 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Membership Inference Test (aMINT): Enhancing Model Auditability with Multi-Task Learning
Sep 09, 2025Active Membership Inference Test (aMINT) is a method designed to detect whether given data were used during the training of machine learning models. In Active MINT, we propose a novel multitask learning process that involves training simultaneously two models: the original or Audited Model, and a secondary model, referred to as the MINT Model, responsible for identifying the data used for training the Audited Model. This novel multi-task learning approach has been designed to incorporate the auditability of the model as an optimization objective during the training process of neural networks. The proposed approach incorporates intermediate activation maps as inputs to the MINT layers, which are trained to enhance the detection of training data. We present results using a wide range of neural networks, from lighter architectures such as MobileNet to more complex ones such as Vision Transformers, evaluated in 5 public benchmarks. Our proposed Active MINT achieves over 80% accuracy in detecting if given data was used for training, significantly outperforming previous approaches in the literature. Our aMINT and related methodological developments contribute to increasing transparency in AI models, facilitating stronger safeguards in AI deployments to achieve proper security, privacy, and copyright protection.
Are Vision-Language Models Ready for Dietary Assessment? Exploring the Next Frontier in AI-Powered Food Image Recognition
Apr 09, 2025Automatic dietary assessment based on food images remains a challenge, requiring precise food detection, segmentation, and classification. Vision-Language Models (VLMs) offer new possibilities by integrating visual and textual reasoning. In this study, we evaluate six state-of-the-art VLMs (ChatGPT, Gemini, Claude, Moondream, DeepSeek, and LLaVA), analyzing their capabilities in food recognition at different levels. For the experimental framework, we introduce the FoodNExTDB, a unique food image database that contains 9,263 expert-labeled images across 10 categories (e.g., "protein source"), 62 subcategories (e.g., "poultry"), and 9 cooking styles (e.g., "grilled"). In total, FoodNExTDB includes 50k nutritional labels generated by seven experts who manually annotated all images in the database. Also, we propose a novel evaluation metric, Expert-Weighted Recall (EWR), that accounts for the inter-annotator variability. Results show that closed-source models outperform open-source ones, achieving over 90% EWR in recognizing food products in images containing a single product. Despite their potential, current VLMs face challenges in fine-grained food recognition, particularly in distinguishing subtle differences in cooking styles and visually similar food items, which limits their reliability for automatic dietary assessment. The FoodNExTDB database is publicly available at https://github.com/AI4Food/FoodNExtDB.
KVC-onGoing: Keystroke Verification Challenge
Dec 29, 2024



This article presents the Keystroke Verification Challenge - onGoing (KVC-onGoing), on which researchers can easily benchmark their systems in a common platform using large-scale public databases, the Aalto University Keystroke databases, and a standard experimental protocol. The keystroke data consist of tweet-long sequences of variable transcript text from over 185,000 subjects, acquired through desktop and mobile keyboards simulating real-life conditions. The results on the evaluation set of KVC-onGoing have proved the high discriminative power of keystroke dynamics, reaching values as low as 3.33% of Equal Error Rate (EER) and 11.96% of False Non-Match Rate (FNMR) @1% False Match Rate (FMR) in the desktop scenario, and 3.61% of EER and 17.44% of FNMR @1% at FMR in the mobile scenario, significantly improving previous state-of-the-art results. Concerning demographic fairness, the analyzed scores reflect the subjects' age and gender to various extents, not negligible in a few cases. The framework runs on CodaLab.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
Personalized Weight Loss Management through Wearable Devices and Artificial Intelligence
Sep 13, 2024



Early detection of chronic and Non-Communicable Diseases (NCDs) is crucial for effective treatment during the initial stages. This study explores the application of wearable devices and Artificial Intelligence (AI) in order to predict weight loss changes in overweight and obese individuals. Using wearable data from a 1-month trial involving around 100 subjects from the AI4FoodDB database, including biomarkers, vital signs, and behavioral data, we identify key differences between those achieving weight loss (>= 2% of their initial weight) and those who do not. Feature selection techniques and classification algorithms reveal promising results, with the Gradient Boosting classifier achieving 84.44% Area Under the Curve (AUC). The integration of multiple data sources (e.g., vital signs, physical and sleep activity, etc.) enhances performance, suggesting the potential of wearable devices and AI in personalized healthcare.
DeepFace-Attention: Multimodal Face Biometrics for Attention Estimation with Application to e-Learning
Aug 14, 2024

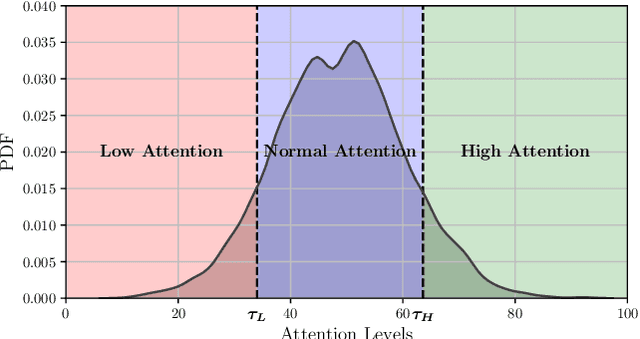

This work introduces an innovative method for estimating attention levels (cognitive load) using an ensemble of facial analysis techniques applied to webcam videos. Our method is particularly useful, among others, in e-learning applications, so we trained, evaluated, and compared our approach on the mEBAL2 database, a public multi-modal database acquired in an e-learning environment. mEBAL2 comprises data from 60 users who performed 8 different tasks. These tasks varied in difficulty, leading to changes in their cognitive loads. Our approach adapts state-of-the-art facial analysis technologies to quantify the users' cognitive load in the form of high or low attention. Several behavioral signals and physiological processes related to the cognitive load are used, such as eyeblink, heart rate, facial action units, and head pose, among others. Furthermore, we conduct a study to understand which individual features obtain better results, the most efficient combinations, explore local and global features, and how temporary time intervals affect attention level estimation, among other aspects. We find that global facial features are more appropriate for multimodal systems using score-level fusion, particularly as the temporal window increases. On the other hand, local features are more suitable for fusion through neural network training with score-level fusion approaches. Our method outperforms existing state-of-the-art accuracies using the public mEBAL2 benchmark.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
Is my Data in your AI Model? Membership Inference Test with Application to Face Images
Feb 14, 2024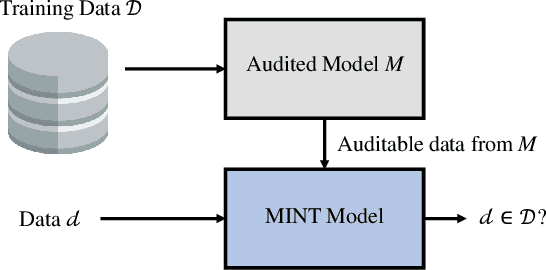

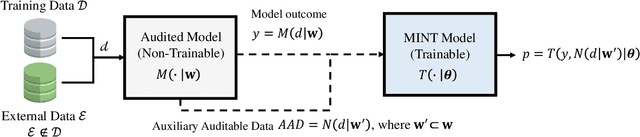

This paper introduces the Membership Inference Test (MINT), a novel approach that aims to empirically assess if specific data was used during the training of Artificial Intelligence (AI) models. Specifically, we propose two novel MINT architectures designed to learn the distinct activation patterns that emerge when an audited model is exposed to data used during its training process. The first architecture is based on a Multilayer Perceptron (MLP) network and the second one is based on Convolutional Neural Networks (CNNs). The proposed MINT architectures are evaluated on a challenging face recognition task, considering three state-of-the-art face recognition models. Experiments are carried out using six publicly available databases, comprising over 22 million face images in total. Also, different experimental scenarios are considered depending on the context available of the AI model to test. Promising results, up to 90% accuracy, are achieved using our proposed MINT approach, suggesting that it is possible to recognize if an AI model has been trained with specific data.
How Good is ChatGPT at Face Biometrics? A First Look into Recognition, Soft Biometrics, and Explainability
Jan 24, 2024Large Language Models (LLMs) such as GPT developed by OpenAI, have already shown astonishing results, introducing quick changes in our society. This has been intensified by the release of ChatGPT which allows anyone to interact in a simple conversational way with LLMs, without any experience in the field needed. As a result, ChatGPT has been rapidly applied to many different tasks such as code- and song-writer, education, virtual assistants, etc., showing impressive results for tasks for which it was not trained (zero-shot learning). The present study aims to explore the ability of ChatGPT, based on the recent GPT-4 multimodal LLM, for the task of face biometrics. In particular, we analyze the ability of ChatGPT to perform tasks such as face verification, soft-biometrics estimation, and explainability of the results. ChatGPT could be very valuable to further increase the explainability and transparency of the automatic decisions in human scenarios. Experiments are carried out in order to evaluate the performance and robustness of ChatGPT, using popular public benchmarks and comparing the results with state-of-the-art methods in the field. The results achieved in this study show the potential of LLMs such as ChatGPT for face biometrics, especially to enhance explainability. For reproducibility reasons, we release all the code in GitHub.
FRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data
Nov 17, 2023



Despite the widespread adoption of face recognition technology around the world, and its remarkable performance on current benchmarks, there are still several challenges that must be covered in more detail. This paper offers an overview of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at WACV 2024. This is the first international challenge aiming to explore the use of synthetic data in face recognition to address existing limitations in the technology. Specifically, the FRCSyn Challenge targets concerns related to data privacy issues, demographic biases, generalization to unseen scenarios, and performance limitations in challenging scenarios, including significant age disparities between enrollment and testing, pose variations, and occlusions. The results achieved in the FRCSyn Challenge, together with the proposed benchmark, contribute significantly to the application of synthetic data to improve face recognition technology.