 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFICE: Text-Conditioned Fashion Image Editing With Guided GAN Inversion
Jan 05, 2023Fashion-image editing represents a challenging computer vision task, where the goal is to incorporate selected apparel into a given input image. Most existing techniques, known as Virtual Try-On methods, deal with this task by first selecting an example image of the desired apparel and then transferring the clothing onto the target person. Conversely, in this paper, we consider editing fashion images with text descriptions. Such an approach has several advantages over example-based virtual try-on techniques, e.g.: (i) it does not require an image of the target fashion item, and (ii) it allows the expression of a wide variety of visual concepts through the use of natural language. Existing image-editing methods that work with language inputs are heavily constrained by their requirement for training sets with rich attribute annotations or they are only able to handle simple text descriptions. We address these constraints by proposing a novel text-conditioned editing model, called FICE (Fashion Image CLIP Editing), capable of handling a wide variety of diverse text descriptions to guide the editing procedure. Specifically with FICE, we augment the common GAN inversion process by including semantic, pose-related, and image-level constraints when generating images. We leverage the capabilities of the CLIP model to enforce the semantics, due to its impressive image-text association capabilities. We furthermore propose a latent-code regularization technique that provides the means to better control the fidelity of the synthesized images. We validate FICE through rigorous experiments on a combination of VITON images and Fashion-Gen text descriptions and in comparison with several state-of-the-art text-conditioned image editing approaches. Experimental results demonstrate FICE generates highly realistic fashion images and leads to stronger editing performance than existing competing approaches.
High Resolution Face Editing with Masked GAN Latent Code Optimization
Mar 20, 2021



Face editing is a popular research topic in the computer vision community that aims to edit a specific characteristic of a face image. Recent proposed methods are based on either training a conditional encoder-decoder Generative Adversarial Network (GAN) in an end-to-end fashion or on defining an operation in the latent space of a pre-trained vanilla GAN generator model. However, these methods exhibit a certain degree of visual degradation and lack disentanglement properties in the edited images. Moreover, they usually operate on lower image resolution. In this paper, we propose a GAN embedding optimization procedure with spatial and semantic constraints. We optimize a latent code of a GAN, pre-trained on face dataset, to embed a fixed region of the image, while imposing constraints on the inpainted regions with face parsing and attribute classification networks. By latent code optimization, we constrain the result to follow an image probability distribution, as defined by the GAN model. We use such framework to produce high image quality face edits. Due to the spatial constraints introduced, the edited images exhibit higher degree of disentanglement between the desired facial attributes and the rest of the image than other methods. The approach is validated in experiments on three datasets and in comparison with four state-of-the-art approaches. The results demonstrate that the proposed approach is able to edit face images with respect to several facial attributes with unprecedented image quality, while disentangling the undesired factors of variation. Code will be made available.
Face Hallucination Revisited: An Exploratory Study on Dataset Bias
Dec 21, 2018
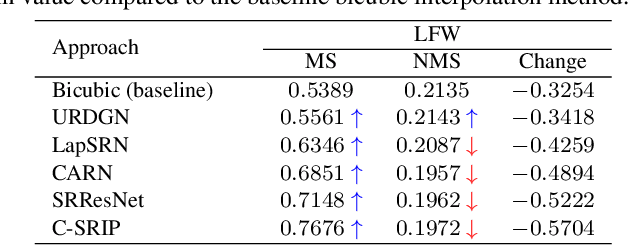
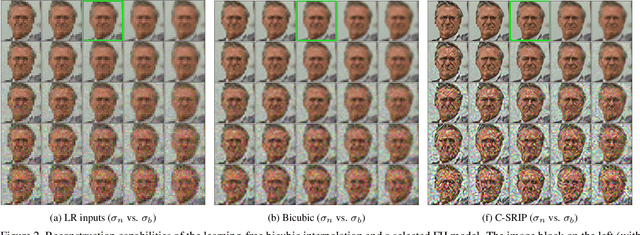
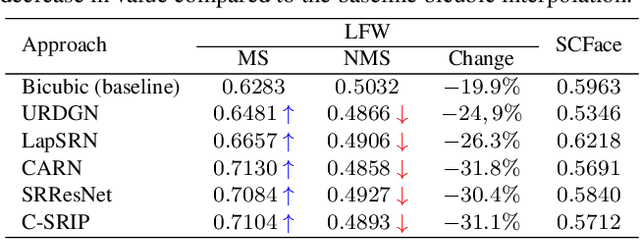
Contemporary face hallucination (FH) models exhibit considerable ability to reconstruct high-resolution (HR) details from low-resolution (LR) face images. This ability is commonly learned from examples of corresponding HR-LR image pairs, created by artificially down-sampling the HR ground truth data. This down-sampling (or degradation) procedure not only defines the characteristics of the LR training data, but also determines the type of image degradations the learned FH models are eventually able to handle. If the image characteristics encountered with real-world LR images differ from the ones seen during training, FH models are still expected to perform well, but in practice may not produce the desired results. In this paper we study this problem and explore the bias introduced into FH models by the characteristics of the training data. We systematically analyze the generalization capabilities of several FH models in various scenarios, where the image the degradation function does not match the training setup and conduct experiments with synthetically downgraded as well as real-life low-quality images. We make several interesting findings that provide insight into existing problems with FH models and point to future research directions.