 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Attention-Based Model for 5G Radio-based Outdoor Localization
Mar 31, 2025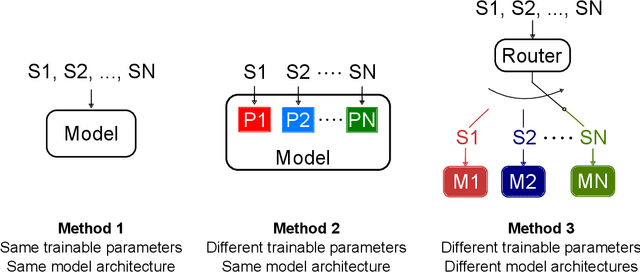
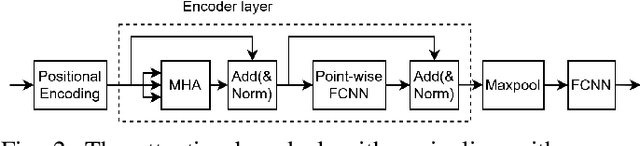
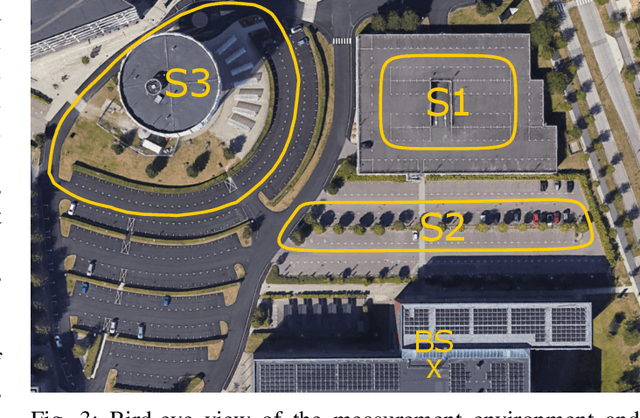
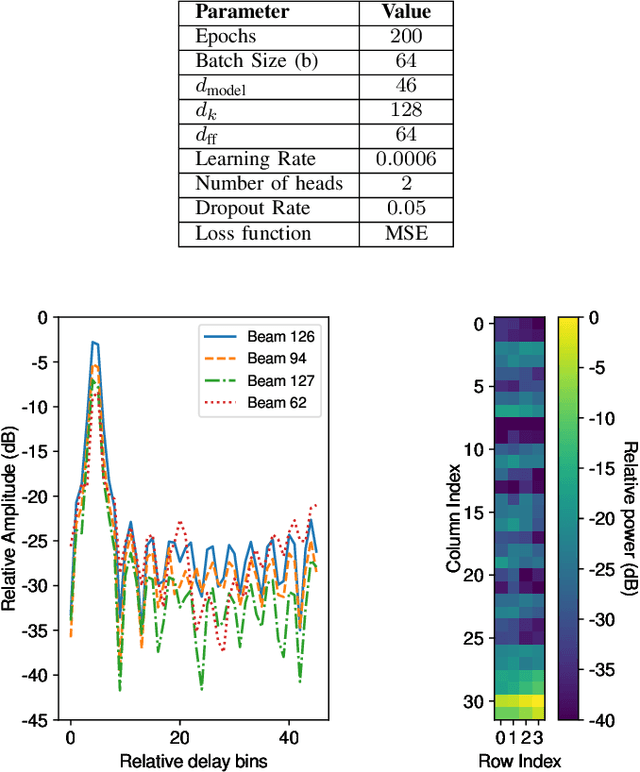
Radio-based localization in dynamic environments, such as urban and vehicular settings, requires systems that can efficiently adapt to varying signal conditions and environmental changes. Factors such as multipath interference and obstructions introduce different levels of complexity that affect the accuracy of the localization. Although generalized models offer broad applicability, they often struggle to capture the nuances of specific environments, leading to suboptimal performance in real-world deployments. In contrast, specialized models can be tailored to particular conditions, enabling more precise localization by effectively handling domain-specific variations and noise patterns. However, deploying multiple specialized models requires an efficient mechanism to select the most appropriate one for a given scenario. In this work, we develop an adaptive localization framework that combines shallow attention-based models with a router/switching mechanism based on a single-layer perceptron (SLP). This enables seamless transitions between specialized localization models optimized for different conditions, balancing accuracy, computational efficiency, and robustness to environmental variations. We design three low-complex localization models tailored for distinct scenarios, optimized for reduced computational complexity, test time, and model size. The router dynamically selects the most suitable model based on real-time input characteristics. The proposed framework is validated using real-world vehicle localization data collected from a massive MIMO base station (BS), demonstrating its ability to seamlessly adapt to diverse deployment conditions while maintaining high localization accuracy.
SteROI-D: System Design and Mapping for Stereo Depth Inference on Regions of Interest
Feb 13, 2025



Machine learning algorithms have enabled high quality stereo depth estimation to run on Augmented and Virtual Reality (AR/VR) devices. However, high energy consumption across the full image processing stack prevents stereo depth algorithms from running effectively on battery-limited devices. This paper introduces SteROI-D, a full stereo depth system paired with a mapping methodology. SteROI-D exploits Region-of-Interest (ROI) and temporal sparsity at the system level to save energy. SteROI-D's flexible and heterogeneous compute fabric supports diverse ROIs. Importantly, we introduce a systematic mapping methodology to effectively handle dynamic ROIs, thereby maximizing energy savings. Using these techniques, our 28nm prototype SteROI-D design achieves up to 4.35x reduction in total system energy compared to a baseline ASIC.
Panacea: Novel DNN Accelerator using Accuracy-Preserving Asymmetric Quantization and Energy-Saving Bit-Slice Sparsity
Dec 13, 2024



Low bit-precisions and their bit-slice sparsity have recently been studied to accelerate general matrix-multiplications (GEMM) during large-scale deep neural network (DNN) inferences. While the conventional symmetric quantization facilitates low-resolution processing with bit-slice sparsity for both weight and activation, its accuracy loss caused by the activation's asymmetric distributions cannot be acceptable, especially for large-scale DNNs. In efforts to mitigate this accuracy loss, recent studies have actively utilized asymmetric quantization for activations without requiring additional operations. However, the cutting-edge asymmetric quantization produces numerous nonzero slices that cannot be compressed and skipped by recent bit-slice GEMM accelerators, naturally consuming more processing energy to handle the quantized DNN models. To simultaneously achieve high accuracy and hardware efficiency for large-scale DNN inferences, this paper proposes an Asymmetrically-Quantized bit-Slice GEMM (AQS-GEMM) for the first time. In contrast to the previous bit-slice computing, which only skips operations of zero slices, the AQS-GEMM compresses frequent nonzero slices, generated by asymmetric quantization, and skips their operations. To increase the slice-level sparsity of activations, we also introduce two algorithm-hardware co-optimization methods: a zero-point manipulation and a distribution-based bit-slicing. To support the proposed AQS-GEMM and optimizations at the hardware-level, we newly introduce a DNN accelerator, Panacea, which efficiently handles sparse/dense workloads of the tiled AQS-GEMM to increase data reuse and utilization. Panacea supports a specialized dataflow and run-length encoding to maximize data reuse and minimize external memory accesses, significantly improving its hardware efficiency. Our benchmark evaluations show Panacea outperforms existing DNN accelerators.
HiMA: A Fast and Scalable History-based Memory Access Engine for Differentiable Neural Computer
Feb 15, 2022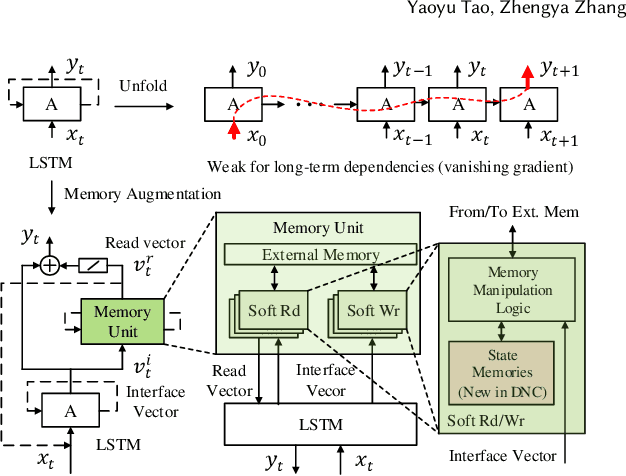
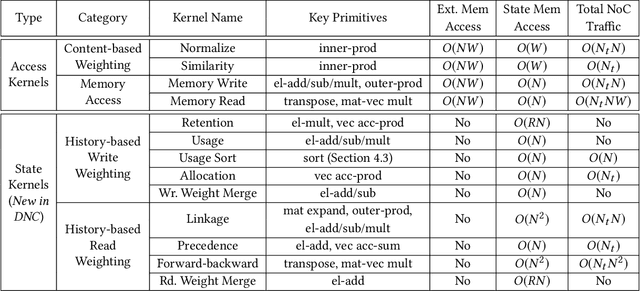
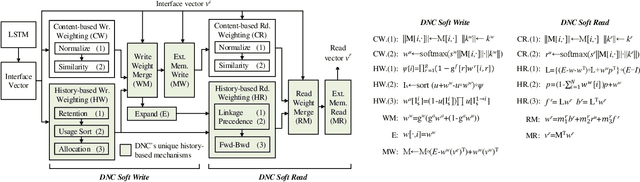
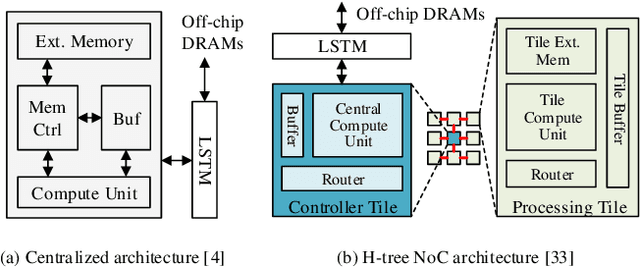
Memory-augmented neural networks (MANNs) provide better inference performance in many tasks with the help of an external memory. The recently developed differentiable neural computer (DNC) is a MANN that has been shown to outperform in representing complicated data structures and learning long-term dependencies. DNC's higher performance is derived from new history-based attention mechanisms in addition to the previously used content-based attention mechanisms. History-based mechanisms require a variety of new compute primitives and state memories, which are not supported by existing neural network (NN) or MANN accelerators. We present HiMA, a tiled, history-based memory access engine with distributed memories in tiles. HiMA incorporates a multi-mode network-on-chip (NoC) to reduce the communication latency and improve scalability. An optimal submatrix-wise memory partition strategy is applied to reduce the amount of NoC traffic; and a two-stage usage sort method leverages distributed tiles to improve computation speed. To make HiMA fundamentally scalable, we create a distributed version of DNC called DNC-D to allow almost all memory operations to be applied to local memories with trainable weighted summation to produce the global memory output. Two approximation techniques, usage skimming and softmax approximation, are proposed to further enhance hardware efficiency. HiMA prototypes are created in RTL and synthesized in a 40nm technology. By simulations, HiMA running DNC and DNC-D demonstrates 6.47x and 39.1x higher speed, 22.8x and 164.3x better area efficiency, and 6.1x and 61.2x better energy efficiency over the state-of-the-art MANN accelerator. Compared to an Nvidia 3080Ti GPU, HiMA demonstrates speedup by up to 437x and 2,646x when running DNC and DNC-D, respectively.
DNC-Aided SCL-Flip Decoding of Polar Codes
Jan 26, 2021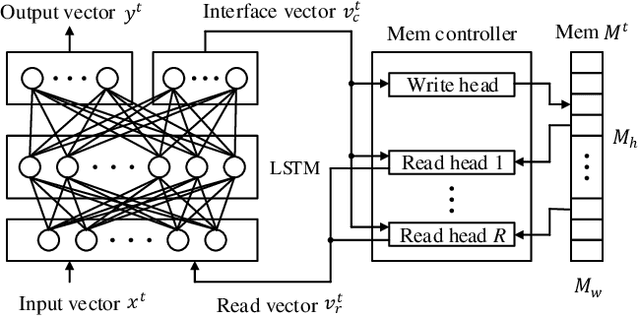
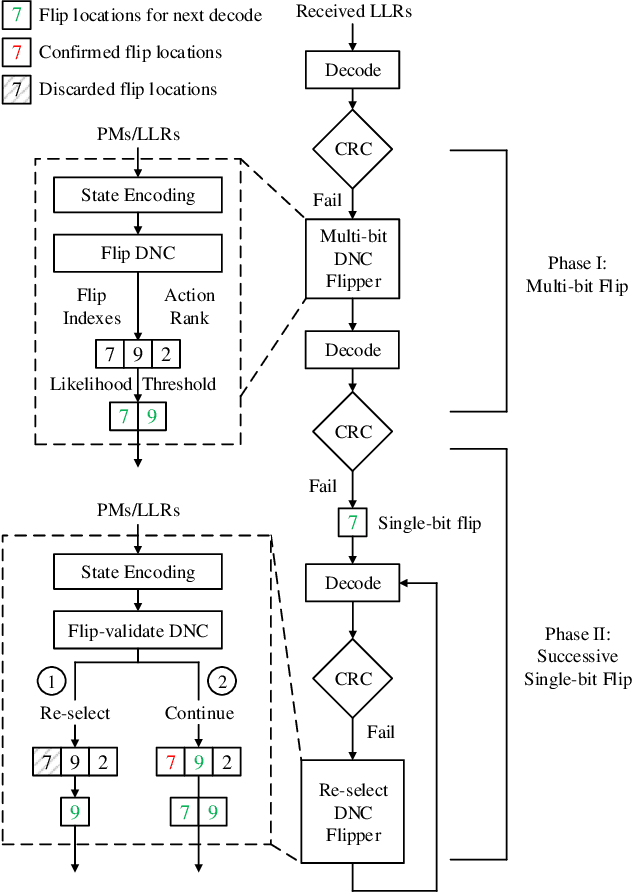
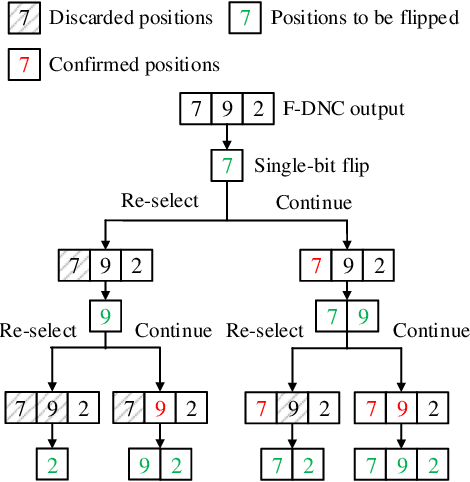
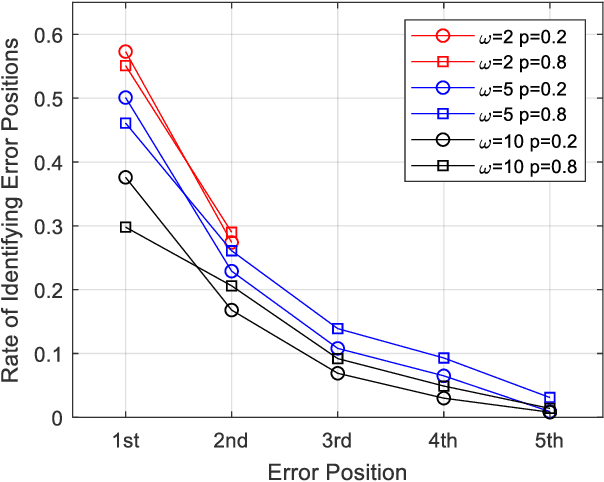
Successive-cancellation list (SCL) decoding of polar codes is promising towards practical adoptions. However, the performance is not satisfactory with moderate code length. Variety of flip algorithms are developed to solve this problem. The key for successful flip is to accurately identify error bit positions. However, state-of-the-art flip strategies, including heuristic and deep-learning-aided (DL-aided) approaches, are not effective in handling long-distance dependencies in sequential SCL decoding. In this work, we propose a new DNC-aided flip decoding with differentiable neural computer (DNC). New action and state encoding are developed for better training and inference efficiency. The proposed method consists of two phases: i) a flip DNC (F-DNC) is exploited to rank most likely flip positions for multi-bit flipping; ii) if multi-bit flipping fails, a flip-validate DNC (FV-DNC) is used to re-select error position and assist single-bit flipping successively. Training methods are designed accordingly for the two DNCs. Simulation results show that proposed DNC-aided SCL-Flip (DNC-SCLF) decoding can effectively improve the error-correction performance and reduce number of decoding attempts compared to prior works.
Field-Programmable Crossbar Array (FPCA) for Reconfigurable Computing
Jul 20, 2017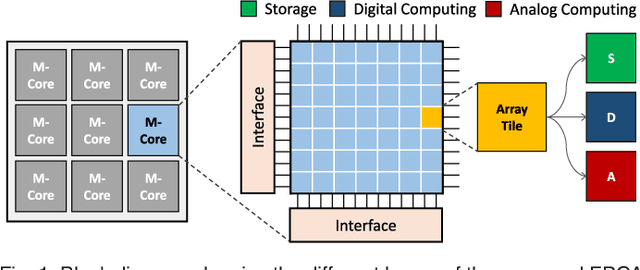
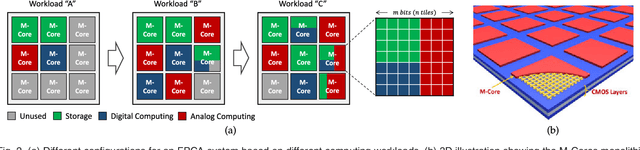
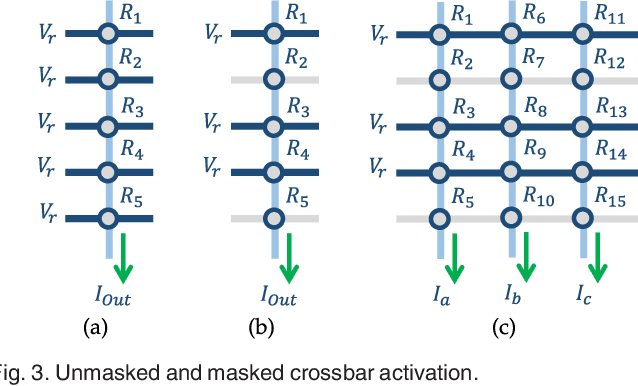
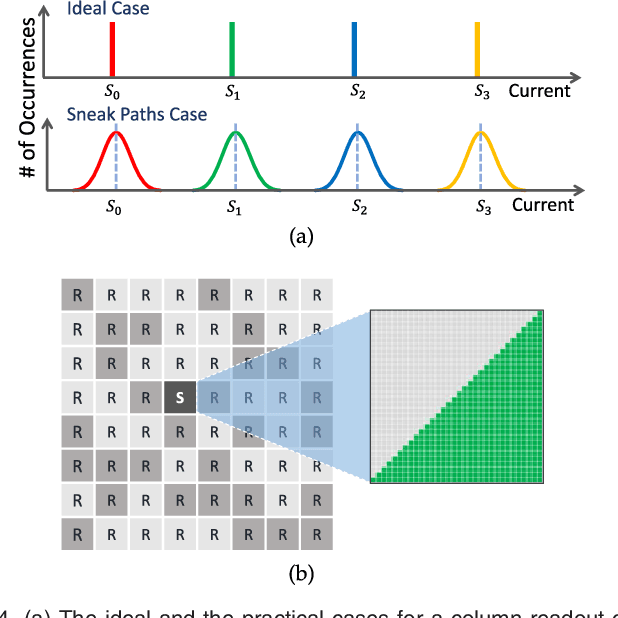
For decades, advances in electronics were directly driven by the scaling of CMOS transistors according to Moore's law. However, both the CMOS scaling and the classical computer architecture are approaching fundamental and practical limits, and new computing architectures based on emerging devices, such as resistive random-access memory (RRAM) devices, are expected to sustain the exponential growth of computing capability. Here we propose a novel memory-centric, reconfigurable, general purpose computing platform that is capable of handling the explosive amount of data in a fast and energy-efficient manner. The proposed computing architecture is based on a uniform, physical, resistive, memory-centric fabric that can be optimally reconfigured and utilized to perform different computing and data storage tasks in a massively parallel approach. The system can be tailored to achieve maximal energy efficiency based on the data flow by dynamically allocating the basic computing fabric for storage, arithmetic, and analog computing including neuromorphic computing tasks.