 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Autonomy in Human-on-the-Loop Vision-Based Robotics Systems
Mar 28, 2021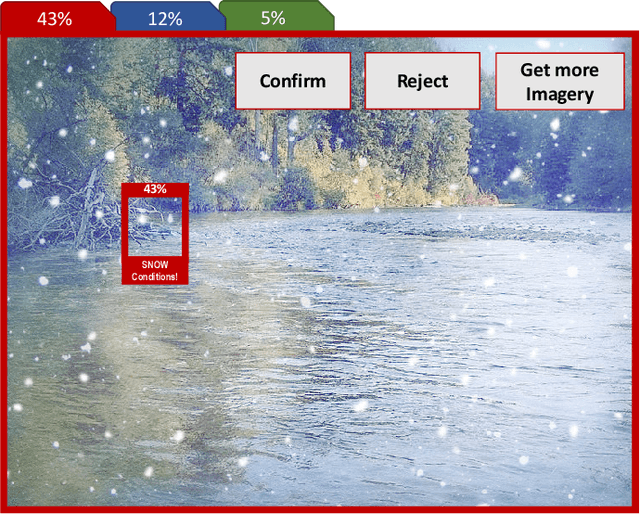
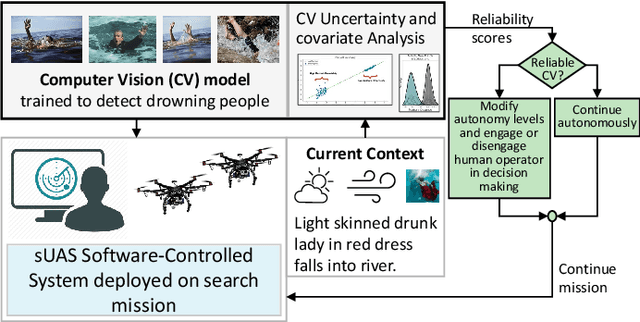
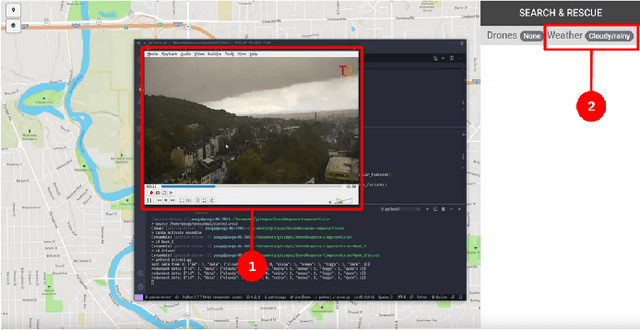

Computer vision approaches are widely used by autonomous robotic systems to sense the world around them and to guide their decision making as they perform diverse tasks such as collision avoidance, search and rescue, and object manipulation. High accuracy is critical, particularly for Human-on-the-loop (HoTL) systems where decisions are made autonomously by the system, and humans play only a supervisory role. Failures of the vision model can lead to erroneous decisions with potentially life or death consequences. In this paper, we propose a solution based upon adaptive autonomy levels, whereby the system detects loss of reliability of these models and responds by temporarily lowering its own autonomy levels and increasing engagement of the human in the decision-making process. Our solution is applicable for vision-based tasks in which humans have time to react and provide guidance. When implemented, our approach would estimate the reliability of the vision task by considering uncertainty in its model, and by performing covariate analysis to determine when the current operating environment is ill-matched to the model's training data. We provide examples from DroneResponse, in which small Unmanned Aerial Systems are deployed for Emergency Response missions, and show how the vision model's reliability would be used in addition to confidence scores to drive and specify the behavior and adaptation of the system's autonomy. This workshop paper outlines our proposed approach and describes open challenges at the intersection of Computer Vision and Software Engineering for the safe and reliable deployment of vision models in the decision making of autonomous systems.
Report on UG^2+ Challenge Track 1: Assessing Algorithms to Improve Video Object Detection and Classification from Unconstrained Mobility Platforms
Jul 26, 2019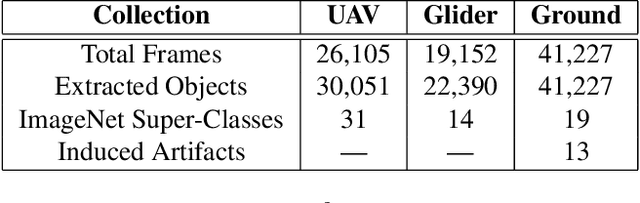
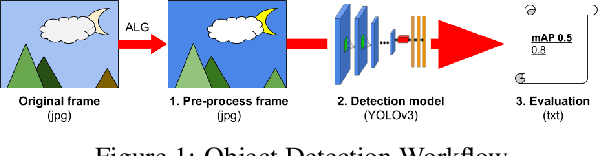


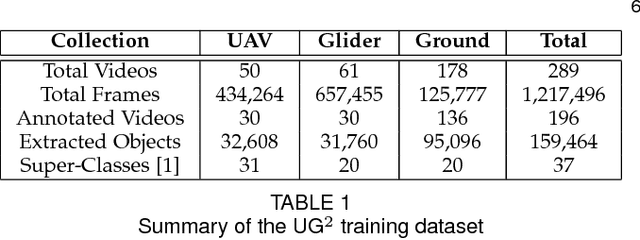
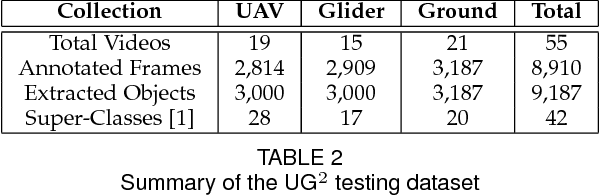
How can we effectively engineer a computer vision system that is able to interpret videos from unconstrained mobility platforms like UAVs? One promising option is to make use of image restoration and enhancement algorithms from the area of computational photography to improve the quality of the underlying frames in a way that also improves automatic visual recognition. Along these lines, exploratory work is needed to find out which image pre-processing algorithms, in combination with the strongest features and supervised machine learning approaches, are good candidates for difficult scenarios like motion blur, weather, and mis-focus --- all common artifacts in UAV acquired images. This paper summarizes the protocols and results of Track 1 of the UG^2+ Challenge held in conjunction with IEEE/CVF CVPR 2019. The challenge looked at two separate problems: (1) object detection improvement in video, and (2) object classification improvement in video. The challenge made use of the UG^2 (UAV, Glider, Ground) dataset, which is an established benchmark for assessing the interplay between image restoration and enhancement and visual recognition. 16 algorithms were submitted by academic and corporate teams, and a detailed analysis of how they performed on each challenge problem is reported here.
Bridging the Gap Between Computational Photography and Visual Recognition
Jan 28, 2019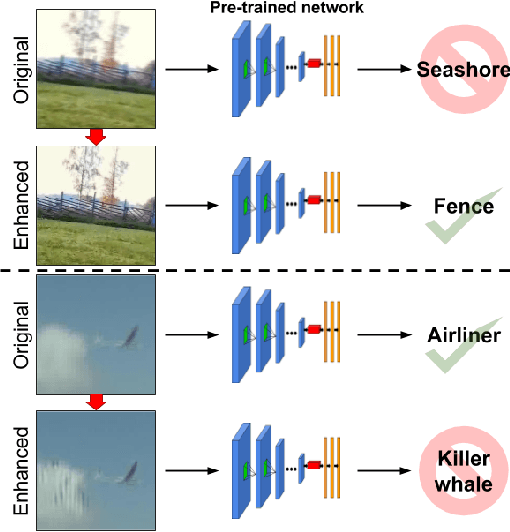

What is the current state-of-the-art for image restoration and enhancement applied to degraded images acquired under less than ideal circumstances? Can the application of such algorithms as a pre-processing step to improve image interpretability for manual analysis or automatic visual recognition to classify scene content? While there have been important advances in the area of computational photography to restore or enhance the visual quality of an image, the capabilities of such techniques have not always translated in a useful way to visual recognition tasks. Consequently, there is a pressing need for the development of algorithms that are designed for the joint problem of improving visual appearance and recognition, which will be an enabling factor for the deployment of visual recognition tools in many real-world scenarios. To address this, we introduce the UG^2 dataset as a large-scale benchmark composed of video imagery captured under challenging conditions, and two enhancement tasks designed to test algorithmic impact on visual quality and automatic object recognition. Furthermore, we propose a set of metrics to evaluate the joint improvement of such tasks as well as individual algorithmic advances, including a novel psychophysics-based evaluation regime for human assessment and a realistic set of quantitative measures for object recognition performance. We introduce six new algorithms for image restoration or enhancement, which were created as part of the IARPA sponsored UG^2 Challenge workshop held at CVPR 2018. Under the proposed evaluation regime, we present an in-depth analysis of these algorithms and a host of deep learning-based and classic baseline approaches. From the observed results, it is evident that we are in the early days of building a bridge between computational photography and visual recognition, leaving many opportunities for innovation in this area.
UG^2: a Video Benchmark for Assessing the Impact of Image Restoration and Enhancement on Automatic Visual Recognition
Feb 07, 2018
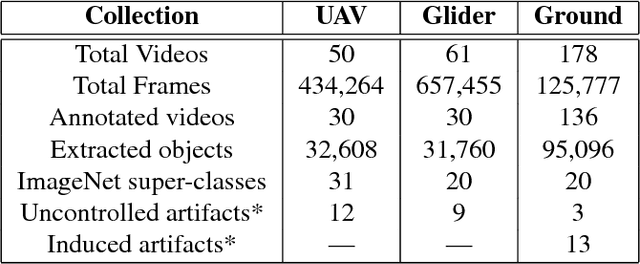


Advances in image restoration and enhancement techniques have led to discussion about how such algorithmscan be applied as a pre-processing step to improve automatic visual recognition. In principle, techniques like deblurring and super-resolution should yield improvements by de-emphasizing noise and increasing signal in an input image. But the historically divergent goals of the computational photography and visual recognition communities have created a significant need for more work in this direction. To facilitate new research, we introduce a new benchmark dataset called UG^2, which contains three difficult real-world scenarios: uncontrolled videos taken by UAVs and manned gliders, as well as controlled videos taken on the ground. Over 160,000 annotated frames forhundreds of ImageNet classes are available, which are used for baseline experiments that assess the impact of known and unknown image artifacts and other conditions on common deep learning-based object classification approaches. Further, current image restoration and enhancement techniques are evaluated by determining whether or not theyimprove baseline classification performance. Results showthat there is plenty of room for algorithmic innovation, making this dataset a useful tool going forward.
Neuron Segmentation Using Deep Complete Bipartite Networks
May 31, 2017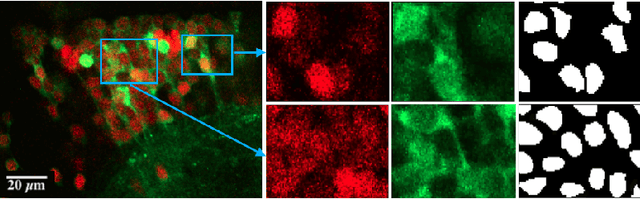
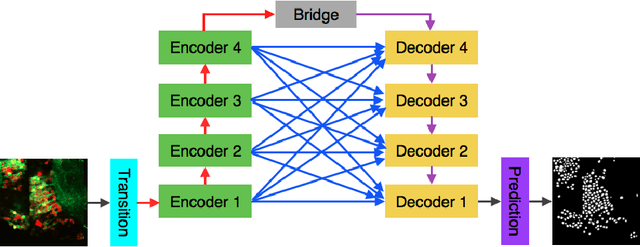


In this paper, we consider the problem of automatically segmenting neuronal cells in dual-color confocal microscopy images. This problem is a key task in various quantitative analysis applications in neuroscience, such as tracing cell genesis in Danio rerio (zebrafish) brains. Deep learning, especially using fully convolutional networks (FCN), has profoundly changed segmentation research in biomedical imaging. We face two major challenges in this problem. First, neuronal cells may form dense clusters, making it difficult to correctly identify all individual cells (even to human experts). Consequently, segmentation results of the known FCN-type models are not accurate enough. Second, pixel-wise ground truth is difficult to obtain. Only a limited amount of approximate instance-wise annotation can be collected, which makes the training of FCN models quite cumbersome. We propose a new FCN-type deep learning model, called deep complete bipartite networks (CB-Net), and a new scheme for leveraging approximate instance-wise annotation to train our pixel-wise prediction model. Evaluated using seven real datasets, our proposed new CB-Net model outperforms the state-of-the-art FCN models and produces neuron segmentation results of remarkable quality