 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
SRU-Pix2Pix: A Fusion-Driven Generator Network for Medical Image Translation with Few-Shot Learning
Jan 08, 2026Magnetic Resonance Imaging (MRI) provides detailed tissue information, but its clinical application is limited by long acquisition time, high cost, and restricted resolution. Image translation has recently gained attention as a strategy to address these limitations. Although Pix2Pix has been widely applied in medical image translation, its potential has not been fully explored. In this study, we propose an enhanced Pix2Pix framework that integrates Squeeze-and-Excitation Residual Networks (SEResNet) and U-Net++ to improve image generation quality and structural fidelity. SEResNet strengthens critical feature representation through channel attention, while U-Net++ enhances multi-scale feature fusion. A simplified PatchGAN discriminator further stabilizes training and refines local anatomical realism. Experimental results demonstrate that under few-shot conditions with fewer than 500 images, the proposed method achieves consistent structural fidelity and superior image quality across multiple intra-modality MRI translation tasks, showing strong generalization ability. These results suggest an effective extension of Pix2Pix for medical image translation.
Covariance-based Imaging and Multi-View Fusion for Networked Sensing
Nov 18, 2025This paper considers multi-view imaging in a sixth-generation (6G) integrated sensing and communication network, which consists of a transmit base-station (BS), multiple receive BSs connected to a central processing unit (CPU), and multiple extended targets. Our goal is to devise an effective multi-view imaging technique that can jointly leverage the targets' echo signals at all the receive BSs to precisely construct the image of these targets. To achieve this goal, we propose a two-phase approach. In Phase I, each receive BS recovers an individual image based on the sample covariance matrix of its received signals. Specifically, we propose a novel covariance-based imaging framework to jointly estimate effective scattering intensity and grid positions, which reduces the number of estimated parameters leveraging channel statistical properties and allows grid adjustment to conform to target geometry. In Phase II, the CPU fuses the individual images of all the receivers to construct a high-quality image of all the targets. Specifically, we design edge-preserving natural neighbor interpolation (EP-NNI) to map individual heterogeneous images onto common and finer grids, and then propose a joint optimization framework to estimate fused scattering intensity and BS fields of view. Extensive numerical results show that the proposed scheme significantly enhances imaging performance, facilitating high-quality environment reconstruction for future 6G networks.
Integrated Massive Communication and Target Localization in 6G Cell-Free Networks
Oct 16, 2025This paper presents an initial investigation into the combination of integrated sensing and communication (ISAC) and massive communication, both of which are largely regarded as key scenarios in sixth-generation (6G) wireless networks. Specifically, we consider a cell-free network comprising a large number of users, multiple targets, and distributed base stations (BSs). In each time slot, a random subset of users becomes active, transmitting pilot signals that can be scattered by the targets before reaching the BSs. Unlike conventional massive random access schemes, where the primary objectives are device activity detection and channel estimation, our framework also enables target localization by leveraging the multipath propagation effects introduced by the targets. However, due to the intricate dependency between user channels and target locations, characterizing the posterior distribution required for minimum mean-square error (MMSE) estimation presents significant computational challenges. To handle this problem, we propose a hybrid message passing-based framework that incorporates multiple approximations to mitigate computational complexity. Numerical results demonstrate that the proposed approach achieves high-accuracy device activity detection, channel estimation, and target localization simultaneously, validating the feasibility of embedding localization functionality into massive communication systems for future 6G networks.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Serendipitous Recommendation with Multimodal LLM
Jun 09, 2025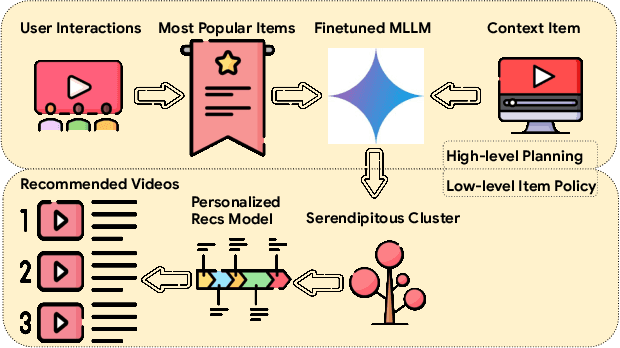
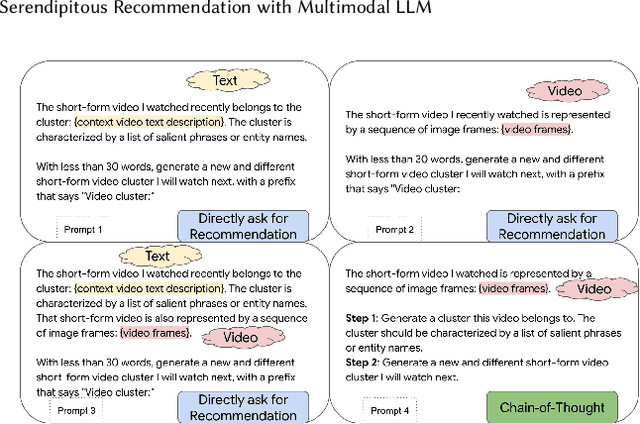
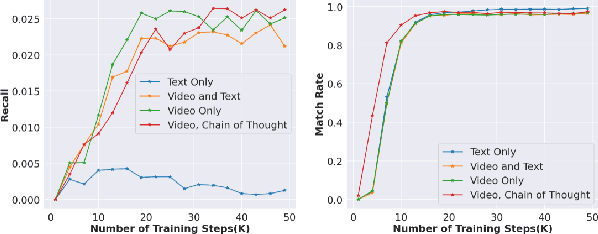
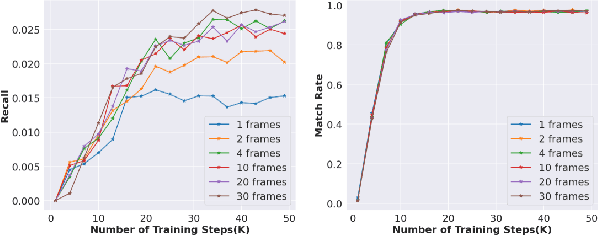
Conventional recommendation systems succeed in identifying relevant content but often fail to provide users with surprising or novel items. Multimodal Large Language Models (MLLMs) possess the world knowledge and multimodal understanding needed for serendipity, but their integration into billion-item-scale platforms presents significant challenges. In this paper, we propose a novel hierarchical framework where fine-tuned MLLMs provide high-level guidance to conventional recommendation models, steering them towards more serendipitous suggestions. This approach leverages MLLM strengths in understanding multimodal content and user interests while retaining the efficiency of traditional models for item-level recommendation. This mitigates the complexity of applying MLLMs directly to vast action spaces. We also demonstrate a chain-of-thought strategy enabling MLLMs to discover novel user interests by first understanding video content and then identifying relevant yet unexplored interest clusters. Through live experiments within a commercial short-form video platform serving billions of users, we show that our MLLM-powered approach significantly improves both recommendation serendipity and user satisfaction.
UI-Genie: A Self-Improving Approach for Iteratively Boosting MLLM-based Mobile GUI Agents
May 27, 2025In this paper, we introduce UI-Genie, a self-improving framework addressing two key challenges in GUI agents: verification of trajectory outcome is challenging and high-quality training data are not scalable. These challenges are addressed by a reward model and a self-improving pipeline, respectively. The reward model, UI-Genie-RM, features an image-text interleaved architecture that efficiently pro- cesses historical context and unifies action-level and task-level rewards. To sup- port the training of UI-Genie-RM, we develop deliberately-designed data genera- tion strategies including rule-based verification, controlled trajectory corruption, and hard negative mining. To address the second challenge, a self-improvement pipeline progressively expands solvable complex GUI tasks by enhancing both the agent and reward models through reward-guided exploration and outcome verification in dynamic environments. For training the model, we generate UI- Genie-RM-517k and UI-Genie-Agent-16k, establishing the first reward-specific dataset for GUI agents while demonstrating high-quality synthetic trajectory gen- eration without manual annotation. Experimental results show that UI-Genie achieves state-of-the-art performance across multiple GUI agent benchmarks with three generations of data-model self-improvement. We open-source our complete framework implementation and generated datasets to facilitate further research in https://github.com/Euphoria16/UI-Genie.
Scalable Transceiver Design for Multi-User Communication in FDD Massive MIMO Systems via Deep Learning
Apr 15, 2025This paper addresses the joint transceiver design, including pilot transmission, channel feature extraction and feedback, as well as precoding, for low-overhead downlink massive multiple-input multiple-output (MIMO) communication in frequency-division duplex (FDD) systems. Although deep learning (DL) has shown great potential in tackling this problem, existing methods often suffer from poor scalability in practical systems, as the solution obtained in the training phase merely works for a fixed feedback capacity and a fixed number of users in the deployment phase. To address this limitation, we propose a novel DL-based framework comprised of choreographed neural networks, which can utilize one training phase to generate all the transceiver solutions used in the deployment phase with varying sizes of feedback codebooks and numbers of users. The proposed framework includes a residual vector-quantized variational autoencoder (RVQ-VAE) for efficient channel feedback and an edge graph attention network (EGAT) for robust multiuser precoding. It can adapt to different feedback capacities by flexibly adjusting the RVQ codebook sizes using the hierarchical codebook structure, and scale with the number of users through a feedback module sharing scheme and the inherent scalability of EGAT. Moreover, a progressive training strategy is proposed to further enhance data transmission performance and generalization capability. Numerical results on a real-world dataset demonstrate the superior scalability and performance of our approach over existing methods.
Low-Overhead Channel Estimation Framework for Beyond Diagonal Reconfigurable Intelligent Surface Assisted Multi-User MIMO Communication
Apr 15, 2025Beyond diagonal reconfigurable intelligent surface (BD-RIS) refers to a family of RIS architectures characterized by scattering matrices not limited to being diagonal and enables higher wave manipulation flexibility and large performance gains over conventional (diagonal) RIS. To achieve those promising gains, accurate channel state information (CSI) needs to be acquired in BD-RIS assisted communication systems. However, the number of coefficients in the cascaded channels to be estimated in BD-RIS assisted systems is significantly larger than that in conventional RIS assisted systems, because the channels associated with the off-diagonal elements of the scattering matrix have to be estimated as well. Surprisingly, for the first time in the literature, this paper rigorously shows that the uplink channel estimation overhead in BD-RIS assisted systems is actually of the same order as that in the conventional RIS assisted systems. This amazing result stems from a key observation: for each user antenna, its cascaded channel matrix associated with one reference BD-RIS element is a scaled version of that associated with any other BD-RIS element due to the common RIS-base station (BS) channel. In other words, the number of independent unknown variables is far less than it would seem at first glance. Building upon this property, this paper manages to characterize the minimum overhead to perfectly estimate all the channels in the ideal case without noise at the BS, and propose a twophase estimation framework for the practical case with noise at the BS. Numerical results demonstrate outstanding channel estimation overhead reduction over existing schemes in BD-RIS assisted systems.