 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveView: Dynamic Target-Centered MPI for View Synthesis
Jul 11, 2021
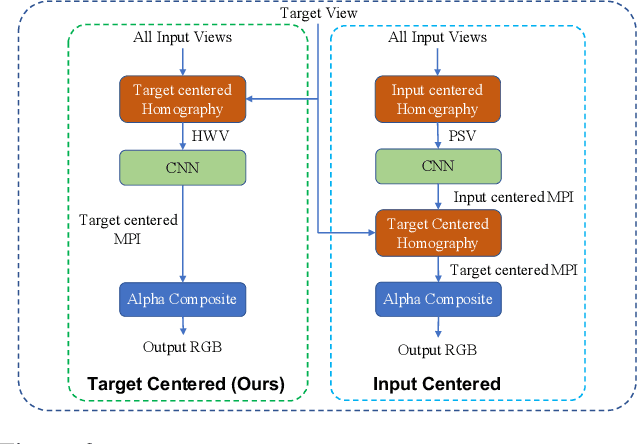
Existing Multi-Plane Image (MPI) based view-synthesis methods generate an MPI aligned with the input view using a fixed number of planes in one forward pass. These methods produce fast, high-quality rendering of novel views, but rely on slow and computationally expensive MPI generation methods unsuitable for real-time applications. In addition, most MPI techniques use fixed depth/disparity planes which cannot be modified once the training is complete, hence offering very little flexibility at run-time. We propose LiveView - a novel MPI generation and rendering technique that produces high-quality view synthesis in real-time. Our method can also offer the flexibility to select scene-dependent MPI planes (number of planes and spacing between them) at run-time. LiveView first warps input images to target view (target-centered) and then learns to generate a target view centered MPI, one depth plane at a time (dynamically). The method generates high-quality renderings, while also enabling fast MPI generation and novel view synthesis. As a result, LiveView enables real-time view synthesis applications where an MPI needs to be updated frequently based on a video stream of input views. We demonstrate that LiveView improves the quality of view synthesis while being 70 times faster at run-time compared to state-of-the-art MPI-based methods.
Bridging the Gap Between Computational Photography and Visual Recognition
Jan 28, 2019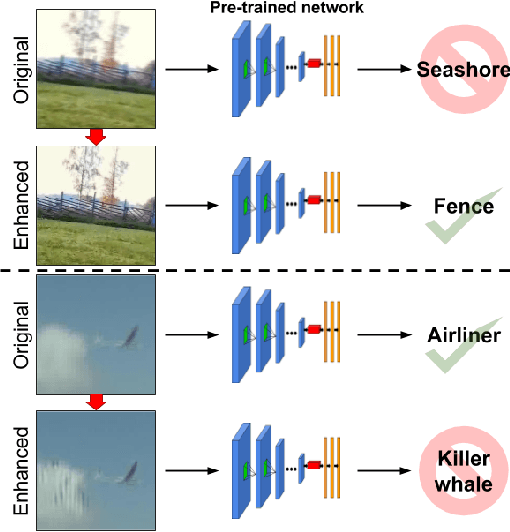
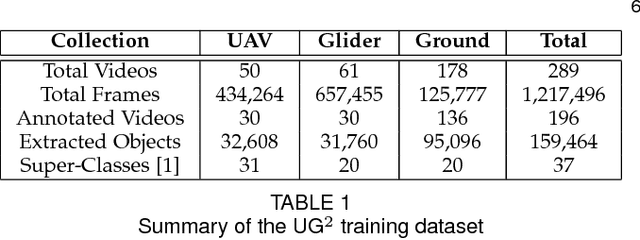

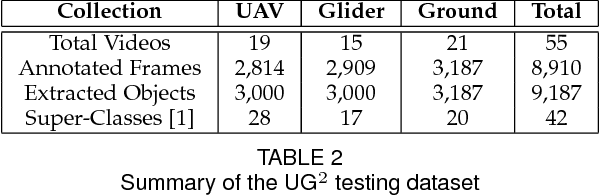
What is the current state-of-the-art for image restoration and enhancement applied to degraded images acquired under less than ideal circumstances? Can the application of such algorithms as a pre-processing step to improve image interpretability for manual analysis or automatic visual recognition to classify scene content? While there have been important advances in the area of computational photography to restore or enhance the visual quality of an image, the capabilities of such techniques have not always translated in a useful way to visual recognition tasks. Consequently, there is a pressing need for the development of algorithms that are designed for the joint problem of improving visual appearance and recognition, which will be an enabling factor for the deployment of visual recognition tools in many real-world scenarios. To address this, we introduce the UG^2 dataset as a large-scale benchmark composed of video imagery captured under challenging conditions, and two enhancement tasks designed to test algorithmic impact on visual quality and automatic object recognition. Furthermore, we propose a set of metrics to evaluate the joint improvement of such tasks as well as individual algorithmic advances, including a novel psychophysics-based evaluation regime for human assessment and a realistic set of quantitative measures for object recognition performance. We introduce six new algorithms for image restoration or enhancement, which were created as part of the IARPA sponsored UG^2 Challenge workshop held at CVPR 2018. Under the proposed evaluation regime, we present an in-depth analysis of these algorithms and a host of deep learning-based and classic baseline approaches. From the observed results, it is evident that we are in the early days of building a bridge between computational photography and visual recognition, leaving many opportunities for innovation in this area.