 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Morphing Attack Detection in Open Multi-modal Large Language Models
Feb 17, 2026Face morphing attacks threaten biometric verification, yet most morphing attack detection (MAD) systems require task-specific training and generalize poorly to unseen attack types. Meanwhile, open-source multimodal large language models (MLLMs) have demonstrated strong visual-linguistic reasoning, but their potential in biometric forensics remains underexplored. In this paper, we present the first systematic zero-shot evaluation of open-source MLLMs for single-image MAD, using publicly available weights and a standardized, reproducible protocol. Across diverse morphing techniques, many MLLMs show non-trivial discriminative ability without any fine-tuning or domain adaptation, and LLaVA1.6-Mistral-7B achieves state-of-the-art performance, surpassing highly competitive task-specific MAD baselines by at least 23% in terms of equal error rate (EER). The results indicate that multimodal pretraining can implicitly encode fine-grained facial inconsistencies indicative of morphing artifacts, enabling zero-shot forensic sensitivity. Our findings position open-source MLLMs as reproducible, interpretable, and competitive foundations for biometric security and forensic image analysis. This emergent capability also highlights new opportunities to develop state-of-the-art MAD systems through targeted fine-tuning or lightweight adaptation, further improving accuracy and efficiency while preserving interpretability. To support future research, all code and evaluation protocols will be released upon publication.
ID-Booth: Identity-consistent Face Generation with Diffusion Models
Apr 10, 2025Recent advances in generative modeling have enabled the generation of high-quality synthetic data that is applicable in a variety of domains, including face recognition. Here, state-of-the-art generative models typically rely on conditioning and fine-tuning of powerful pretrained diffusion models to facilitate the synthesis of realistic images of a desired identity. Yet, these models often do not consider the identity of subjects during training, leading to poor consistency between generated and intended identities. In contrast, methods that employ identity-based training objectives tend to overfit on various aspects of the identity, and in turn, lower the diversity of images that can be generated. To address these issues, we present in this paper a novel generative diffusion-based framework, called ID-Booth. ID-Booth consists of a denoising network responsible for data generation, a variational auto-encoder for mapping images to and from a lower-dimensional latent space and a text encoder that allows for prompt-based control over the generation procedure. The framework utilizes a novel triplet identity training objective and enables identity-consistent image generation while retaining the synthesis capabilities of pretrained diffusion models. Experiments with a state-of-the-art latent diffusion model and diverse prompts reveal that our method facilitates better intra-identity consistency and inter-identity separability than competing methods, while achieving higher image diversity. In turn, the produced data allows for effective augmentation of small-scale datasets and training of better-performing recognition models in a privacy-preserving manner. The source code for the ID-Booth framework is publicly available at https://github.com/dariant/ID-Booth.
SelfMAD: Enhancing Generalization and Robustness in Morphing Attack Detection via Self-Supervised Learning
Apr 07, 2025With the continuous advancement of generative models, face morphing attacks have become a significant challenge for existing face verification systems due to their potential use in identity fraud and other malicious activities. Contemporary Morphing Attack Detection (MAD) approaches frequently rely on supervised, discriminative models trained on examples of bona fide and morphed images. These models typically perform well with morphs generated with techniques seen during training, but often lead to sub-optimal performance when subjected to novel unseen morphing techniques. While unsupervised models have been shown to perform better in terms of generalizability, they typically result in higher error rates, as they struggle to effectively capture features of subtle artifacts. To address these shortcomings, we present SelfMAD, a novel self-supervised approach that simulates general morphing attack artifacts, allowing classifiers to learn generic and robust decision boundaries without overfitting to the specific artifacts induced by particular face morphing methods. Through extensive experiments on widely used datasets, we demonstrate that SelfMAD significantly outperforms current state-of-the-art MADs, reducing the detection error by more than 64% in terms of EER when compared to the strongest unsupervised competitor, and by more than 66%, when compared to the best performing discriminative MAD model, tested in cross-morph settings. The source code for SelfMAD is available at https://github.com/LeonTodorov/SelfMAD.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
DiCTI: Diffusion-based Clothing Designer via Text-guided Input
Jul 04, 2024


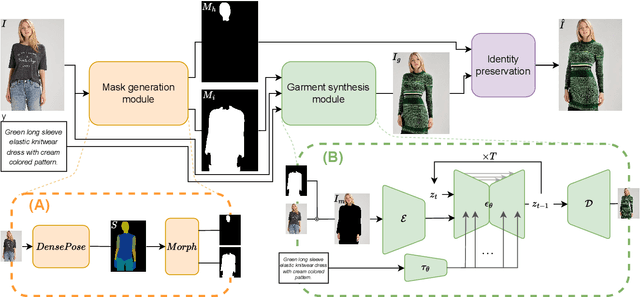
Recent developments in deep generative models have opened up a wide range of opportunities for image synthesis, leading to significant changes in various creative fields, including the fashion industry. While numerous methods have been proposed to benefit buyers, particularly in virtual try-on applications, there has been relatively less focus on facilitating fast prototyping for designers and customers seeking to order new designs. To address this gap, we introduce DiCTI (Diffusion-based Clothing Designer via Text-guided Input), a straightforward yet highly effective approach that allows designers to quickly visualize fashion-related ideas using text inputs only. Given an image of a person and a description of the desired garments as input, DiCTI automatically generates multiple high-resolution, photorealistic images that capture the expressed semantics. By leveraging a powerful diffusion-based inpainting model conditioned on text inputs, DiCTI is able to synthesize convincing, high-quality images with varied clothing designs that viably follow the provided text descriptions, while being able to process very diverse and challenging inputs, captured in completely unconstrained settings. We evaluate DiCTI in comprehensive experiments on two different datasets (VITON-HD and Fashionpedia) and in comparison to the state-of-the-art (SoTa). The results of our experiments show that DiCTI convincingly outperforms the SoTA competitor in generating higher quality images with more elaborate garments and superior text prompt adherence, both according to standard quantitative evaluation measures and human ratings, generated as part of a user study.
AdaDistill: Adaptive Knowledge Distillation for Deep Face Recognition
Jul 01, 2024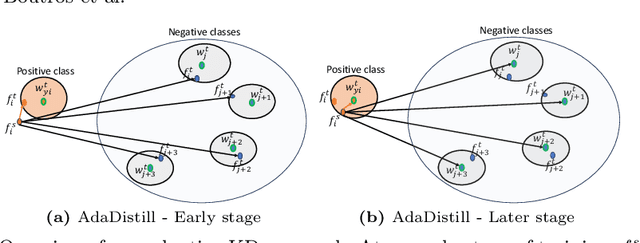
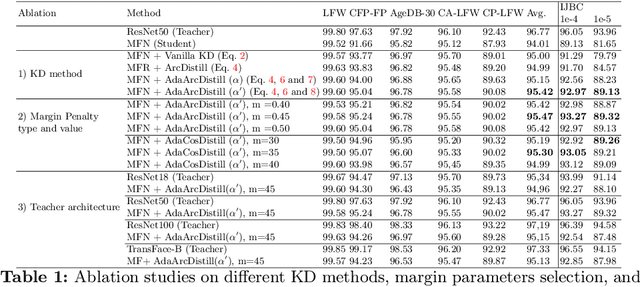
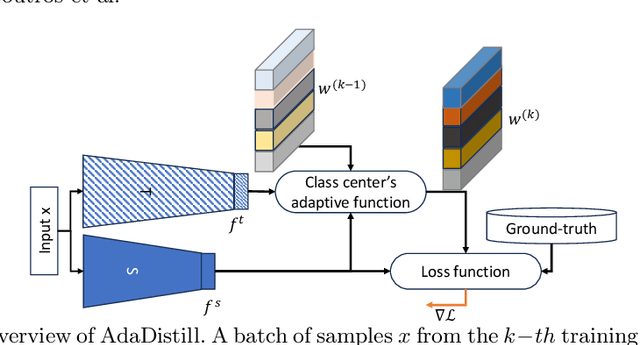
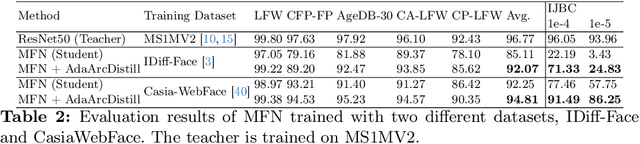
Knowledge distillation (KD) aims at improving the performance of a compact student model by distilling the knowledge from a high-performing teacher model. In this paper, we present an adaptive KD approach, namely AdaDistill, for deep face recognition. The proposed AdaDistill embeds the KD concept into the softmax loss by training the student using a margin penalty softmax loss with distilled class centers from the teacher. Being aware of the relatively low capacity of the compact student model, we propose to distill less complex knowledge at an early stage of training and more complex one at a later stage of training. This relative adjustment of the distilled knowledge is controlled by the progression of the learning capability of the student over the training iterations without the need to tune any hyper-parameters. Extensive experiments and ablation studies show that AdaDistill can enhance the discriminative learning capability of the student and demonstrate superiority over various state-of-the-art competitors on several challenging benchmarks, such as IJB-B, IJB-C, and ICCV2021-MFR
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
AI-KD: Towards Alignment Invariant Face Image Quality Assessment Using Knowledge Distillation
Apr 15, 2024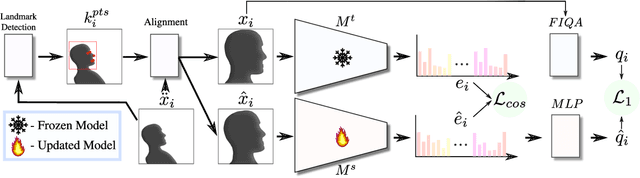
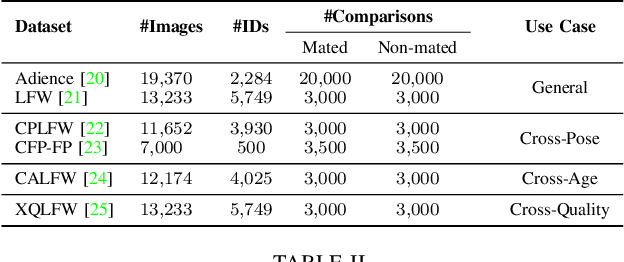
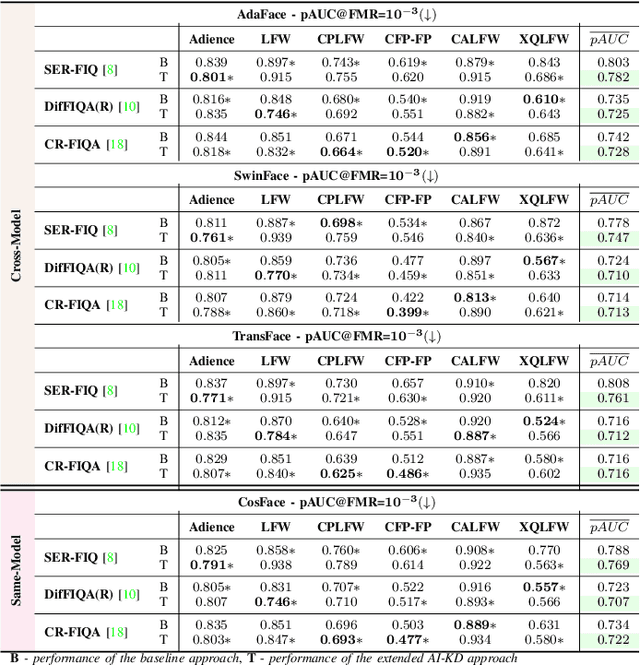
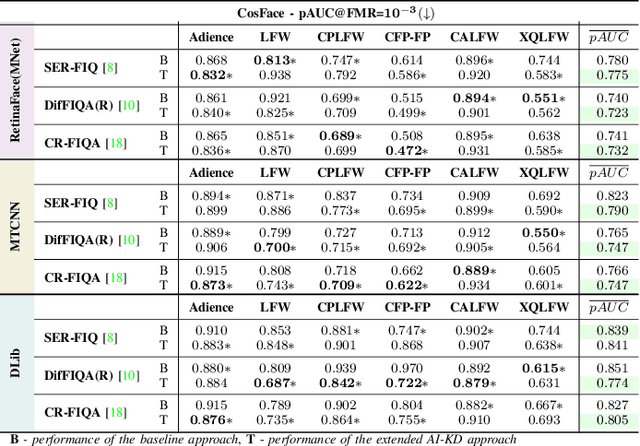
Face Image Quality Assessment (FIQA) techniques have seen steady improvements over recent years, but their performance still deteriorates if the input face samples are not properly aligned. This alignment sensitivity comes from the fact that most FIQA techniques are trained or designed using a specific face alignment procedure. If the alignment technique changes, the performance of most existing FIQA techniques quickly becomes suboptimal. To address this problem, we present in this paper a novel knowledge distillation approach, termed AI-KD that can extend on any existing FIQA technique, improving its robustness to alignment variations and, in turn, performance with different alignment procedures. To validate the proposed distillation approach, we conduct comprehensive experiments on 6 face datasets with 4 recent face recognition models and in comparison to 7 state-of-the-art FIQA techniques. Our results show that AI-KD consistently improves performance of the initial FIQA techniques not only with misaligned samples, but also with properly aligned facial images. Furthermore, it leads to a new state-of-the-art, when used with a competitive initial FIQA approach. The code for AI-KD is made publicly available from: https://github.com/LSIbabnikz/AI-KD.
EFaR 2023: Efficient Face Recognition Competition
Aug 08, 2023



This paper presents the summary of the Efficient Face Recognition Competition (EFaR) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition received 17 submissions from 6 different teams. To drive further development of efficient face recognition models, the submitted solutions are ranked based on a weighted score of the achieved verification accuracies on a diverse set of benchmarks, as well as the deployability given by the number of floating-point operations and model size. The evaluation of submissions is extended to bias, cross-quality, and large-scale recognition benchmarks. Overall, the paper gives an overview of the achieved performance values of the submitted solutions as well as a diverse set of baselines. The submitted solutions use small, efficient network architectures to reduce the computational cost, some solutions apply model quantization. An outlook on possible techniques that are underrepresented in current solutions is given as well.
On the Vulnerability of DeepFake Detectors to Attacks Generated by Denoising Diffusion Models
Jul 11, 2023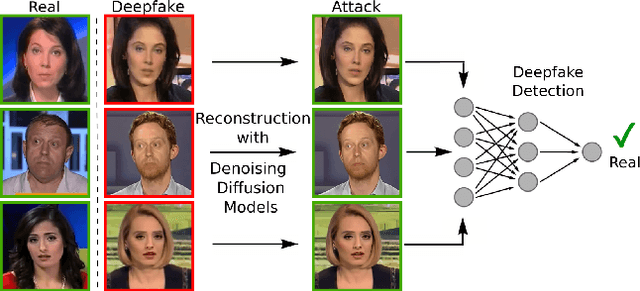



The detection of malicious Deepfakes is a constantly evolving problem, that requires continuous monitoring of detectors, to ensure they are able to detect image manipulations generated by the latest emerging models. In this paper, we present a preliminary study that investigates the vulnerability of single-image Deepfake detectors to attacks created by a representative of the newest generation of generative methods, i.e. Denoising Diffusion Models (DDMs). Our experiments are run on FaceForensics++, a commonly used benchmark dataset, consisting of Deepfakes generated with various techniques for face swapping and face reenactment. The analysis shows, that reconstructing existing Deepfakes with only one denoising diffusion step significantly decreases the accuracy of all tested detectors, without introducing visually perceptible image changes.