 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaDistill: Adaptive Knowledge Distillation for Deep Face Recognition
Paper and Code
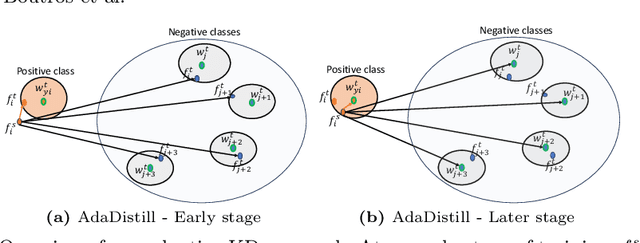
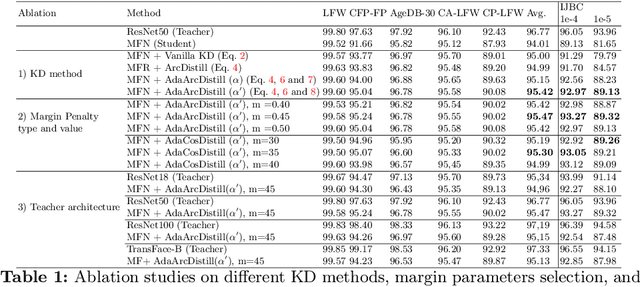
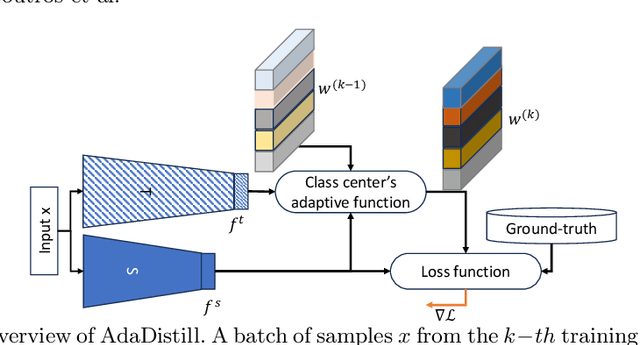
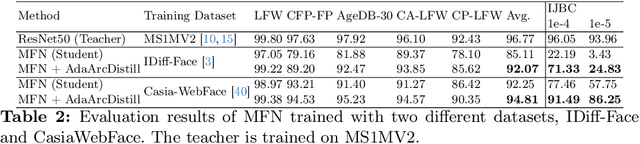
Knowledge distillation (KD) aims at improving the performance of a compact student model by distilling the knowledge from a high-performing teacher model. In this paper, we present an adaptive KD approach, namely AdaDistill, for deep face recognition. The proposed AdaDistill embeds the KD concept into the softmax loss by training the student using a margin penalty softmax loss with distilled class centers from the teacher. Being aware of the relatively low capacity of the compact student model, we propose to distill less complex knowledge at an early stage of training and more complex one at a later stage of training. This relative adjustment of the distilled knowledge is controlled by the progression of the learning capability of the student over the training iterations without the need to tune any hyper-parameters. Extensive experiments and ablation studies show that AdaDistill can enhance the discriminative learning capability of the student and demonstrate superiority over various state-of-the-art competitors on several challenging benchmarks, such as IJB-B, IJB-C, and ICCV2021-MFR