 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFaR 2023: Efficient Face Recognition Competition
Aug 08, 2023



This paper presents the summary of the Efficient Face Recognition Competition (EFaR) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition received 17 submissions from 6 different teams. To drive further development of efficient face recognition models, the submitted solutions are ranked based on a weighted score of the achieved verification accuracies on a diverse set of benchmarks, as well as the deployability given by the number of floating-point operations and model size. The evaluation of submissions is extended to bias, cross-quality, and large-scale recognition benchmarks. Overall, the paper gives an overview of the achieved performance values of the submitted solutions as well as a diverse set of baselines. The submitted solutions use small, efficient network architectures to reduce the computational cost, some solutions apply model quantization. An outlook on possible techniques that are underrepresented in current solutions is given as well.
Meet-in-the-middle: Multi-scale upsampling and matching for cross-resolution face recognition
Nov 29, 2022



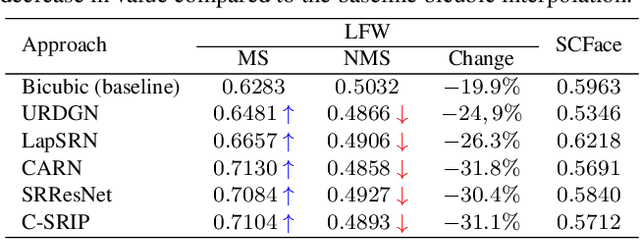
In this paper, we aim to address the large domain gap between high-resolution face images, e.g., from professional portrait photography, and low-quality surveillance images, e.g., from security cameras. Establishing an identity match between disparate sources like this is a classical surveillance face identification scenario, which continues to be a challenging problem for modern face recognition techniques. To that end, we propose a method that combines face super-resolution, resolution matching, and multi-scale template accumulation to reliably recognize faces from long-range surveillance footage, including from low quality sources. The proposed approach does not require training or fine-tuning on the target dataset of real surveillance images. Extensive experiments show that our proposed method is able to outperform even existing methods fine-tuned to the SCFace dataset.
MFR 2021: Masked Face Recognition Competition
Jun 29, 2021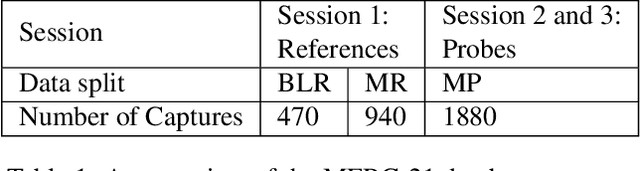

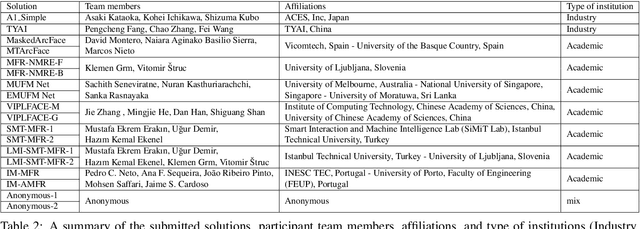
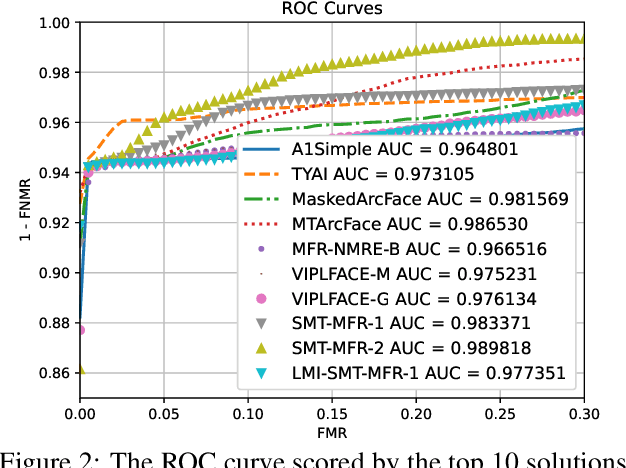
This paper presents a summary of the Masked Face Recognition Competitions (MFR) held within the 2021 International Joint Conference on Biometrics (IJCB 2021). The competition attracted a total of 10 participating teams with valid submissions. The affiliations of these teams are diverse and associated with academia and industry in nine different countries. These teams successfully submitted 18 valid solutions. The competition is designed to motivate solutions aiming at enhancing the face recognition accuracy of masked faces. Moreover, the competition considered the deployability of the proposed solutions by taking the compactness of the face recognition models into account. A private dataset representing a collaborative, multi-session, real masked, capture scenario is used to evaluate the submitted solutions. In comparison to one of the top-performing academic face recognition solutions, 10 out of the 18 submitted solutions did score higher masked face verification accuracy.
Segmentation and Recovery of Superquadric Models using Convolutional Neural Networks
Jan 28, 2020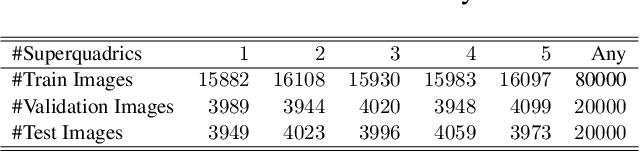

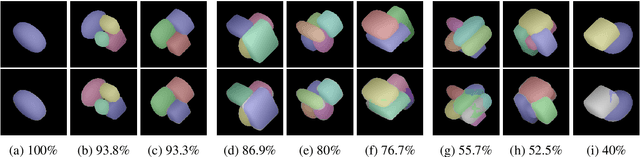
In this paper we address the problem of representing 3D visual data with parameterized volumetric shape primitives. Specifically, we present a (two-stage) approach built around convolutional neural networks (CNNs) capable of segmenting complex depth scenes into the simpler geometric structures that can be represented with superquadric models. In the first stage, our approach uses a Mask RCNN model to identify superquadric-like structures in depth scenes and then fits superquadric models to the segmented structures using a specially designed CNN regressor. Using our approach we are able to describe complex structures with a small number of interpretable parameters. We evaluated the proposed approach on synthetic as well as real-world depth data and show that our solution does not only result in competitive performance in comparison to the state-of-the-art, but is able to decompose scenes into a number of superquadric models at a fraction of the time required by competing approaches. We make all data and models used in the paper available from https://lmi.fe.uni-lj.si/en/research/resources/sq-seg.
Recovery of Superquadrics from Range Images using Deep Learning: A Preliminary Study
Apr 13, 2019
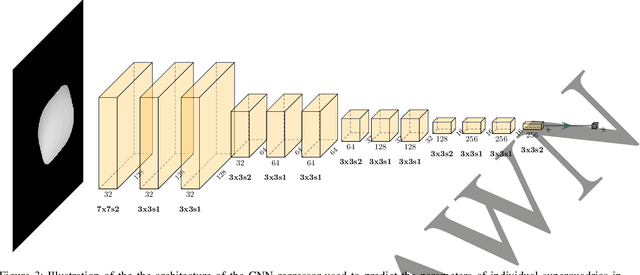


It has been a longstanding goal in computer vision to describe the 3D physical space in terms of parameterized volumetric models that would allow autonomous machines to understand and interact with their surroundings. Such models are typically motivated by human visual perception and aim to represents all elements of the physical word ranging from individual objects to complex scenes using a small set of parameters. One of the de facto stadards to approach this problem are superquadrics - volumetric models that define various 3D shape primitives and can be fitted to actual 3D data (either in the form of point clouds or range images). However, existing solutions to superquadric recovery involve costly iterative fitting procedures, which limit the applicability of such techniques in practice. To alleviate this problem, we explore in this paper the possibility to recover superquadrics from range images without time consuming iterative parameter estimation techniques by using contemporary deep-learning models, more specifically, convolutional neural networks (CNNs). We pose the superquadric recovery problem as a regression task and develop a CNN regressor that is able to estimate the parameters of a superquadric model from a given range image. We train the regressor on a large set of synthetic range images, each containing a single (unrotated) superquadric shape and evaluate the learned model in comparaitve experiments with the current state-of-the-art. Additionally, we also present a qualitative analysis involving a dataset of real-world objects. The results of our experiments show that the proposed regressor not only outperforms the existing state-of-the-art, but also ensures a 270x faster execution time.
Face Hallucination Revisited: An Exploratory Study on Dataset Bias
Dec 21, 2018
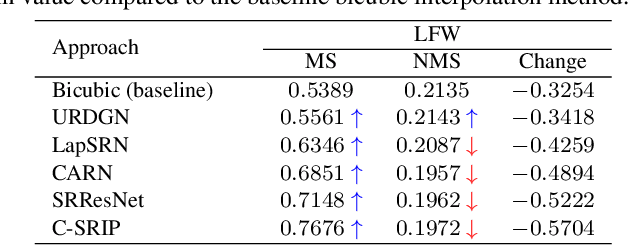
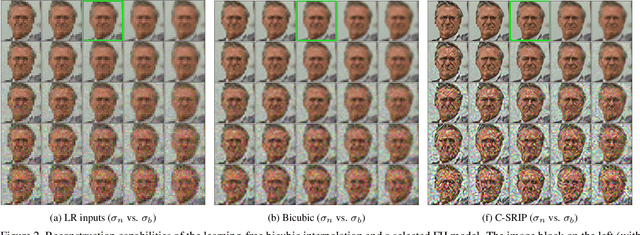
Contemporary face hallucination (FH) models exhibit considerable ability to reconstruct high-resolution (HR) details from low-resolution (LR) face images. This ability is commonly learned from examples of corresponding HR-LR image pairs, created by artificially down-sampling the HR ground truth data. This down-sampling (or degradation) procedure not only defines the characteristics of the LR training data, but also determines the type of image degradations the learned FH models are eventually able to handle. If the image characteristics encountered with real-world LR images differ from the ones seen during training, FH models are still expected to perform well, but in practice may not produce the desired results. In this paper we study this problem and explore the bias introduced into FH models by the characteristics of the training data. We systematically analyze the generalization capabilities of several FH models in various scenarios, where the image the degradation function does not match the training setup and conduct experiments with synthetically downgraded as well as real-life low-quality images. We make several interesting findings that provide insight into existing problems with FH models and point to future research directions.
Face hallucination using cascaded super-resolution and identity priors
May 28, 2018



In this paper we address the problem of hallucinating high-resolution facial images from unaligned low-resolution inputs at high magnification factors. We approach the problem with convolutional neural networks (CNNs) and propose a novel (deep) face hallucination model that incorporates identity priors into the learning procedure. The model consists of two main parts: i) a cascaded super-resolution network that upscales the low-resolution images, and ii) an ensemble of face recognition models that act as identity priors for the super-resolution network during training. Different from competing super-resolution approaches that typically rely on a single model for upscaling (even with large magnification factors), our network uses a cascade of multiple SR models that progressively upscale the low-resolution images using steps of $2\times$. This characteristic allows us to apply supervision signals (target appearances) at different resolutions and incorporate identity constraints at multiple-scales. Our model is able to upscale (very) low-resolution images captured in unconstrained conditions and produce visually convincing results. We rigorously evaluate the proposed model on a large datasets of facial images and report superior performance compared to the state-of-the-art.
UG^2: a Video Benchmark for Assessing the Impact of Image Restoration and Enhancement on Automatic Visual Recognition
Feb 07, 2018
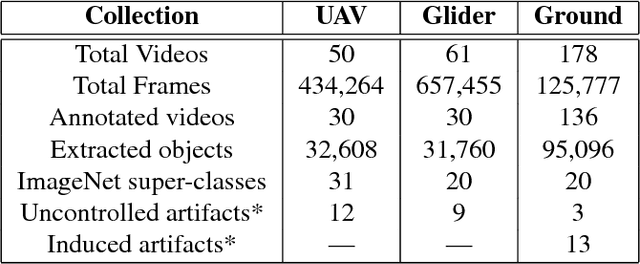


Advances in image restoration and enhancement techniques have led to discussion about how such algorithmscan be applied as a pre-processing step to improve automatic visual recognition. In principle, techniques like deblurring and super-resolution should yield improvements by de-emphasizing noise and increasing signal in an input image. But the historically divergent goals of the computational photography and visual recognition communities have created a significant need for more work in this direction. To facilitate new research, we introduce a new benchmark dataset called UG^2, which contains three difficult real-world scenarios: uncontrolled videos taken by UAVs and manned gliders, as well as controlled videos taken on the ground. Over 160,000 annotated frames forhundreds of ImageNet classes are available, which are used for baseline experiments that assess the impact of known and unknown image artifacts and other conditions on common deep learning-based object classification approaches. Further, current image restoration and enhancement techniques are evaluated by determining whether or not theyimprove baseline classification performance. Results showthat there is plenty of room for algorithmic innovation, making this dataset a useful tool going forward.
Strengths and Weaknesses of Deep Learning Models for Face Recognition Against Image Degradations
Oct 04, 2017

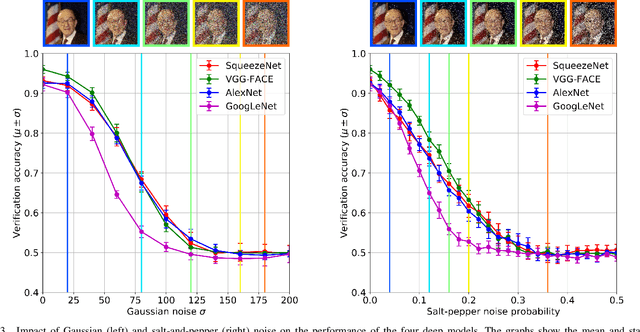

Deep convolutional neural networks (CNNs) based approaches are the state-of-the-art in various computer vision tasks, including face recognition. Considerable research effort is currently being directed towards further improving deep CNNs by focusing on more powerful model architectures and better learning techniques. However, studies systematically exploring the strengths and weaknesses of existing deep models for face recognition are still relatively scarce in the literature. In this paper, we try to fill this gap and study the effects of different covariates on the verification performance of four recent deep CNN models using the Labeled Faces in the Wild (LFW) dataset. Specifically, we investigate the influence of covariates related to: image quality -- blur, JPEG compression, occlusion, noise, image brightness, contrast, missing pixels; and model characteristics -- CNN architecture, color information, descriptor computation; and analyze their impact on the face verification performance of AlexNet, VGG-Face, GoogLeNet, and SqueezeNet. Based on comprehensive and rigorous experimentation, we identify the strengths and weaknesses of the deep learning models, and present key areas for potential future research. Our results indicate that high levels of noise, blur, missing pixels, and brightness have a detrimental effect on the verification performance of all models, whereas the impact of contrast changes and compression artifacts is limited. It has been found that the descriptor computation strategy and color information does not have a significant influence on performance.