 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Hallucination Revisited: An Exploratory Study on Dataset Bias
Dec 21, 2018
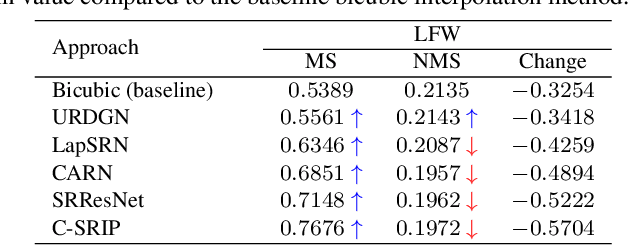
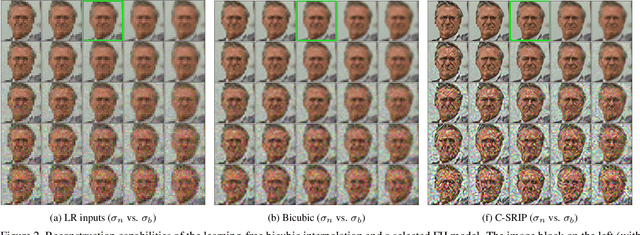
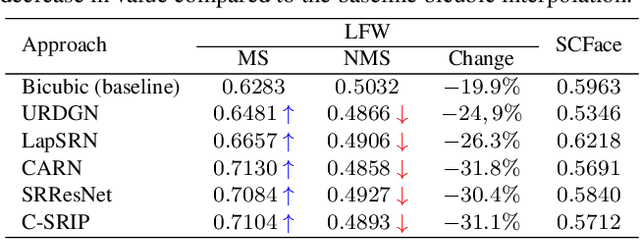
Contemporary face hallucination (FH) models exhibit considerable ability to reconstruct high-resolution (HR) details from low-resolution (LR) face images. This ability is commonly learned from examples of corresponding HR-LR image pairs, created by artificially down-sampling the HR ground truth data. This down-sampling (or degradation) procedure not only defines the characteristics of the LR training data, but also determines the type of image degradations the learned FH models are eventually able to handle. If the image characteristics encountered with real-world LR images differ from the ones seen during training, FH models are still expected to perform well, but in practice may not produce the desired results. In this paper we study this problem and explore the bias introduced into FH models by the characteristics of the training data. We systematically analyze the generalization capabilities of several FH models in various scenarios, where the image the degradation function does not match the training setup and conduct experiments with synthetically downgraded as well as real-life low-quality images. We make several interesting findings that provide insight into existing problems with FH models and point to future research directions.