 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteROI-D: System Design and Mapping for Stereo Depth Inference on Regions of Interest
Feb 13, 2025



Machine learning algorithms have enabled high quality stereo depth estimation to run on Augmented and Virtual Reality (AR/VR) devices. However, high energy consumption across the full image processing stack prevents stereo depth algorithms from running effectively on battery-limited devices. This paper introduces SteROI-D, a full stereo depth system paired with a mapping methodology. SteROI-D exploits Region-of-Interest (ROI) and temporal sparsity at the system level to save energy. SteROI-D's flexible and heterogeneous compute fabric supports diverse ROIs. Importantly, we introduce a systematic mapping methodology to effectively handle dynamic ROIs, thereby maximizing energy savings. Using these techniques, our 28nm prototype SteROI-D design achieves up to 4.35x reduction in total system energy compared to a baseline ASIC.
Distributed On-Sensor Compute System for AR/VR Devices: A Semi-Analytical Simulation Framework for Power Estimation
Mar 14, 2022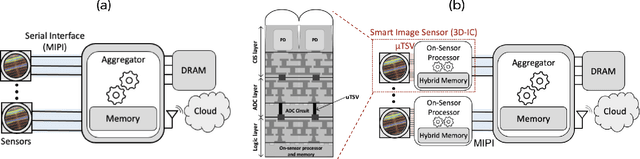
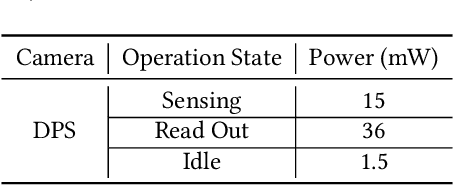


Augmented Reality/Virtual Reality (AR/VR) glasses are widely foreseen as the next generation computing platform. AR/VR glasses are a complex "system of systems" which must satisfy stringent form factor, computing-, power- and thermal- requirements. In this paper, we will show that a novel distributed on-sensor compute architecture, coupled with new semiconductor technologies (such as dense 3D-IC interconnects and Spin-Transfer Torque Magneto Random Access Memory, STT-MRAM) and, most importantly, a full hardware-software co-optimization are the solutions to achieve attractive and socially acceptable AR/VR glasses. To this end, we developed a semi-analytical simulation framework to estimate the power consumption of novel AR/VR distributed on-sensor computing architectures. The model allows the optimization of the main technological features of the system modules, as well as the computer-vision algorithm partition strategy across the distributed compute architecture. We show that, in the case of the compute-intensive machine learning based Hand Tracking algorithm, the distributed on-sensor compute architecture can reduce the system power consumption compared to a centralized system, with the additional benefits in terms of latency and privacy.
LiveView: Dynamic Target-Centered MPI for View Synthesis
Jul 11, 2021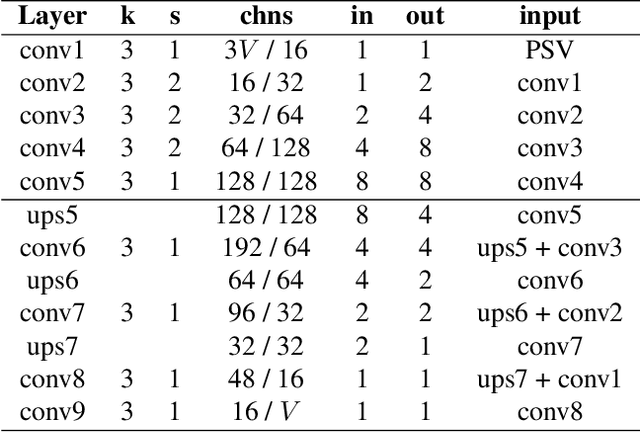
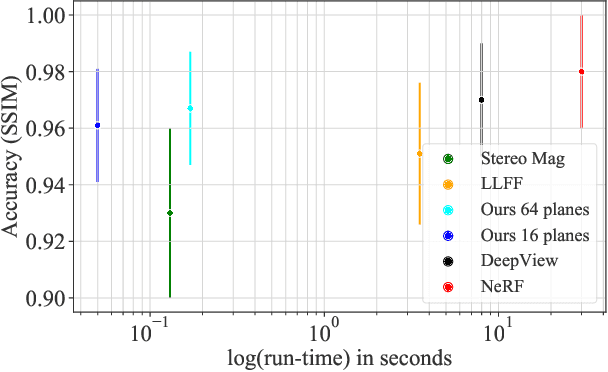
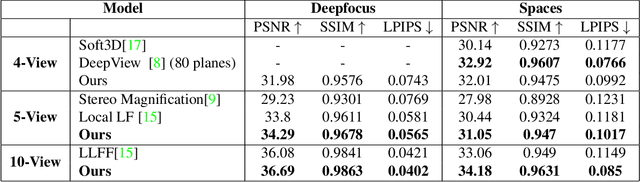
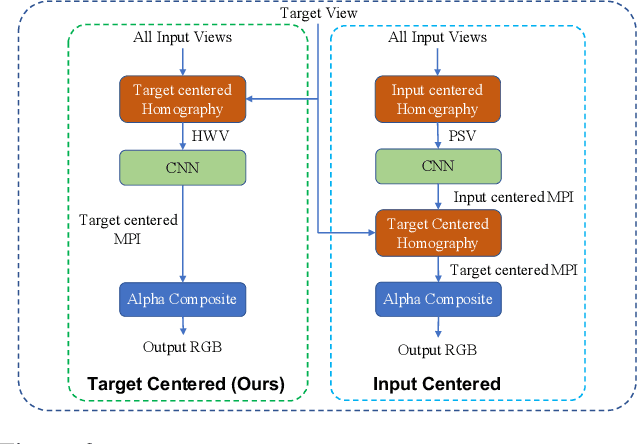
Existing Multi-Plane Image (MPI) based view-synthesis methods generate an MPI aligned with the input view using a fixed number of planes in one forward pass. These methods produce fast, high-quality rendering of novel views, but rely on slow and computationally expensive MPI generation methods unsuitable for real-time applications. In addition, most MPI techniques use fixed depth/disparity planes which cannot be modified once the training is complete, hence offering very little flexibility at run-time. We propose LiveView - a novel MPI generation and rendering technique that produces high-quality view synthesis in real-time. Our method can also offer the flexibility to select scene-dependent MPI planes (number of planes and spacing between them) at run-time. LiveView first warps input images to target view (target-centered) and then learns to generate a target view centered MPI, one depth plane at a time (dynamically). The method generates high-quality renderings, while also enabling fast MPI generation and novel view synthesis. As a result, LiveView enables real-time view synthesis applications where an MPI needs to be updated frequently based on a video stream of input views. We demonstrate that LiveView improves the quality of view synthesis while being 70 times faster at run-time compared to state-of-the-art MPI-based methods.