d) movement affordance - the collision-free path for movement. By integrating this knowledge into the policy model, the robot gains essential context, allowing it to act with increased precision and robustness during inference. Our experiments demonstrate that CoA achieves superior performance than state-of-the-art robot foundation models, such as OpenVLA and Octo. Additionally, CoA shows strong generalization to unseen object poses, identifies free space, and avoids obstacles in novel environments.
Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression
Dec 04, 2024In this paper, we present DiffusionVLA, a novel framework that seamlessly combines the autoregression model with the diffusion model for learning visuomotor policy. Central to our approach is a next-token prediction objective, enabling the model to reason effectively over the user's query in the context of current observations. Subsequently, a diffusion model is attached to generate robust action outputs. To enhance policy learning through self-reasoning, we introduce a novel reasoning injection module that integrates reasoning phrases directly into the policy learning process. The whole framework is simple and flexible, making it easy to deploy and upgrade. We conduct extensive experiments using multiple real robots to validate the effectiveness of DiffusionVLA. Our tests include a challenging factory sorting task, where DiffusionVLA successfully categorizes objects, including those not seen during training. We observe that the reasoning module makes the model interpretable. It allows observers to understand the model thought process and identify potential causes of policy failures. Additionally, we test DiffusionVLA on a zero-shot bin-picking task, achieving 63.7\% accuracy on 102 previously unseen objects. Our method demonstrates robustness to visual changes, such as distractors and new backgrounds, and easily adapts to new embodiments. Furthermore, DiffusionVLA can follow novel instructions and retain conversational ability. Notably, DiffusionVLA is data-efficient and fast at inference; our smallest DiffusionVLA-2B runs 82Hz on a single A6000 GPU and can train from scratch on less than 50 demonstrations for a complex task. Finally, we scale the model from 2B to 72B parameters, showcasing improved generalization capabilities with increased model size.
Scaling Diffusion Policy in Transformer to 1 Billion Parameters for Robotic Manipulation
Sep 22, 2024



Diffusion Policy is a powerful technique tool for learning end-to-end visuomotor robot control. It is expected that Diffusion Policy possesses scalability, a key attribute for deep neural networks, typically suggesting that increasing model size would lead to enhanced performance. However, our observations indicate that Diffusion Policy in transformer architecture (\DP) struggles to scale effectively; even minor additions of layers can deteriorate training outcomes. To address this issue, we introduce Scalable Diffusion Transformer Policy for visuomotor learning. Our proposed method, namely \textbf{\methodname}, introduces two modules that improve the training dynamic of Diffusion Policy and allow the network to better handle multimodal action distribution. First, we identify that \DP~suffers from large gradient issues, making the optimization of Diffusion Policy unstable. To resolve this issue, we factorize the feature embedding of observation into multiple affine layers, and integrate it into the transformer blocks. Additionally, our utilize non-causal attention which allows the policy network to \enquote{see} future actions during prediction, helping to reduce compounding errors. We demonstrate that our proposed method successfully scales the Diffusion Policy from 10 million to 1 billion parameters. This new model, named \methodname, can effectively scale up the model size with improved performance and generalization. We benchmark \methodname~across 50 different tasks from MetaWorld and find that our largest \methodname~outperforms \DP~with an average improvement of 21.6\%. Across 7 real-world robot tasks, our ScaleDP demonstrates an average improvement of 36.25\% over DP-T on four single-arm tasks and 75\% on three bimanual tasks. We believe our work paves the way for scaling up models for visuomotor learning. The project page is available at scaling-diffusion-policy.github.io.
MMRo: Are Multimodal LLMs Eligible as the Brain for In-Home Robotics?
Jun 28, 2024



It is fundamentally challenging for robots to serve as useful assistants in human environments because this requires addressing a spectrum of sub-problems across robotics, including perception, language understanding, reasoning, and planning. The recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated their exceptional abilities in solving complex mathematical problems, mastering commonsense and abstract reasoning. This has led to the recent utilization of MLLMs as the brain in robotic systems, enabling these models to conduct high-level planning prior to triggering low-level control actions for task execution. However, it remains uncertain whether existing MLLMs are reliable in serving the brain role of robots. In this study, we introduce the first benchmark for evaluating Multimodal LLM for Robotic (MMRo) benchmark, which tests the capability of MLLMs for robot applications. Specifically, we identify four essential capabilities perception, task planning, visual reasoning, and safety measurement that MLLMs must possess to qualify as the robot's central processing unit. We have developed several scenarios for each capability, resulting in a total of 14 metrics for evaluation. We present experimental results for various MLLMs, including both commercial and open-source models, to assess the performance of existing systems. Our findings indicate that no single model excels in all areas, suggesting that current MLLMs are not yet trustworthy enough to serve as the cognitive core for robots. Our data can be found in https://mm-robobench.github.io/.
Mipha: A Comprehensive Overhaul of Multimodal Assistant with Small Language Models
Mar 15, 2024Multimodal Large Language Models (MLLMs) have showcased impressive skills in tasks related to visual understanding and reasoning. Yet, their widespread application faces obstacles due to the high computational demands during both the training and inference phases, restricting their use to a limited audience within the research and user communities. In this paper, we investigate the design aspects of Multimodal Small Language Models (MSLMs) and propose an efficient multimodal assistant named Mipha, which is designed to create synergy among various aspects: visual representation, language models, and optimization strategies. We show that without increasing the volume of training data, our Mipha-3B outperforms the state-of-the-art large MLLMs, especially LLaVA-1.5-13B, on multiple benchmarks. Through detailed discussion, we provide insights and guidelines for developing strong MSLMs that rival the capabilities of MLLMs. Our code is available at https://github.com/zhuyiche/Mipha.
Language-Conditioned Robotic Manipulation with Fast and Slow Thinking
Feb 01, 2024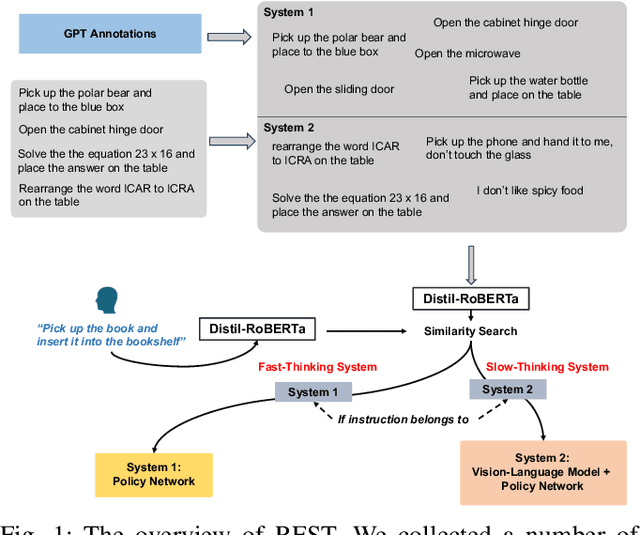



The language-conditioned robotic manipulation aims to transfer natural language instructions into executable actions, from simple pick-and-place to tasks requiring intent recognition and visual reasoning. Inspired by the dual process theory in cognitive science, which suggests two parallel systems of fast and slow thinking in human decision-making, we introduce Robotics with Fast and Slow Thinking (RFST), a framework that mimics human cognitive architecture to classify tasks and makes decisions on two systems based on instruction types. Our RFST consists of two key components: 1) an instruction discriminator to determine which system should be activated based on the current user instruction, and 2) a slow-thinking system that is comprised of a fine-tuned vision language model aligned with the policy networks, which allows the robot to recognize user intention or perform reasoning tasks. To assess our methodology, we built a dataset featuring real-world trajectories, capturing actions ranging from spontaneous impulses to tasks requiring deliberate contemplation. Our results, both in simulation and real-world scenarios, confirm that our approach adeptly manages intricate tasks that demand intent recognition and reasoning. The project is available at https://jlm-z.github.io/RSFT/
LLaVA-Phi: Efficient Multi-Modal Assistant with Small Language Model
Jan 15, 2024In this paper, we introduce LLaVA-$\phi$ (LLaVA-Phi), an efficient multi-modal assistant that harnesses the power of the recently advanced small language model, Phi-2, to facilitate multi-modal dialogues. LLaVA-Phi marks a notable advancement in the realm of compact multi-modal models. It demonstrates that even smaller language models, with as few as 2.7B parameters, can effectively engage in intricate dialogues that integrate both textual and visual elements, provided they are trained with high-quality corpora. Our model delivers commendable performance on publicly available benchmarks that encompass visual comprehension, reasoning, and knowledge-based perception. Beyond its remarkable performance in multi-modal dialogue tasks, our model opens new avenues for applications in time-sensitive environments and systems that require real-time interaction, such as embodied agents. It highlights the potential of smaller language models to achieve sophisticated levels of understanding and interaction, while maintaining greater resource efficiency.The project is available at {https://github.com/zhuyiche/llava-phi}.