 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Avatar Fingerprinting: A Multi-Generator Photorealistic Talking-Head Public Database and Benchmark
Mar 27, 2026Recent advances in photorealistic avatar generation have enabled highly realistic talking-head avatars, raising security concerns regarding identity impersonation in AI-mediated communication. To advance in this challenging problem, the task of avatar fingerprinting aims to determine whether two avatar videos are driven by the same human operator or not. However, current public databases in the literature are scarce and based solely on old-fashioned talking-head avatar generators, not representing realistic scenarios for the current task of avatar fingerprinting. To overcome this situation, the present article introduces AVAPrintDB, a new publicly available multi-generator talking-head avatar database for avatar fingerprinting. AVAPrintDB is constructed from two audiovisual corpora and three state-of-the-art avatar generators (GAGAvatar, LivePortrait, HunyuanPortrait), representing different synthesis paradigms, and includes both self- and cross-reenactments to simulate legitimate usage and impersonation scenarios. Building on this database, we also define a standardized and reproducible benchmark for avatar fingerprinting, considering public state-of-the-art avatar fingerprinting systems and exploring novel methods based on Foundation Models (DINOv2 and CLIP). Also, we conduct a comprehensive analysis under generator and dataset shift. Our results show that, while identity-related motion cues persist across synthetic avatars, current avatar fingerprinting systems remain highly sensitive to changes in the synthesis pipeline and source domain. The AVAPrintDB, benchmark protocols, and avatar fingerprinting systems are publicly available to facilitate reproducible research.
Is It Really You? Exploring Biometric Verification Scenarios in Photorealistic Talking-Head Avatar Videos
Aug 01, 2025



Photorealistic talking-head avatars are becoming increasingly common in virtual meetings, gaming, and social platforms. These avatars allow for more immersive communication, but they also introduce serious security risks. One emerging threat is impersonation: an attacker can steal a user's avatar-preserving their appearance and voice-making it nearly impossible to detect its fraudulent usage by sight or sound alone. In this paper, we explore the challenge of biometric verification in such avatar-mediated scenarios. Our main question is whether an individual's facial motion patterns can serve as reliable behavioral biometrics to verify their identity when the avatar's visual appearance is a facsimile of its owner. To answer this question, we introduce a new dataset of realistic avatar videos created using a state-of-the-art one-shot avatar generation model, GAGAvatar, with genuine and impostor avatar videos. We also propose a lightweight, explainable spatio-temporal Graph Convolutional Network architecture with temporal attention pooling, that uses only facial landmarks to model dynamic facial gestures. Experimental results demonstrate that facial motion cues enable meaningful identity verification with AUC values approaching 80%. The proposed benchmark and biometric system are available for the research community in order to bring attention to the urgent need for more advanced behavioral biometric defenses in avatar-based communication systems.
Comparison of Visual Trackers for Biomechanical Analysis of Running
May 07, 2025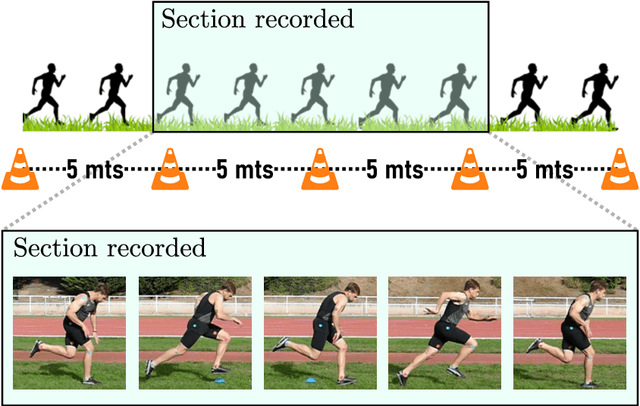
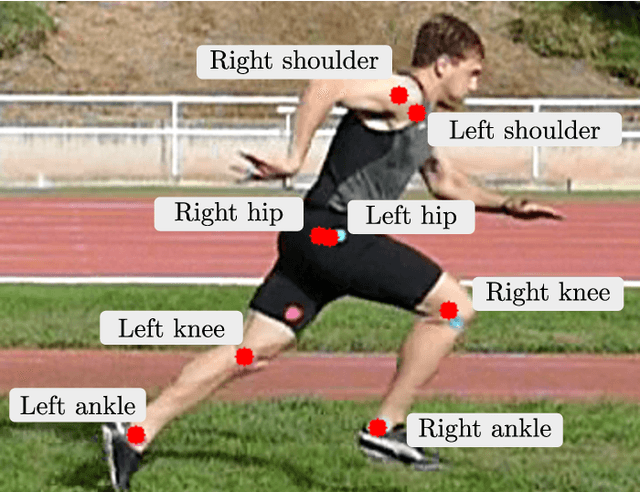

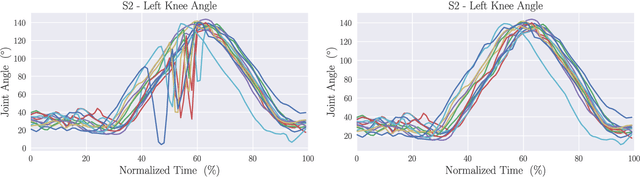
Human pose estimation has witnessed significant advancements in recent years, mainly due to the integration of deep learning models, the availability of a vast amount of data, and large computational resources. These developments have led to highly accurate body tracking systems, which have direct applications in sports analysis and performance evaluation. This work analyzes the performance of six trackers: two point trackers and four joint trackers for biomechanical analysis in sprints. The proposed framework compares the results obtained from these pose trackers with the manual annotations of biomechanical experts for more than 5870 frames. The experimental framework employs forty sprints from five professional runners, focusing on three key angles in sprint biomechanics: trunk inclination, hip flex extension, and knee flex extension. We propose a post-processing module for outlier detection and fusion prediction in the joint angles. The experimental results demonstrate that using joint-based models yields root mean squared errors ranging from 11.41{\deg} to 4.37{\deg}. When integrated with the post-processing modules, these errors can be reduced to 6.99{\deg} and 3.88{\deg}, respectively. The experimental findings suggest that human pose tracking approaches can be valuable resources for the biomechanical analysis of running. However, there is still room for improvement in applications where high accuracy is required.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
VideoRun2D: Cost-Effective Markerless Motion Capture for Sprint Biomechanics
Sep 16, 2024Sprinting is a determinant ability, especially in team sports. The kinematics of the sprint have been studied in the past using different methods specially developed considering human biomechanics and, among those methods, markerless systems stand out as very cost-effective. On the other hand, we have now multiple general methods for pixel and body tracking based on recent machine learning breakthroughs with excellent performance in body tracking, but these excellent trackers do not generally consider realistic human biomechanics. This investigation first adapts two of these general trackers (MoveNet and CoTracker) for realistic biomechanical analysis and then evaluate them in comparison to manual tracking (with key points manually marked using the software Kinovea). Our best resulting markerless body tracker particularly adapted for sprint biomechanics is termed VideoRun2D. The experimental development and assessment of VideoRun2D is reported on forty sprints recorded with a video camera from 5 different subjects, focusing our analysis in 3 key angles in sprint biomechanics: inclination of the trunk, flex extension of the hip and the knee. The CoTracker method showed huge differences compared to the manual labeling approach. However, the angle curves were correctly estimated by the MoveNet method, finding errors between 3.2{\deg} and 5.5{\deg}. In conclusion, our proposed VideoRun2D based on MoveNet core seems to be a helpful tool for evaluating sprint kinematics in some scenarios. On the other hand, the observed precision of this first version of VideoRun2D as a markerless sprint analysis system may not be yet enough for highly demanding applications. Future research lines towards that purpose are also discussed at the end: better tracking post-processing and user- and time-dependent adaptation.
DeepFace-Attention: Multimodal Face Biometrics for Attention Estimation with Application to e-Learning
Aug 14, 2024

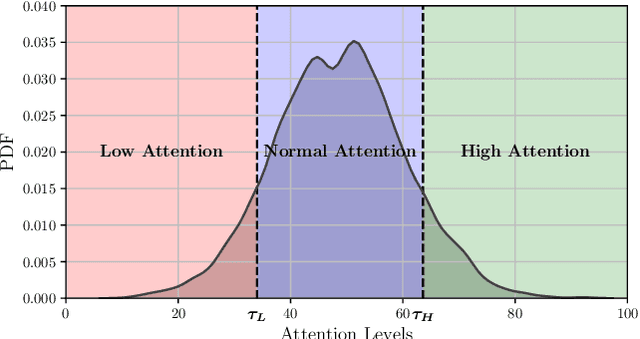

This work introduces an innovative method for estimating attention levels (cognitive load) using an ensemble of facial analysis techniques applied to webcam videos. Our method is particularly useful, among others, in e-learning applications, so we trained, evaluated, and compared our approach on the mEBAL2 database, a public multi-modal database acquired in an e-learning environment. mEBAL2 comprises data from 60 users who performed 8 different tasks. These tasks varied in difficulty, leading to changes in their cognitive loads. Our approach adapts state-of-the-art facial analysis technologies to quantify the users' cognitive load in the form of high or low attention. Several behavioral signals and physiological processes related to the cognitive load are used, such as eyeblink, heart rate, facial action units, and head pose, among others. Furthermore, we conduct a study to understand which individual features obtain better results, the most efficient combinations, explore local and global features, and how temporary time intervals affect attention level estimation, among other aspects. We find that global facial features are more appropriate for multimodal systems using score-level fusion, particularly as the temporal window increases. On the other hand, local features are more suitable for fusion through neural network training with score-level fusion approaches. Our method outperforms existing state-of-the-art accuracies using the public mEBAL2 benchmark.
PAD-Phys: Exploiting Physiology for Presentation Attack Detection in Face Biometrics
Oct 03, 2023Presentation Attack Detection (PAD) is a crucial stage in facial recognition systems to avoid leakage of personal information or spoofing of identity to entities. Recently, pulse detection based on remote photoplethysmography (rPPG) has been shown to be effective in face presentation attack detection. This work presents three different approaches to the presentation attack detection based on rPPG: (i) The physiological domain, a domain using rPPG-based models, (ii) the Deepfakes domain, a domain where models were retrained from the physiological domain to specific Deepfakes detection tasks; and (iii) a new Presentation Attack domain was trained by applying transfer learning from the two previous domains to improve the capability to differentiate between bona-fides and attacks. The results show the efficiency of the rPPG-based models for presentation attack detection, evidencing a 21.70% decrease in average classification error rate (ACER) (from 41.03% to 19.32%) when the presentation attack domain is compared to the physiological and Deepfakes domains. Our experiments highlight the efficiency of transfer learning in rPPG-based models and perform well in presentation attack detection in instruments that do not allow copying of this physiological feature.
MATT: Multimodal Attention Level Estimation for e-learning Platforms
Jan 22, 2023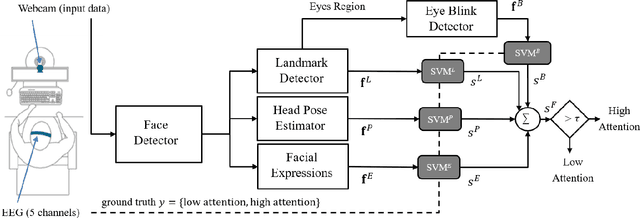
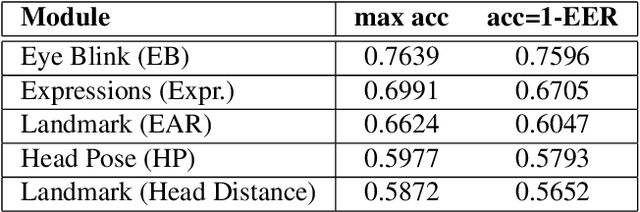
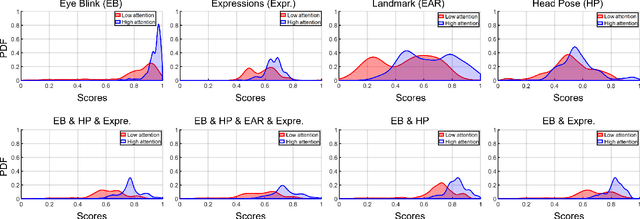
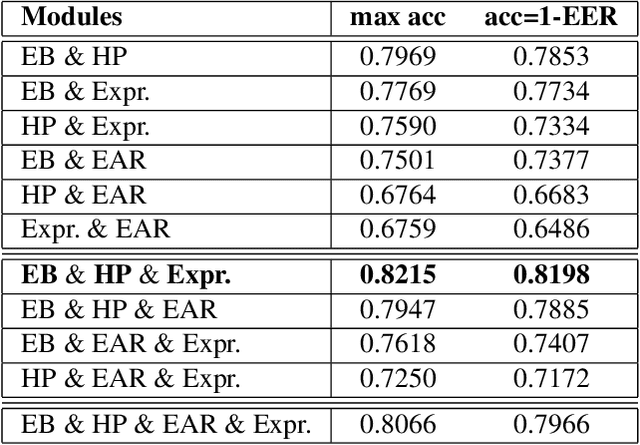
This work presents a new multimodal system for remote attention level estimation based on multimodal face analysis. Our multimodal approach uses different parameters and signals obtained from the behavior and physiological processes that have been related to modeling cognitive load such as faces gestures (e.g., blink rate, facial actions units) and user actions (e.g., head pose, distance to the camera). The multimodal system uses the following modules based on Convolutional Neural Networks (CNNs): Eye blink detection, head pose estimation, facial landmark detection, and facial expression features. First, we individually evaluate the proposed modules in the task of estimating the student's attention level captured during online e-learning sessions. For that we trained binary classifiers (high or low attention) based on Support Vector Machines (SVM) for each module. Secondly, we find out to what extent multimodal score level fusion improves the attention level estimation. The mEBAL database is used in the experimental framework, a public multi-modal database for attention level estimation obtained in an e-learning environment that contains data from 38 users while conducting several e-learning tasks of variable difficulty (creating changes in student cognitive loads).
edBB-Demo: Biometrics and Behavior Analysis for Online Educational Platforms
Dec 05, 2022

We present edBB-Demo, a demonstrator of an AI-powered research platform for student monitoring in remote education. The edBB platform aims to study the challenges associated to user recognition and behavior understanding in digital platforms. This platform has been developed for data collection, acquiring signals from a variety of sensors including keyboard, mouse, webcam, microphone, smartwatch, and an Electroencephalography band. The information captured from the sensors during the student sessions is modelled in a multimodal learning framework. The demonstrator includes: i) Biometric user authentication in an unsupervised environment; ii) Human action recognition based on remote video analysis; iii) Heart rate estimation from webcam video; and iv) Attention level estimation from facial expression analysis.
FaceQvec: Vector Quality Assessment for Face Biometrics based on ISO Compliance
Nov 03, 2021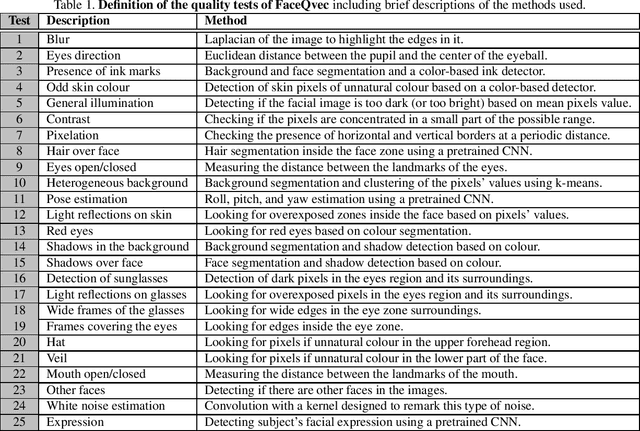

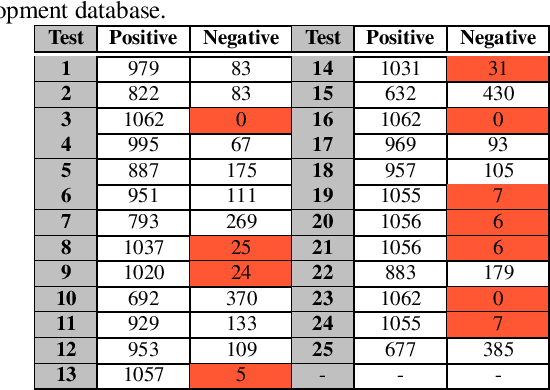
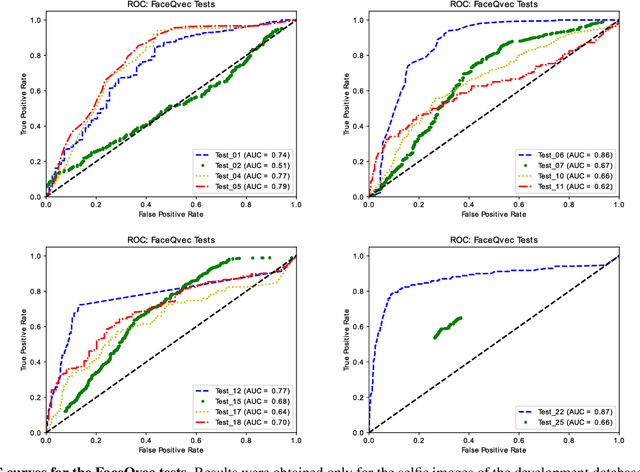
In this paper we develop FaceQvec, a software component for estimating the conformity of facial images with each of the points contemplated in the ISO/IEC 19794-5, a quality standard that defines general quality guidelines for face images that would make them acceptable or unacceptable for use in official documents such as passports or ID cards. This type of tool for quality assessment can help to improve the accuracy of face recognition, as well as to identify which factors are affecting the quality of a given face image and to take actions to eliminate or reduce those factors, e.g., with postprocessing techniques or re-acquisition of the image. FaceQvec consists of the automation of 25 individual tests related to different points contemplated in the aforementioned standard, as well as other characteristics of the images that have been considered to be related to facial quality. We first include the results of the quality tests evaluated on a development dataset captured under realistic conditions. We used those results to adjust the decision threshold of each test. Then we checked again their accuracy on a evaluation database that contains new face images not seen during development. The evaluation results demonstrate the accuracy of the individual tests for checking compliance with ISO/IEC 19794-5. FaceQvec is available online (https://github.com/uam-biometrics/FaceQvec).