 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQMoP: Query Guided Mixture-of-Projector for Efficient Visual Token Compression
Mar 22, 2026Multimodal large language models suffer from severe computational and memory bottlenecks, as the number of visual tokens far exceeds that of textual tokens. While recent methods employ projector modules to align and compress visual tokens into text-aligned features, they typically depend on fixed heuristics that limit adaptability across diverse scenarios. In this paper, we first propose Query Guided Mixture-of-Projector (QMoP), a novel and flexible framework that adaptively compresses visual tokens via three collaborative branches: (1) a pooling-based branch for coarse-grained global semantics, (2) a resampler branch for extracting high-level semantic representations, and (3) a pruning-based branch for fine-grained token selection to preserve critical visual detail. To adaptively coordinate these branches, we introduce the Query Guided Router (QGR), which dynamically selects and weights the outputs from different branches based on both visual input and textual queries. A Mixture-of-Experts-style fusion mechanism is designed to aggregate the outputs, harnessing the strengths of each strategy while suppressing noise. To systematically evaluate the effects of Visual Token Compression, we also develop VTCBench, a dedicated benchmark for evaluating the information loss induced by visual token compression. Extensive experiments demonstrate that despite relying on fundamental compression modules, QMoP outperforms strong baselines and delivers significant savings in memory, computation, and inference time.
Frequency Error-Guided Under-sampling Optimization for Multi-Contrast MRI Reconstruction
Jan 14, 2026Magnetic resonance imaging (MRI) plays a vital role in clinical diagnostics, yet it remains hindered by long acquisition times and motion artifacts. Multi-contrast MRI reconstruction has emerged as a promising direction by leveraging complementary information from fully-sampled reference scans. However, existing approaches suffer from three major limitations: (1) superficial reference fusion strategies, such as simple concatenation, (2) insufficient utilization of the complementary information provided by the reference contrast, and (3) fixed under-sampling patterns. We propose an efficient and interpretable frequency error-guided reconstruction framework to tackle these issues. We first employ a conditional diffusion model to learn a Frequency Error Prior (FEP), which is then incorporated into a unified framework for jointly optimizing both the under-sampling pattern and the reconstruction network. The proposed reconstruction model employs a model-driven deep unfolding framework that jointly exploits frequency- and image-domain information. In addition, a spatial alignment module and a reference feature decomposition strategy are incorporated to improve reconstruction quality and bridge model-based optimization with data-driven learning for improved physical interpretability. Comprehensive validation across multiple imaging modalities, acceleration rates (4-30x), and sampling schemes demonstrates consistent superiority over state-of-the-art methods in both quantitative metrics and visual quality. All codes are available at https://github.com/fangxinming/JUF-MRI.
Mamba-Based Modality Disentanglement Network for Multi-Contrast MRI Reconstruction
Dec 22, 2025Magnetic resonance imaging (MRI) is a cornerstone of modern clinical diagnosis, offering unparalleled soft-tissue contrast without ionizing radiation. However, prolonged scan times remain a major barrier to patient throughput and comfort. Existing accelerated MRI techniques often struggle with two key challenges: (1) failure to effectively utilize inherent K-space prior information, leading to persistent aliasing artifacts from zero-filled inputs; and (2) contamination of target reconstruction quality by irrelevant information when employing multi-contrast fusion strategies. To overcome these challenges, we present MambaMDN, a dual-domain framework for multi-contrast MRI reconstruction. Our approach first employs fully-sampled reference K-space data to complete the undersampled target data, generating structurally aligned but modality-mixed inputs. Subsequently, we develop a Mamba-based modality disentanglement network to extract and remove reference-specific features from the mixed representation. Furthermore, we introduce an iterative refinement mechanism to progressively enhance reconstruction accuracy through repeated feature purification. Extensive experiments demonstrate that MambaMDN can significantly outperform existing multi-contrast reconstruction methods.
First-order State Space Model for Lightweight Image Super-resolution
Sep 10, 2025
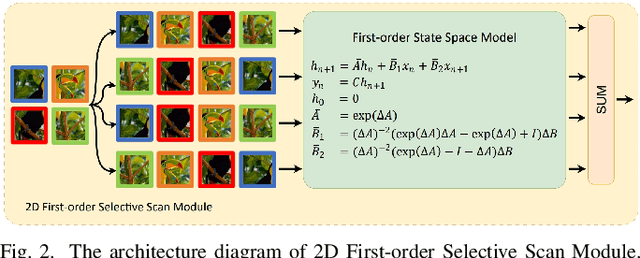
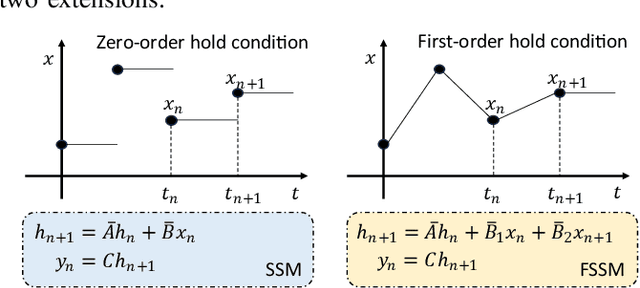

State space models (SSMs), particularly Mamba, have shown promise in NLP tasks and are increasingly applied to vision tasks. However, most Mamba-based vision models focus on network architecture and scan paths, with little attention to the SSM module. In order to explore the potential of SSMs, we modified the calculation process of SSM without increasing the number of parameters to improve the performance on lightweight super-resolution tasks. In this paper, we introduce the First-order State Space Model (FSSM) to improve the original Mamba module, enhancing performance by incorporating token correlations. We apply a first-order hold condition in SSMs, derive the new discretized form, and analyzed cumulative error. Extensive experimental results demonstrate that FSSM improves the performance of MambaIR on five benchmark datasets without additionally increasing the number of parameters, and surpasses current lightweight SR methods, achieving state-of-the-art results.
* Accept by ICASSP 2025 (Oral)
Harmonizing knowledge Transfer in Neural Network with Unified Distillation
Sep 27, 2024Knowledge distillation (KD), known for its ability to transfer knowledge from a cumbersome network (teacher) to a lightweight one (student) without altering the architecture, has been garnering increasing attention. Two primary categories emerge within KD methods: feature-based, focusing on intermediate layers' features, and logits-based, targeting the final layer's logits. This paper introduces a novel perspective by leveraging diverse knowledge sources within a unified KD framework. Specifically, we aggregate features from intermediate layers into a comprehensive representation, effectively gathering semantic information from different stages and scales. Subsequently, we predict the distribution parameters from this representation. These steps transform knowledge from the intermediate layers into corresponding distributive forms, thereby allowing for knowledge distillation through a unified distribution constraint at different stages of the network, ensuring the comprehensiveness and coherence of knowledge transfer. Numerous experiments were conducted to validate the effectiveness of the proposed method.
Student-Oriented Teacher Knowledge Refinement for Knowledge Distillation
Sep 27, 2024



Knowledge distillation has become widely recognized for its ability to transfer knowledge from a large teacher network to a compact and more streamlined student network. Traditional knowledge distillation methods primarily follow a teacher-oriented paradigm that imposes the task of learning the teacher's complex knowledge onto the student network. However, significant disparities in model capacity and architectural design hinder the student's comprehension of the complex knowledge imparted by the teacher, resulting in sub-optimal performance. This paper introduces a novel perspective emphasizing student-oriented and refining the teacher's knowledge to better align with the student's needs, thereby improving knowledge transfer effectiveness. Specifically, we present the Student-Oriented Knowledge Distillation (SoKD), which incorporates a learnable feature augmentation strategy during training to refine the teacher's knowledge of the student dynamically. Furthermore, we deploy the Distinctive Area Detection Module (DAM) to identify areas of mutual interest between the teacher and student, concentrating knowledge transfer within these critical areas to avoid transferring irrelevant information. This customized module ensures a more focused and effective knowledge distillation process. Our approach, functioning as a plug-in, could be integrated with various knowledge distillation methods. Extensive experimental results demonstrate the efficacy and generalizability of our method.
Three-Stage Cascade Framework for Blurry Video Frame Interpolation
Oct 09, 2023Blurry video frame interpolation (BVFI) aims to generate high-frame-rate clear videos from low-frame-rate blurry videos, is a challenging but important topic in the computer vision community. Blurry videos not only provide spatial and temporal information like clear videos, but also contain additional motion information hidden in each blurry frame. However, existing BVFI methods usually fail to fully leverage all valuable information, which ultimately hinders their performance. In this paper, we propose a simple end-to-end three-stage framework to fully explore useful information from blurry videos. The frame interpolation stage designs a temporal deformable network to directly sample useful information from blurry inputs and synthesize an intermediate frame at an arbitrary time interval. The temporal feature fusion stage explores the long-term temporal information for each target frame through a bi-directional recurrent deformable alignment network. And the deblurring stage applies a transformer-empowered Taylor approximation network to recursively recover the high-frequency details. The proposed three-stage framework has clear task assignment for each module and offers good expandability, the effectiveness of which are demonstrated by various experimental results. We evaluate our model on four benchmarks, including the Adobe240 dataset, GoPro dataset, YouTube240 dataset and Sony dataset. Quantitative and qualitative results indicate that our model outperforms existing SOTA methods. Besides, experiments on real-world blurry videos also indicate the good generalization ability of our model.
Deep Unfolding Convolutional Dictionary Model for Multi-Contrast MRI Super-resolution and Reconstruction
Sep 03, 2023Magnetic resonance imaging (MRI) tasks often involve multiple contrasts. Recently, numerous deep learning-based multi-contrast MRI super-resolution (SR) and reconstruction methods have been proposed to explore the complementary information from the multi-contrast images. However, these methods either construct parameter-sharing networks or manually design fusion rules, failing to accurately model the correlations between multi-contrast images and lacking certain interpretations. In this paper, we propose a multi-contrast convolutional dictionary (MC-CDic) model under the guidance of the optimization algorithm with a well-designed data fidelity term. Specifically, we bulid an observation model for the multi-contrast MR images to explicitly model the multi-contrast images as common features and unique features. In this way, only the useful information in the reference image can be transferred to the target image, while the inconsistent information will be ignored. We employ the proximal gradient algorithm to optimize the model and unroll the iterative steps into a deep CDic model. Especially, the proximal operators are replaced by learnable ResNet. In addition, multi-scale dictionaries are introduced to further improve the model performance. We test our MC-CDic model on multi-contrast MRI SR and reconstruction tasks. Experimental results demonstrate the superior performance of the proposed MC-CDic model against existing SOTA methods. Code is available at https://github.com/lpcccc-cv/MC-CDic.
CP$^3$: Channel Pruning Plug-in for Point-based Networks
Mar 23, 2023



Channel pruning can effectively reduce both computational cost and memory footprint of the original network while keeping a comparable accuracy performance. Though great success has been achieved in channel pruning for 2D image-based convolutional networks (CNNs), existing works seldom extend the channel pruning methods to 3D point-based neural networks (PNNs). Directly implementing the 2D CNN channel pruning methods to PNNs undermine the performance of PNNs because of the different representations of 2D images and 3D point clouds as well as the network architecture disparity. In this paper, we proposed CP$^3$, which is a Channel Pruning Plug-in for Point-based network. CP$^3$ is elaborately designed to leverage the characteristics of point clouds and PNNs in order to enable 2D channel pruning methods for PNNs. Specifically, it presents a coordinate-enhanced channel importance metric to reflect the correlation between dimensional information and individual channel features, and it recycles the discarded points in PNN's sampling process and reconsiders their potentially-exclusive information to enhance the robustness of channel pruning. Experiments on various PNN architectures show that CP$^3$ constantly improves state-of-the-art 2D CNN pruning approaches on different point cloud tasks. For instance, our compressed PointNeXt-S on ScanObjectNN achieves an accuracy of 88.52% with a pruning rate of 57.8%, outperforming the baseline pruning methods with an accuracy gain of 1.94%.
Flow Guidance Deformable Compensation Network for Video Frame Interpolation
Nov 22, 2022Motion-based video frame interpolation (VFI) methods have made remarkable progress with the development of deep convolutional networks over the past years. While their performance is often jeopardized by the inaccuracy of flow map estimation, especially in the case of large motion and occlusion. In this paper, we propose a flow guidance deformable compensation network (FGDCN) to overcome the drawbacks of existing motion-based methods. FGDCN decomposes the frame sampling process into two steps: a flow step and a deformation step. Specifically, the flow step utilizes a coarse-to-fine flow estimation network to directly estimate the intermediate flows and synthesizes an anchor frame simultaneously. To ensure the accuracy of the estimated flow, a distillation loss and a task-oriented loss are jointly employed in this step. Under the guidance of the flow priors learned in step one, the deformation step designs a pyramid deformable compensation network to compensate for the missing details of the flow step. In addition, a pyramid loss is proposed to supervise the model in both the image and frequency domain. Experimental results show that the proposed algorithm achieves excellent performance on various datasets with fewer parameters.