 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatVLA-2: Vision-Language-Action Model with Open-World Embodied Reasoning from Pretrained Knowledge
May 29, 2025Vision-language-action (VLA) models have emerged as the next generation of models in robotics. However, despite leveraging powerful pre-trained Vision-Language Models (VLMs), existing end-to-end VLA systems often lose key capabilities during fine-tuning as the model adapts to specific robotic tasks. We argue that a generalizable VLA model should retain and expand upon the VLM's core competencies: 1) Open-world embodied reasoning - the VLA should inherit the knowledge from VLM, i.e., recognize anything that the VLM can recognize, be capable of solving math problems, and possess visual-spatial intelligence, 2) Reasoning following - effectively translating the open-world reasoning into actionable steps for the robot. In this work, we introduce ChatVLA-2, a novel mixture-of-expert VLA model coupled with a specialized two-stage training pipeline designed to preserve the VLM's original strengths while enabling actionable reasoning. To validate our approach, we design a math-matching task wherein a robot interprets math problems written on a whiteboard and picks corresponding number cards from a table to solve equations. Remarkably, our method exhibits exceptional mathematical reasoning and OCR capabilities, despite these abilities not being explicitly trained within the VLA. Furthermore, we demonstrate that the VLA possesses strong spatial reasoning skills, enabling it to interpret novel directional instructions involving previously unseen objects. Overall, our method showcases reasoning and comprehension abilities that significantly surpass state-of-the-art imitation learning methods such as OpenVLA, DexVLA, and pi-zero. This work represents a substantial advancement toward developing truly generalizable robotic foundation models endowed with robust reasoning capacities.
Vision-Language-Action Model with Open-World Embodied Reasoning from Pretrained Knowledge
May 28, 2025Vision-language-action (VLA) models have emerged as the next generation of models in robotics. However, despite leveraging powerful pre-trained Vision-Language Models (VLMs), existing end-to-end VLA systems often lose key capabilities during fine-tuning as the model adapts to specific robotic tasks. We argue that a generalizable VLA model should retain and expand upon the VLM's core competencies: 1) Open-world embodied reasoning - the VLA should inherit the knowledge from VLM, i.e., recognize anything that the VLM can recognize, capable of solving math problems, possessing visual-spatial intelligence, 2) Reasoning following - effectively translating the open-world reasoning into actionable steps for the robot. In this work, we introduce ChatVLA-2, a novel mixture-of-expert VLA model coupled with a specialized three-stage training pipeline designed to preserve the VLM's original strengths while enabling actionable reasoning. To validate our approach, we design a math-matching task wherein a robot interprets math problems written on a whiteboard and picks corresponding number cards from a table to solve equations. Remarkably, our method exhibits exceptional mathematical reasoning and OCR capabilities, despite these abilities not being explicitly trained within the VLA. Furthermore, we demonstrate that the VLA possesses strong spatial reasoning skills, enabling it to interpret novel directional instructions involving previously unseen objects. Overall, our method showcases reasoning and comprehension abilities that significantly surpass state-of-the-art imitation learning methods such as OpenVLA, DexVLA, and pi-zero. This work represents a substantial advancement toward developing truly generalizable robotic foundation models endowed with robust reasoning capacities.
WorldEval: World Model as Real-World Robot Policies Evaluator
May 25, 2025The field of robotics has made significant strides toward developing generalist robot manipulation policies. However, evaluating these policies in real-world scenarios remains time-consuming and challenging, particularly as the number of tasks scales and environmental conditions change. In this work, we demonstrate that world models can serve as a scalable, reproducible, and reliable proxy for real-world robot policy evaluation. A key challenge is generating accurate policy videos from world models that faithfully reflect the robot actions. We observe that directly inputting robot actions or using high-dimensional encoding methods often fails to generate action-following videos. To address this, we propose Policy2Vec, a simple yet effective approach to turn a video generation model into a world simulator that follows latent action to generate the robot video. We then introduce WorldEval, an automated pipeline designed to evaluate real-world robot policies entirely online. WorldEval effectively ranks various robot policies and individual checkpoints within a single policy, and functions as a safety detector to prevent dangerous actions by newly developed robot models. Through comprehensive paired evaluations of manipulation policies in real-world environments, we demonstrate a strong correlation between policy performance in WorldEval and real-world scenarios. Furthermore, our method significantly outperforms popular methods such as real-to-sim approach.
ObjectVLA: End-to-End Open-World Object Manipulation Without Demonstration
Feb 26, 2025Imitation learning has proven to be highly effective in teaching robots dexterous manipulation skills. However, it typically relies on large amounts of human demonstration data, which limits its scalability and applicability in dynamic, real-world environments. One key challenge in this context is object generalization, where a robot trained to perform a task with one object, such as "hand over the apple," struggles to transfer its skills to a semantically similar but visually different object, such as "hand over the peach." This gap in generalization to new objects beyond those in the same category has yet to be adequately addressed in previous work on end-to-end visuomotor policy learning. In this paper, we present a simple yet effective approach for achieving object generalization through Vision-Language-Action (VLA) models, referred to as \textbf{ObjectVLA}. Our model enables robots to generalize learned skills to novel objects without requiring explicit human demonstrations for each new target object. By leveraging vision-language pair data, our method provides a lightweight and scalable way to inject knowledge about the target object, establishing an implicit link between the object and the desired action. We evaluate ObjectVLA on a real robotic platform, demonstrating its ability to generalize across 100 novel objects with a 64\% success rate in selecting objects not seen during training. Furthermore, we propose a more accessible method for enhancing object generalization in VLA models, using a smartphone to capture a few images and fine-tune the pre-trained model. These results highlight the effectiveness of our approach in enabling object-level generalization and reducing the need for extensive human demonstrations, paving the way for more flexible and scalable robotic learning systems.
ChatVLA: Unified Multimodal Understanding and Robot Control with Vision-Language-Action Model
Feb 21, 2025Humans possess a unified cognitive ability to perceive, comprehend, and interact with the physical world. Why can't large language models replicate this holistic understanding? Through a systematic analysis of existing training paradigms in vision-language-action models (VLA), we identify two key challenges: spurious forgetting, where robot training overwrites crucial visual-text alignments, and task interference, where competing control and understanding tasks degrade performance when trained jointly. To overcome these limitations, we propose ChatVLA, a novel framework featuring Phased Alignment Training, which incrementally integrates multimodal data after initial control mastery, and a Mixture-of-Experts architecture to minimize task interference. ChatVLA demonstrates competitive performance on visual question-answering datasets and significantly surpasses state-of-the-art vision-language-action (VLA) methods on multimodal understanding benchmarks. Notably, it achieves a six times higher performance on MMMU and scores 47.2% on MMStar with a more parameter-efficient design than ECoT. Furthermore, ChatVLA demonstrates superior performance on 25 real-world robot manipulation tasks compared to existing VLA methods like OpenVLA. Our findings highlight the potential of our unified framework for achieving both robust multimodal understanding and effective robot control.
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Feb 09, 2025



Enabling robots to perform diverse tasks across varied environments is a central challenge in robot learning. While vision-language-action (VLA) models have shown promise for generalizable robot skills, realizing their full potential requires addressing limitations in action representation and efficient training. Current VLA models often focus on scaling the vision-language model (VLM) component, while the action space representation remains a critical bottleneck. This paper introduces DexVLA, a novel framework designed to enhance the efficiency and generalization capabilities of VLAs for complex, long-horizon tasks across diverse robot embodiments. DexVLA features a novel diffusion-based action expert, scaled to one billion parameters, designed for cross-embodiment learning. A novel embodiment curriculum learning strategy facilitates efficient training: (1) pre-training the diffusion expert that is separable from the VLA on cross-embodiment data, (2) aligning the VLA model to specific embodiments, and (3) post-training for rapid adaptation to new tasks. We conduct comprehensive experiments across multiple embodiments, including single-arm, bimanual, and dexterous hand, demonstrating DexVLA's adaptability to challenging tasks without task-specific adaptation, its ability to learn dexterous skills on novel embodiments with limited data, and its capacity to complete complex, long-horizon tasks using only direct language prompting, such as laundry folding. In all settings, our method demonstrates superior performance compared to state-of-the-art models like Octo, OpenVLA, and Diffusion Policy.
Efficient Feature Fusion for UAV Object Detection
Jan 29, 2025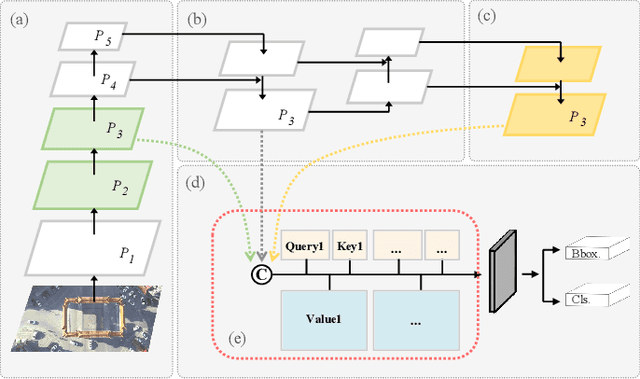
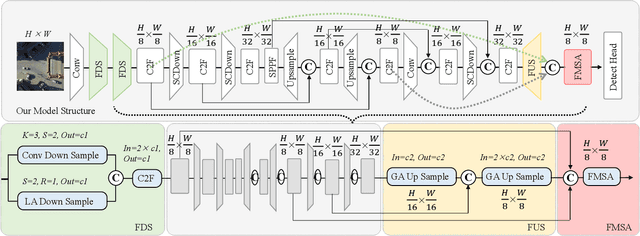
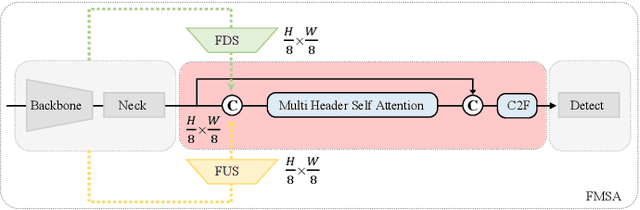
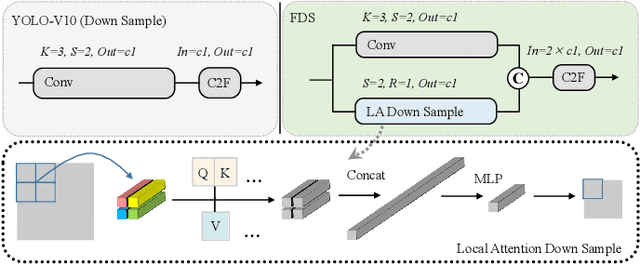
Object detection in unmanned aerial vehicle (UAV) remote sensing images poses significant challenges due to unstable image quality, small object sizes, complex backgrounds, and environmental occlusions. Small objects, in particular, occupy minimal portions of images, making their accurate detection highly difficult. Existing multi-scale feature fusion methods address these challenges to some extent by aggregating features across different resolutions. However, these methods often fail to effectively balance classification and localization performance for small objects, primarily due to insufficient feature representation and imbalanced network information flow. In this paper, we propose a novel feature fusion framework specifically designed for UAV object detection tasks to enhance both localization accuracy and classification performance. The proposed framework integrates hybrid upsampling and downsampling modules, enabling feature maps from different network depths to be flexibly adjusted to arbitrary resolutions. This design facilitates cross-layer connections and multi-scale feature fusion, ensuring improved representation of small objects. Our approach leverages hybrid downsampling to enhance fine-grained feature representation, improving spatial localization of small targets, even under complex conditions. Simultaneously, the upsampling module aggregates global contextual information, optimizing feature consistency across scales and enhancing classification robustness in cluttered scenes. Experimental results on two public UAV datasets demonstrate the effectiveness of the proposed framework. Integrated into the YOLO-V10 model, our method achieves a 2\% improvement in average precision (AP) compared to the baseline YOLO-V10 model, while maintaining the same number of parameters. These results highlight the potential of our framework for accurate and efficient UAV object detection.
Fresh-CL: Feature Realignment through Experts on Hypersphere in Continual Learning
Jan 04, 2025



Continual Learning enables models to learn and adapt to new tasks while retaining prior knowledge.Introducing new tasks, however, can naturally lead to feature entanglement across tasks, limiting the model's capability to distinguish between new domain data.In this work, we propose a method called Feature Realignment through Experts on hyperSpHere in Continual Learning (Fresh-CL). By leveraging predefined and fixed simplex equiangular tight frame (ETF) classifiers on a hypersphere, our model improves feature separation both intra and inter tasks.However, the projection to a simplex ETF shifts with new tasks, disrupting structured feature representation of previous tasks and degrading performance. Therefore, we propose a dynamic extension of ETF through mixture of experts, enabling adaptive projections onto diverse subspaces to enhance feature representation.Experiments on 11 datasets demonstrate a 2\% improvement in accuracy compared to the strongest baseline, particularly in fine-grained datasets, confirming the efficacy of combining ETF and MoE to improve feature distinction in continual learning scenarios.
Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression
Dec 04, 2024In this paper, we present DiffusionVLA, a novel framework that seamlessly combines the autoregression model with the diffusion model for learning visuomotor policy. Central to our approach is a next-token prediction objective, enabling the model to reason effectively over the user's query in the context of current observations. Subsequently, a diffusion model is attached to generate robust action outputs. To enhance policy learning through self-reasoning, we introduce a novel reasoning injection module that integrates reasoning phrases directly into the policy learning process. The whole framework is simple and flexible, making it easy to deploy and upgrade. We conduct extensive experiments using multiple real robots to validate the effectiveness of DiffusionVLA. Our tests include a challenging factory sorting task, where DiffusionVLA successfully categorizes objects, including those not seen during training. We observe that the reasoning module makes the model interpretable. It allows observers to understand the model thought process and identify potential causes of policy failures. Additionally, we test DiffusionVLA on a zero-shot bin-picking task, achieving 63.7\% accuracy on 102 previously unseen objects. Our method demonstrates robustness to visual changes, such as distractors and new backgrounds, and easily adapts to new embodiments. Furthermore, DiffusionVLA can follow novel instructions and retain conversational ability. Notably, DiffusionVLA is data-efficient and fast at inference; our smallest DiffusionVLA-2B runs 82Hz on a single A6000 GPU and can train from scratch on less than 50 demonstrations for a complex task. Finally, we scale the model from 2B to 72B parameters, showcasing improved generalization capabilities with increased model size.
Student-Oriented Teacher Knowledge Refinement for Knowledge Distillation
Sep 27, 2024



Knowledge distillation has become widely recognized for its ability to transfer knowledge from a large teacher network to a compact and more streamlined student network. Traditional knowledge distillation methods primarily follow a teacher-oriented paradigm that imposes the task of learning the teacher's complex knowledge onto the student network. However, significant disparities in model capacity and architectural design hinder the student's comprehension of the complex knowledge imparted by the teacher, resulting in sub-optimal performance. This paper introduces a novel perspective emphasizing student-oriented and refining the teacher's knowledge to better align with the student's needs, thereby improving knowledge transfer effectiveness. Specifically, we present the Student-Oriented Knowledge Distillation (SoKD), which incorporates a learnable feature augmentation strategy during training to refine the teacher's knowledge of the student dynamically. Furthermore, we deploy the Distinctive Area Detection Module (DAM) to identify areas of mutual interest between the teacher and student, concentrating knowledge transfer within these critical areas to avoid transferring irrelevant information. This customized module ensures a more focused and effective knowledge distillation process. Our approach, functioning as a plug-in, could be integrated with various knowledge distillation methods. Extensive experimental results demonstrate the efficacy and generalizability of our method.