 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLENDER: Blended Text Embeddings and Diffusion Residuals for Intra-Class Image Synthesis in Deep Metric Learning
Jan 28, 2026The rise of Deep Generative Models (DGM) has enabled the generation of high-quality synthetic data. When used to augment authentic data in Deep Metric Learning (DML), these synthetic samples enhance intra-class diversity and improve the performance of downstream DML tasks. We introduce BLenDeR, a diffusion sampling method designed to increase intra-class diversity for DML in a controllable way by leveraging set-theory inspired union and intersection operations on denoising residuals. The union operation encourages any attribute present across multiple prompts, while the intersection extracts the common direction through a principal component surrogate. These operations enable controlled synthesis of diverse attribute combinations within each class, addressing key limitations of existing generative approaches. Experiments on standard DML benchmarks demonstrate that BLenDeR consistently outperforms state-of-the-art baselines across multiple datasets and backbones. Specifically, BLenDeR achieves 3.7% increase in Recall@1 on CUB-200 and a 1.8% increase on Cars-196, compared to state-of-the-art baselines under standard experimental settings.
ViTNT-FIQA: Training-Free Face Image Quality Assessment with Vision Transformers
Jan 09, 2026Face Image Quality Assessment (FIQA) is essential for reliable face recognition systems. Current approaches primarily exploit only final-layer representations, while training-free methods require multiple forward passes or backpropagation. We propose ViTNT-FIQA, a training-free approach that measures the stability of patch embedding evolution across intermediate Vision Transformer (ViT) blocks. We demonstrate that high-quality face images exhibit stable feature refinement trajectories across blocks, while degraded images show erratic transformations. Our method computes Euclidean distances between L2-normalized patch embeddings from consecutive transformer blocks and aggregates them into image-level quality scores. We empirically validate this correlation on a quality-labeled synthetic dataset with controlled degradation levels. Unlike existing training-free approaches, ViTNT-FIQA requires only a single forward pass without backpropagation or architectural modifications. Through extensive evaluation on eight benchmarks (LFW, AgeDB-30, CFP-FP, CALFW, Adience, CPLFW, XQLFW, IJB-C), we show that ViTNT-FIQA achieves competitive performance with state-of-the-art methods while maintaining computational efficiency and immediate applicability to any pre-trained ViT-based face recognition model.
Trade-offs in Cross-Domain Generalization of Foundation Model Fine-Tuned for Biometric Applications
Sep 18, 2025Foundation models such as CLIP have demonstrated exceptional zero- and few-shot transfer capabilities across diverse vision tasks. However, when fine-tuned for highly specialized biometric tasks, face recognition (FR), morphing attack detection (MAD), and presentation attack detection (PAD), these models may suffer from over-specialization. Thus, they may lose one of their foundational strengths, cross-domain generalization. In this work, we systematically quantify these trade-offs by evaluating three instances of CLIP fine-tuned for FR, MAD, and PAD. We evaluate each adapted model as well as the original CLIP baseline on 14 general vision datasets under zero-shot and linear-probe protocols, alongside common FR, MAD, and PAD benchmarks. Our results indicate that fine-tuned models suffer from over-specialization, especially when fine-tuned for complex tasks of FR. Also, our results pointed out that task complexity and classification head design, multi-class (FR) vs. binary (MAD and PAD), correlate with the degree of catastrophic forgetting. The FRoundation model with the ViT-L backbone outperforms other approaches on the large-scale FR benchmark IJB-C, achieving an improvement of up to 58.52%. However, it experiences a substantial performance drop on ImageNetV2, reaching only 51.63% compared to 69.84% achieved by the baseline CLIP model. Moreover, the larger CLIP architecture consistently preserves more of the model's original generalization ability than the smaller variant, indicating that increased model capacity may help mitigate over-specialization.
MADPromptS: Unlocking Zero-Shot Morphing Attack Detection with Multiple Prompt Aggregation
Aug 12, 2025Face Morphing Attack Detection (MAD) is a critical challenge in face recognition security, where attackers can fool systems by interpolating the identity information of two or more individuals into a single face image, resulting in samples that can be verified as belonging to multiple identities by face recognition systems. While multimodal foundation models (FMs) like CLIP offer strong zero-shot capabilities by jointly modeling images and text, most prior works on FMs for biometric recognition have relied on fine-tuning for specific downstream tasks, neglecting their potential for direct, generalizable deployment. This work explores a pure zero-shot approach to MAD by leveraging CLIP without any additional training or fine-tuning, focusing instead on the design and aggregation of multiple textual prompts per class. By aggregating the embeddings of diverse prompts, we better align the model's internal representations with the MAD task, capturing richer and more varied cues indicative of bona-fide or attack samples. Our results show that prompt aggregation substantially improves zero-shot detection performance, demonstrating the effectiveness of exploiting foundation models' built-in multimodal knowledge through efficient prompt engineering.
Second Competition on Presentation Attack Detection on ID Card
Jul 27, 2025This work summarises and reports the results of the second Presentation Attack Detection competition on ID cards. This new version includes new elements compared to the previous one. (1) An automatic evaluation platform was enabled for automatic benchmarking; (2) Two tracks were proposed in order to evaluate algorithms and datasets, respectively; and (3) A new ID card dataset was shared with Track 1 teams to serve as the baseline dataset for the training and optimisation. The Hochschule Darmstadt, Fraunhofer-IGD, and Facephi company jointly organised this challenge. 20 teams were registered, and 74 submitted models were evaluated. For Track 1, the "Dragons" team reached first place with an Average Ranking and Equal Error rate (EER) of AV-Rank of 40.48% and 11.44% EER, respectively. For the more challenging approach in Track 2, the "Incode" team reached the best results with an AV-Rank of 14.76% and 6.36% EER, improving on the results of the first edition of 74.30% and 21.87% EER, respectively. These results suggest that PAD on ID cards is improving, but it is still a challenging problem related to the number of images, especially of bona fide images.
DiffProb: Data Pruning for Face Recognition
May 21, 2025Face recognition models have made substantial progress due to advances in deep learning and the availability of large-scale datasets. However, reliance on massive annotated datasets introduces challenges related to training computational cost and data storage, as well as potential privacy concerns regarding managing large face datasets. This paper presents DiffProb, the first data pruning approach for the application of face recognition. DiffProb assesses the prediction probabilities of training samples within each identity and prunes the ones with identical or close prediction probability values, as they are likely reinforcing the same decision boundaries, and thus contribute minimally with new information. We further enhance this process with an auxiliary cleaning mechanism to eliminate mislabeled and label-flipped samples, boosting data quality with minimal loss. Extensive experiments on CASIA-WebFace with different pruning ratios and multiple benchmarks, including LFW, CFP-FP, and IJB-C, demonstrate that DiffProb can prune up to 50% of the dataset while maintaining or even, in some settings, improving the verification accuracies. Additionally, we demonstrate DiffProb's robustness across different architectures and loss functions. Our method significantly reduces training cost and data volume, enabling efficient face recognition training and reducing the reliance on massive datasets and their demanding management.
ID-Booth: Identity-consistent Face Generation with Diffusion Models
Apr 10, 2025Recent advances in generative modeling have enabled the generation of high-quality synthetic data that is applicable in a variety of domains, including face recognition. Here, state-of-the-art generative models typically rely on conditioning and fine-tuning of powerful pretrained diffusion models to facilitate the synthesis of realistic images of a desired identity. Yet, these models often do not consider the identity of subjects during training, leading to poor consistency between generated and intended identities. In contrast, methods that employ identity-based training objectives tend to overfit on various aspects of the identity, and in turn, lower the diversity of images that can be generated. To address these issues, we present in this paper a novel generative diffusion-based framework, called ID-Booth. ID-Booth consists of a denoising network responsible for data generation, a variational auto-encoder for mapping images to and from a lower-dimensional latent space and a text encoder that allows for prompt-based control over the generation procedure. The framework utilizes a novel triplet identity training objective and enables identity-consistent image generation while retaining the synthesis capabilities of pretrained diffusion models. Experiments with a state-of-the-art latent diffusion model and diverse prompts reveal that our method facilitates better intra-identity consistency and inter-identity separability than competing methods, while achieving higher image diversity. In turn, the produced data allows for effective augmentation of small-scale datasets and training of better-performing recognition models in a privacy-preserving manner. The source code for the ID-Booth framework is publicly available at https://github.com/dariant/ID-Booth.
SelfMAD: Enhancing Generalization and Robustness in Morphing Attack Detection via Self-Supervised Learning
Apr 07, 2025With the continuous advancement of generative models, face morphing attacks have become a significant challenge for existing face verification systems due to their potential use in identity fraud and other malicious activities. Contemporary Morphing Attack Detection (MAD) approaches frequently rely on supervised, discriminative models trained on examples of bona fide and morphed images. These models typically perform well with morphs generated with techniques seen during training, but often lead to sub-optimal performance when subjected to novel unseen morphing techniques. While unsupervised models have been shown to perform better in terms of generalizability, they typically result in higher error rates, as they struggle to effectively capture features of subtle artifacts. To address these shortcomings, we present SelfMAD, a novel self-supervised approach that simulates general morphing attack artifacts, allowing classifiers to learn generic and robust decision boundaries without overfitting to the specific artifacts induced by particular face morphing methods. Through extensive experiments on widely used datasets, we demonstrate that SelfMAD significantly outperforms current state-of-the-art MADs, reducing the detection error by more than 64% in terms of EER when compared to the strongest unsupervised competitor, and by more than 66%, when compared to the best performing discriminative MAD model, tested in cross-morph settings. The source code for SelfMAD is available at https://github.com/LeonTodorov/SelfMAD.
Frequency Matters: Explaining Biases of Face Recognition in the Frequency Domain
Jan 28, 2025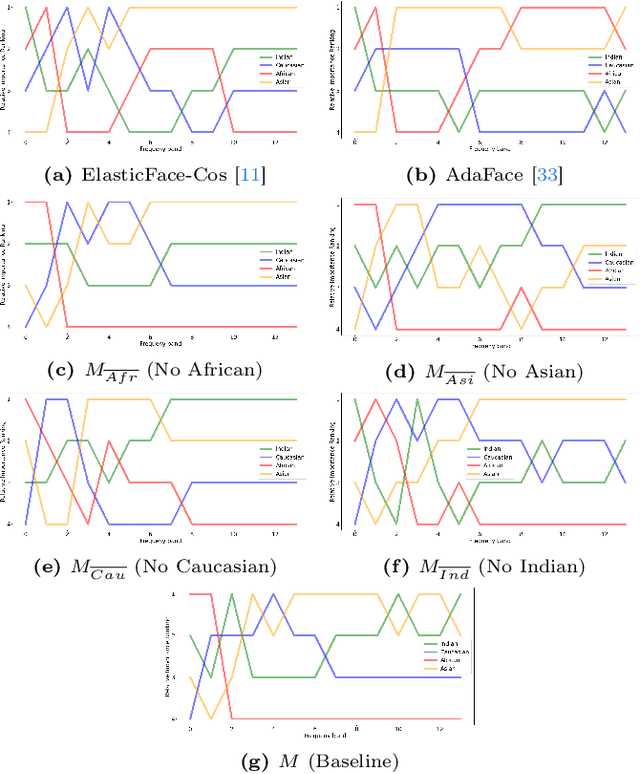
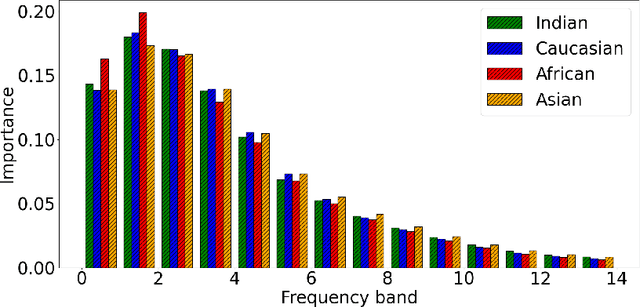
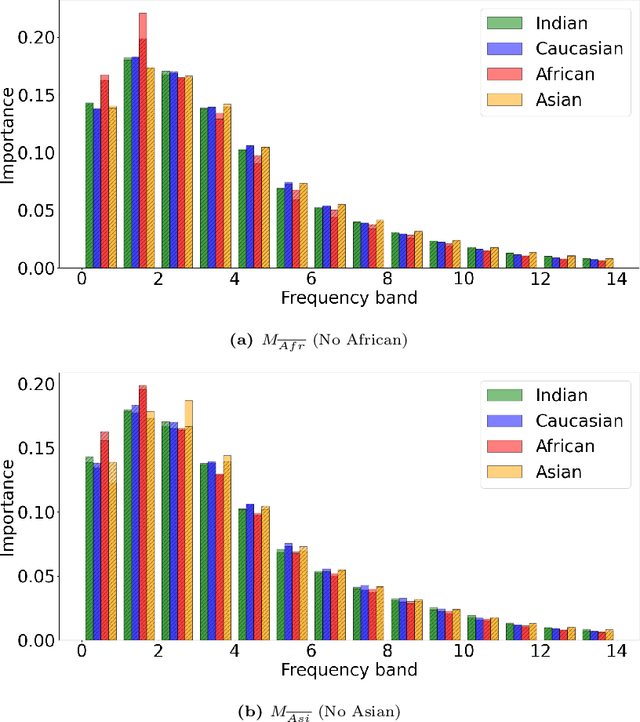
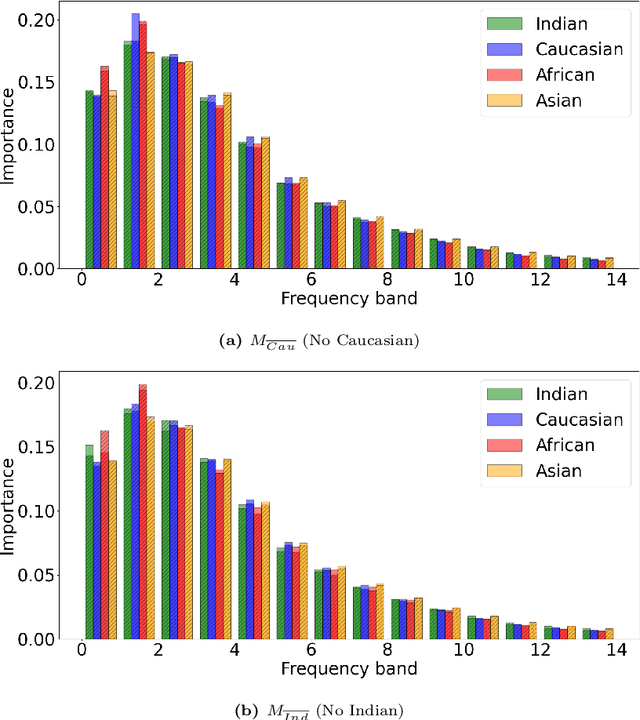
Face recognition (FR) models are vulnerable to performance variations across demographic groups. The causes for these performance differences are unclear due to the highly complex deep learning-based structure of face recognition models. Several works aimed at exploring possible roots of gender and ethnicity bias, identifying semantic reasons such as hairstyle, make-up, or facial hair as possible sources. Motivated by recent discoveries of the importance of frequency patterns in convolutional neural networks, we explain bias in face recognition using state-of-the-art frequency-based explanations. Our extensive results show that different frequencies are important to FR models depending on the ethnicity of the samples.
MADation: Face Morphing Attack Detection with Foundation Models
Jan 08, 2025Despite the considerable performance improvements of face recognition algorithms in recent years, the same scientific advances responsible for this progress can also be used to create efficient ways to attack them, posing a threat to their secure deployment. Morphing attack detection (MAD) systems aim to detect a specific type of threat, morphing attacks, at an early stage, preventing them from being considered for verification in critical processes. Foundation models (FM) learn from extensive amounts of unlabeled data, achieving remarkable zero-shot generalization to unseen domains. Although this generalization capacity might be weak when dealing with domain-specific downstream tasks such as MAD, FMs can easily adapt to these settings while retaining the built-in knowledge acquired during pre-training. In this work, we recognize the potential of FMs to perform well in the MAD task when properly adapted to its specificities. To this end, we adapt FM CLIP architectures with LoRA weights while simultaneously training a classification header. The proposed framework, MADation surpasses our alternative FM and transformer-based frameworks and constitutes the first adaption of FMs to the MAD task. MADation presents competitive results with current MAD solutions in the literature and even surpasses them in several evaluation scenarios. To encourage reproducibility and facilitate further research in MAD, we publicly release the implementation of MADation at https: //github.com/gurayozgur/MADation