 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIVE: Structured Representation Integrating VLM Reasoning for Efficient Object Navigation
May 10, 2025



Vision-Language Models (VLMs) have been increasingly integrated into object navigation tasks for their rich prior knowledge and strong reasoning abilities. However, applying VLMs to navigation poses two key challenges: effectively representing complex environment information and determining \textit{when and how} to query VLMs. Insufficient environment understanding and over-reliance on VLMs (e.g. querying at every step) can lead to unnecessary backtracking and reduced navigation efficiency, especially in continuous environments. To address these challenges, we propose a novel framework that constructs a multi-layer representation of the environment during navigation. This representation consists of viewpoint, object nodes, and room nodes. Viewpoints and object nodes facilitate intra-room exploration and accurate target localization, while room nodes support efficient inter-room planning. Building on this representation, we propose a novel two-stage navigation policy, integrating high-level planning guided by VLM reasoning with low-level VLM-assisted exploration to efficiently locate a goal object. We evaluated our approach on three simulated benchmarks (HM3D, RoboTHOR, and MP3D), and achieved state-of-the-art performance on both the success rate ($\mathord{\uparrow}\, 7.1\%$) and navigation efficiency ($\mathord{\uparrow}\, 12.5\%$). We further validate our method on a real robot platform, demonstrating strong robustness across 15 object navigation tasks in 10 different indoor environments. Project page is available at https://zwandering.github.io/STRIVE.github.io/ .
MOSAIC: Generating Consistent, Privacy-Preserving Scenes from Multiple Depth Views in Multi-Room Environments
Mar 18, 2025We introduce a novel diffusion-based approach for generating privacy-preserving digital twins of multi-room indoor environments from depth images only. Central to our approach is a novel Multi-view Overlapped Scene Alignment with Implicit Consistency (MOSAIC) model that explicitly considers cross-view dependencies within the same scene in the probabilistic sense. MOSAIC operates through a novel inference-time optimization that avoids error accumulation common in sequential or single-room constraint in panorama-based approaches. MOSAIC scales to complex scenes with zero extra training and provably reduces the variance during denoising processes when more overlapping views are added, leading to improved generation quality. Experiments show that MOSAIC outperforms state-of-the-art baselines on image fidelity metrics in reconstructing complex multi-room environments. Project page is available at: https://mosaic-cmubig.github.io
Student-Oriented Teacher Knowledge Refinement for Knowledge Distillation
Sep 27, 2024



Knowledge distillation has become widely recognized for its ability to transfer knowledge from a large teacher network to a compact and more streamlined student network. Traditional knowledge distillation methods primarily follow a teacher-oriented paradigm that imposes the task of learning the teacher's complex knowledge onto the student network. However, significant disparities in model capacity and architectural design hinder the student's comprehension of the complex knowledge imparted by the teacher, resulting in sub-optimal performance. This paper introduces a novel perspective emphasizing student-oriented and refining the teacher's knowledge to better align with the student's needs, thereby improving knowledge transfer effectiveness. Specifically, we present the Student-Oriented Knowledge Distillation (SoKD), which incorporates a learnable feature augmentation strategy during training to refine the teacher's knowledge of the student dynamically. Furthermore, we deploy the Distinctive Area Detection Module (DAM) to identify areas of mutual interest between the teacher and student, concentrating knowledge transfer within these critical areas to avoid transferring irrelevant information. This customized module ensures a more focused and effective knowledge distillation process. Our approach, functioning as a plug-in, could be integrated with various knowledge distillation methods. Extensive experimental results demonstrate the efficacy and generalizability of our method.
M3DM-NR: RGB-3D Noisy-Resistant Industrial Anomaly Detection via Multimodal Denoising
Jun 04, 2024Existing industrial anomaly detection methods primarily concentrate on unsupervised learning with pristine RGB images. Yet, both RGB and 3D data are crucial for anomaly detection, and the datasets are seldom completely clean in practical scenarios. To address above challenges, this paper initially delves into the RGB-3D multi-modal noisy anomaly detection, proposing a novel noise-resistant M3DM-NR framework to leveraging strong multi-modal discriminative capabilities of CLIP. M3DM-NR consists of three stages: Stage-I introduces the Suspected References Selection module to filter a few normal samples from the training dataset, using the multimodal features extracted by the Initial Feature Extraction, and a Suspected Anomaly Map Computation module to generate a suspected anomaly map to focus on abnormal regions as reference. Stage-II uses the suspected anomaly maps of the reference samples as reference, and inputs image, point cloud, and text information to achieve denoising of the training samples through intra-modal comparison and multi-scale aggregation operations. Finally, Stage-III proposes the Point Feature Alignment, Unsupervised Feature Fusion, Noise Discriminative Coreset Selection, and Decision Layer Fusion modules to learn the pattern of the training dataset, enabling anomaly detection and segmentation while filtering out noise. Extensive experiments show that M3DM-NR outperforms state-of-the-art methods in 3D-RGB multi-modal noisy anomaly detection.
SAMVG: A Multi-stage Image Vectorization Model with the Segment-Anything Model
Nov 09, 2023


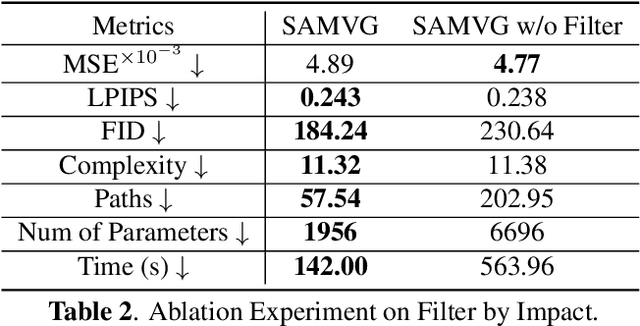
Vector graphics are widely used in graphical designs and have received more and more attention. However, unlike raster images which can be easily obtained, acquiring high-quality vector graphics, typically through automatically converting from raster images remains a significant challenge, especially for more complex images such as photos or artworks. In this paper, we propose SAMVG, a multi-stage model to vectorize raster images into SVG (Scalable Vector Graphics). Firstly, SAMVG uses general image segmentation provided by the Segment-Anything Model and uses a novel filtering method to identify the best dense segmentation map for the entire image. Secondly, SAMVG then identifies missing components and adds more detailed components to the SVG. Through a series of extensive experiments, we demonstrate that SAMVG can produce high quality SVGs in any domain while requiring less computation time and complexity compared to previous state-of-the-art methods.
Stroke-based Neural Painting and Stylization with Dynamically Predicted Painting Region
Sep 07, 2023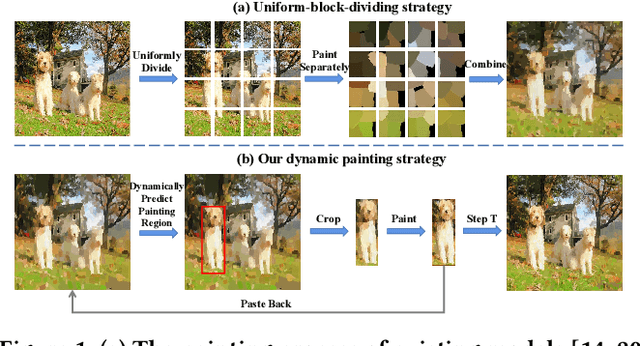


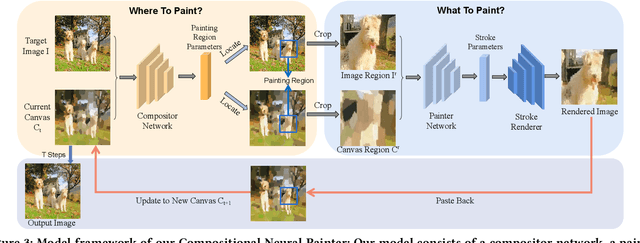
Stroke-based rendering aims to recreate an image with a set of strokes. Most existing methods render complex images using an uniform-block-dividing strategy, which leads to boundary inconsistency artifacts. To solve the problem, we propose Compositional Neural Painter, a novel stroke-based rendering framework which dynamically predicts the next painting region based on the current canvas, instead of dividing the image plane uniformly into painting regions. We start from an empty canvas and divide the painting process into several steps. At each step, a compositor network trained with a phasic RL strategy first predicts the next painting region, then a painter network trained with a WGAN discriminator predicts stroke parameters, and a stroke renderer paints the strokes onto the painting region of the current canvas. Moreover, we extend our method to stroke-based style transfer with a novel differentiable distance transform loss, which helps preserve the structure of the input image during stroke-based stylization. Extensive experiments show our model outperforms the existing models in both stroke-based neural painting and stroke-based stylization. Code is available at https://github.com/sjtuplayer/Compositional_Neural_Painter
Phasic Content Fusing Diffusion Model with Directional Distribution Consistency for Few-Shot Model Adaption
Sep 07, 2023Training a generative model with limited number of samples is a challenging task. Current methods primarily rely on few-shot model adaption to train the network. However, in scenarios where data is extremely limited (less than 10), the generative network tends to overfit and suffers from content degradation. To address these problems, we propose a novel phasic content fusing few-shot diffusion model with directional distribution consistency loss, which targets different learning objectives at distinct training stages of the diffusion model. Specifically, we design a phasic training strategy with phasic content fusion to help our model learn content and style information when t is large, and learn local details of target domain when t is small, leading to an improvement in the capture of content, style and local details. Furthermore, we introduce a novel directional distribution consistency loss that ensures the consistency between the generated and source distributions more efficiently and stably than the prior methods, preventing our model from overfitting. Finally, we propose a cross-domain structure guidance strategy that enhances structure consistency during domain adaptation. Theoretical analysis, qualitative and quantitative experiments demonstrate the superiority of our approach in few-shot generative model adaption tasks compared to state-of-the-art methods. The source code is available at: https://github.com/sjtuplayer/few-shot-diffusion.