 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Deep Learning and Ultra-Widefield Imaging for Diabetic Retinopathy and Macular Edema
Mar 09, 2026Diabetic retinopathy (DR) and diabetic macular edema (DME) are leading causes of preventable blindness among working-age adults. Traditional approaches in the literature focus on standard color fundus photography (CFP) for the detection of these conditions. Nevertheless, recent ultra-widefield imaging (UWF) offers a significantly wider field of view in comparison to CFP. Motivated by this, the present study explores state-of-the-art deep learning (DL) methods and UWF imaging on three clinically relevant tasks: i) image quality assessment for UWF, ii) identification of referable diabetic retinopathy (RDR), and iii) identification of DME. Using the publicly available UWF4DR Challenge dataset, released as part of the MICCAI 2024 conference, we benchmark DL models in the spatial (RGB) and frequency domains, including popular convolutional neural networks (CNNs) as well as recent vision transformers (ViTs) and foundation models. In addition, we explore a final feature-level fusion to increase robustness. Finally, we also analyze the decisions of the DL models using Grad-CAM, increasing the explainability. Our proposal achieves consistently strong performance across all architectures, underscoring the competitiveness of emerging ViTs and foundation models and the promise of feature-level fusion and frequency-domain representations for UWF analysis.
Are Vision-Language Models Ready for Dietary Assessment? Exploring the Next Frontier in AI-Powered Food Image Recognition
Apr 09, 2025Automatic dietary assessment based on food images remains a challenge, requiring precise food detection, segmentation, and classification. Vision-Language Models (VLMs) offer new possibilities by integrating visual and textual reasoning. In this study, we evaluate six state-of-the-art VLMs (ChatGPT, Gemini, Claude, Moondream, DeepSeek, and LLaVA), analyzing their capabilities in food recognition at different levels. For the experimental framework, we introduce the FoodNExTDB, a unique food image database that contains 9,263 expert-labeled images across 10 categories (e.g., "protein source"), 62 subcategories (e.g., "poultry"), and 9 cooking styles (e.g., "grilled"). In total, FoodNExTDB includes 50k nutritional labels generated by seven experts who manually annotated all images in the database. Also, we propose a novel evaluation metric, Expert-Weighted Recall (EWR), that accounts for the inter-annotator variability. Results show that closed-source models outperform open-source ones, achieving over 90% EWR in recognizing food products in images containing a single product. Despite their potential, current VLMs face challenges in fine-grained food recognition, particularly in distinguishing subtle differences in cooking styles and visually similar food items, which limits their reliability for automatic dietary assessment. The FoodNExTDB database is publicly available at https://github.com/AI4Food/FoodNExtDB.
Personalized Weight Loss Management through Wearable Devices and Artificial Intelligence
Sep 13, 2024



Early detection of chronic and Non-Communicable Diseases (NCDs) is crucial for effective treatment during the initial stages. This study explores the application of wearable devices and Artificial Intelligence (AI) in order to predict weight loss changes in overweight and obese individuals. Using wearable data from a 1-month trial involving around 100 subjects from the AI4FoodDB database, including biomarkers, vital signs, and behavioral data, we identify key differences between those achieving weight loss (>= 2% of their initial weight) and those who do not. Feature selection techniques and classification algorithms reveal promising results, with the Gradient Boosting classifier achieving 84.44% Area Under the Curve (AUC). The integration of multiple data sources (e.g., vital signs, physical and sleep activity, etc.) enhances performance, suggesting the potential of wearable devices and AI in personalized healthcare.
AI4Food-NutritionFW: A Novel Framework for the Automatic Synthesis and Analysis of Eating Behaviours
Sep 12, 2023



Nowadays millions of images are shared on social media and web platforms. In particular, many of them are food images taken from a smartphone over time, providing information related to the individual's diet. On the other hand, eating behaviours are directly related to some of the most prevalent diseases in the world. Exploiting recent advances in image processing and Artificial Intelligence (AI), this scenario represents an excellent opportunity to: i) create new methods that analyse the individuals' health from what they eat, and ii) develop personalised recommendations to improve nutrition and diet under specific circumstances (e.g., obesity or COVID). Having tunable tools for creating food image datasets that facilitate research in both lines is very much needed. This paper proposes AI4Food-NutritionFW, a framework for the creation of food image datasets according to configurable eating behaviours. AI4Food-NutritionFW simulates a user-friendly and widespread scenario where images are taken using a smartphone. In addition to the framework, we also provide and describe a unique food image dataset that includes 4,800 different weekly eating behaviours from 15 different profiles and 1,200 subjects. Specifically, we consider profiles that comply with actual lifestyles from healthy eating behaviours (according to established knowledge), variable profiles (e.g., eating out, holidays), to unhealthy ones (e.g., excess of fast food or sweets). Finally, we automatically evaluate a healthy index of the subject's eating behaviours using multidimensional metrics based on guidelines for healthy diets proposed by international organisations, achieving promising results (99.53% and 99.60% accuracy and sensitivity, respectively). We also release to the research community a software implementation of our proposed AI4Food-NutritionFW and the mentioned food image dataset created with it.
AI4Food-NutritionDB: Food Image Database, Nutrition Taxonomy, and Recognition Benchmark
Nov 14, 2022Leading a healthy lifestyle has become one of the most challenging goals in today's society due to our sedentary lifestyle and poor eating habits. As a result, national and international organisms have made numerous efforts to promote healthier food diets and physical activity habits. However, these recommendations are sometimes difficult to follow in our daily life and they are also based on a general population. As a consequence, a new area of research, personalised nutrition, has been conceived focusing on individual solutions through smart devices and Artificial Intelligence (AI) methods. This study presents the AI4Food-NutritionDB database, the first nutrition database that considers food images and a nutrition taxonomy based on recommendations by national and international organisms. In addition, four different categorisation levels are considered following nutrition experts: 6 nutritional levels, 19 main categories (e.g., "Meat"), 73 subcategories (e.g., "White Meat"), and 893 final food products (e.g., "Chicken"). The AI4Food-NutritionDB opens the doors to new food computing approaches in terms of food intake frequency, quality, and categorisation. Also, in addition to the database, we propose a standard experimental protocol and benchmark including three tasks based on the nutrition taxonomy (i.e., category, subcategory, and final product) to be used for the research community. Finally, we also release our Deep Learning models trained with the AI4Food-NutritionDB, which can be used as pre-trained models, achieving accurate recognition results with challenging food image databases.
SVC-onGoing: Signature Verification Competition
Aug 13, 2021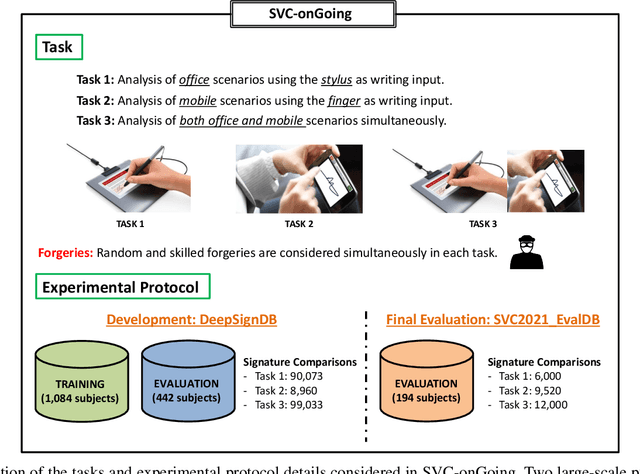
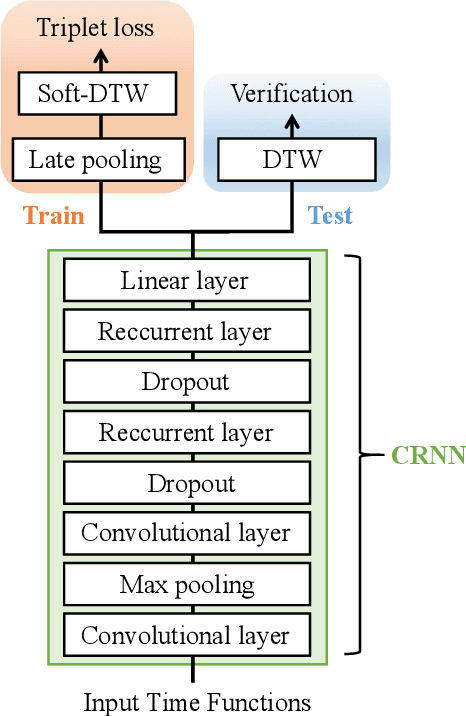


This article presents SVC-onGoing, an on-going competition for on-line signature verification where researchers can easily benchmark their systems against the state of the art in an open common platform using large-scale public databases, such as DeepSignDB and SVC2021_EvalDB, and standard experimental protocols. SVC-onGoing is based on the ICDAR 2021 Competition on On-Line Signature Verification (SVC 2021), which has been extended to allow participants anytime. The goal of SVC-onGoing is to evaluate the limits of on-line signature verification systems on popular scenarios (office/mobile) and writing inputs (stylus/finger) through large-scale public databases. Three different tasks are considered in the competition, simulating realistic scenarios as both random and skilled forgeries are simultaneously considered on each task. The results obtained in SVC-onGoing prove the high potential of deep learning methods in comparison with traditional methods. In particular, the best signature verification system has obtained Equal Error Rate (EER) values of 3.33% (Task 1), 7.41% (Task 2), and 6.04% (Task 3). Future studies in the field should be oriented to improve the performance of signature verification systems on the challenging mobile scenarios of SVC-onGoing in which several mobile devices and the finger are used during the signature acquisition.
ICDAR 2021 Competition on On-Line Signature Verification
Jun 01, 2021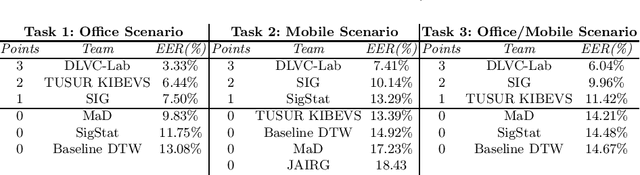
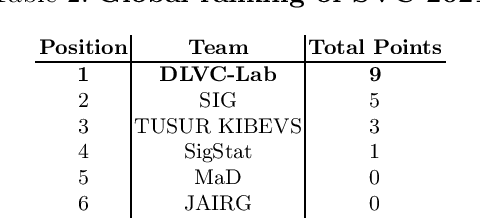
This paper describes the experimental framework and results of the ICDAR 2021 Competition on On-Line Signature Verification (SVC 2021). The goal of SVC 2021 is to evaluate the limits of on-line signature verification systems on popular scenarios (office/mobile) and writing inputs (stylus/finger) through large-scale public databases. Three different tasks are considered in the competition, simulating realistic scenarios as both random and skilled forgeries are simultaneously considered on each task. The results obtained in SVC 2021 prove the high potential of deep learning methods. In particular, the best on-line signature verification system of SVC 2021 obtained Equal Error Rate (EER) values of 3.33% (Task 1), 7.41% (Task 2), and 6.04% (Task 3). SVC 2021 will be established as an on-going competition, where researchers can easily benchmark their systems against the state of the art in an open common platform using large-scale public databases such as DeepSignDB and SVC2021_EvalDB, and standard experimental protocols.
Child-Computer Interaction: Recent Works, New Dataset, and Age Detection
Feb 02, 2021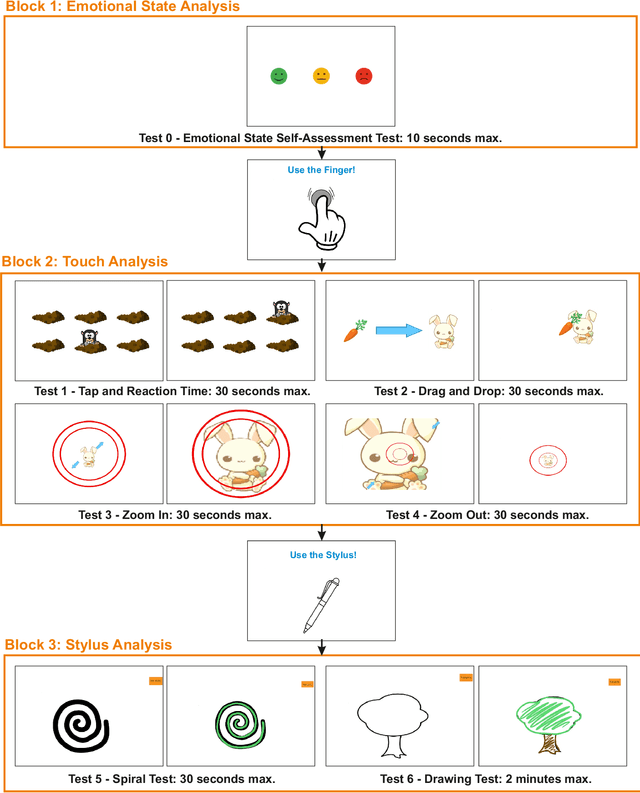
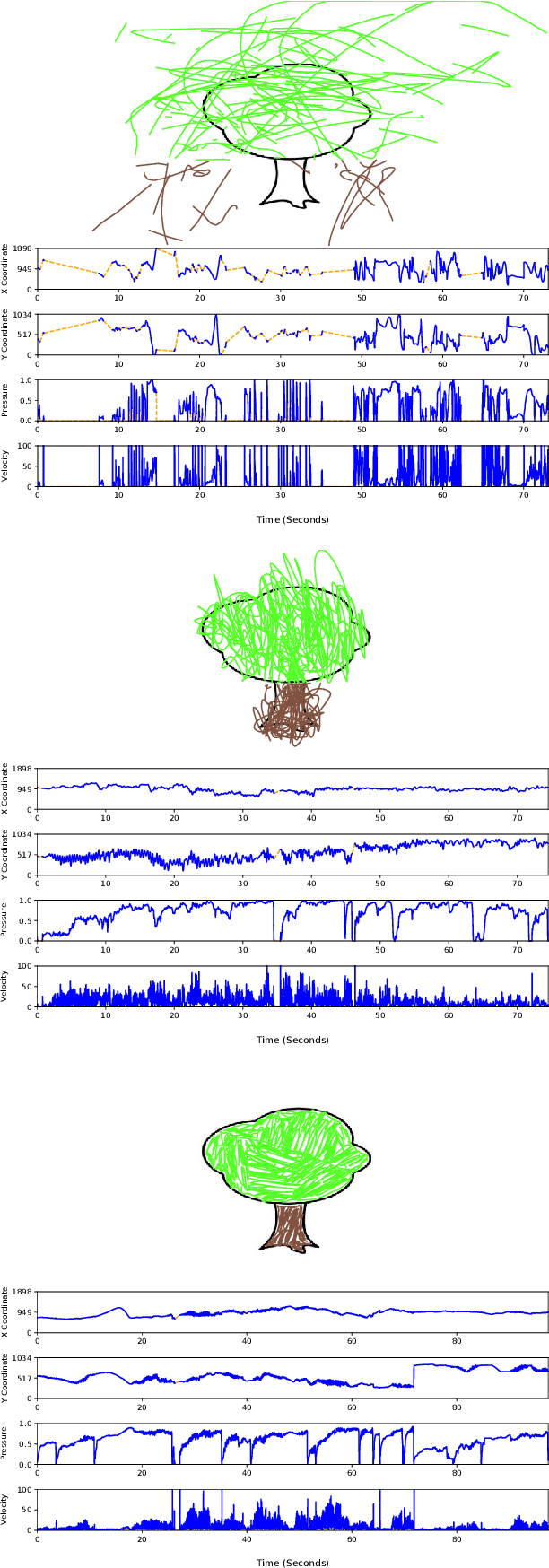
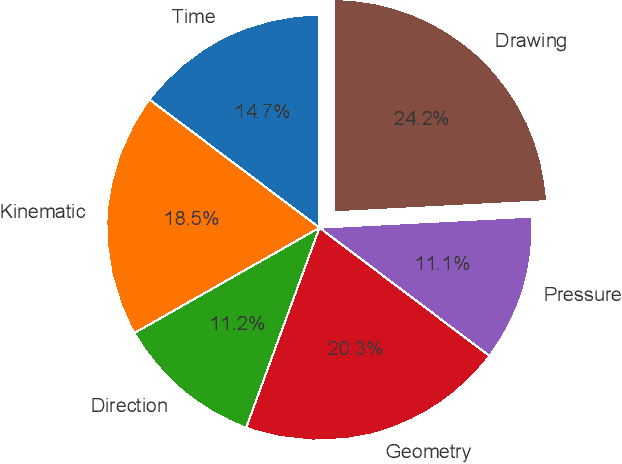
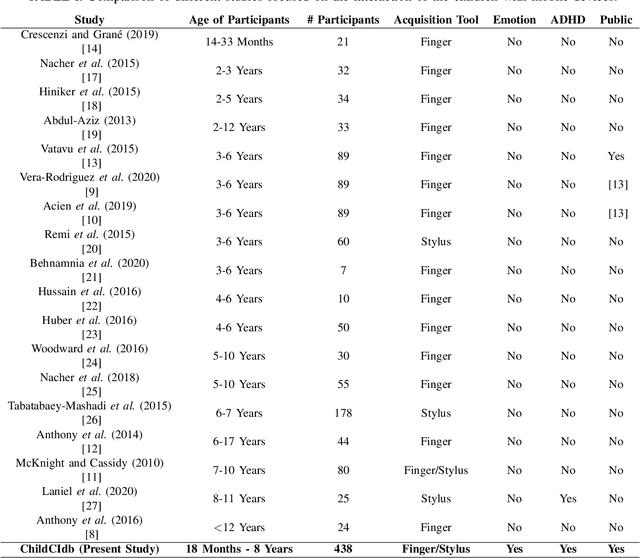
We overview recent research in Child-Computer Interaction and describe our framework ChildCI intended for: i) generating a better understanding of the cognitive and neuromotor development of children while interacting with mobile devices, and ii) enabling new applications in e-learning and e-health, among others. Our framework includes a new mobile application, specific data acquisition protocols, and a first release of the ChildCI dataset (ChildCIdb v1), which is planned to be extended yearly to enable longitudinal studies. In our framework children interact with a tablet device, using both a pen stylus and the finger, performing different tasks that require different levels of neuromotor and cognitive skills. ChildCIdb comprises more than 400 children from 18 months to 8 years old, considering therefore the first three development stages of the Piaget's theory. In addition, and as a demonstration of the potential of the ChildCI framework, we include experimental results for one of the many applications enabled by ChildCIdb: children age detection based on device interaction. Different machine learning approaches are evaluated, proposing a new set of 34 global features to automatically detect age groups, achieving accuracy results over 90% and interesting findings in terms of the type of features more useful for this task.
DeepFakes Evolution: Analysis of Facial Regions and Fake Detection Performance
Apr 16, 2020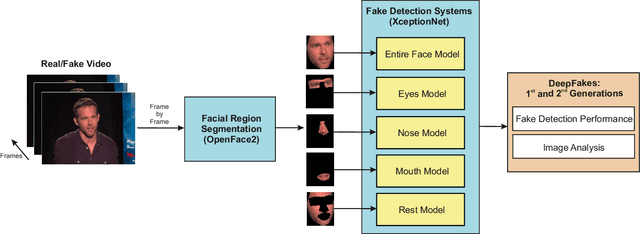
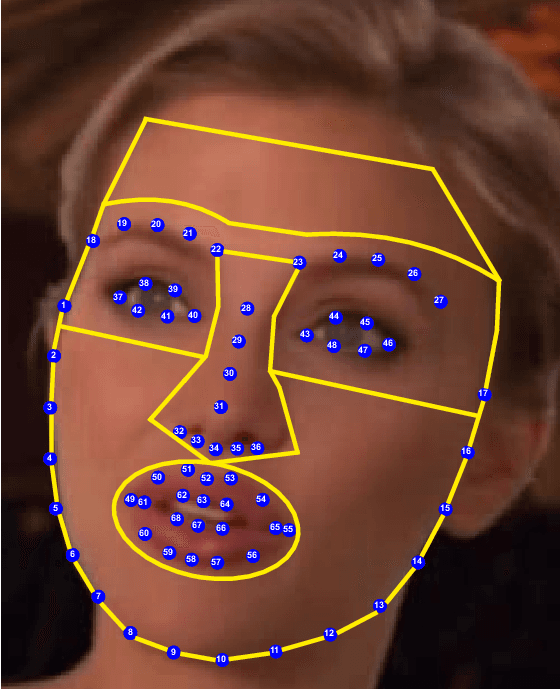
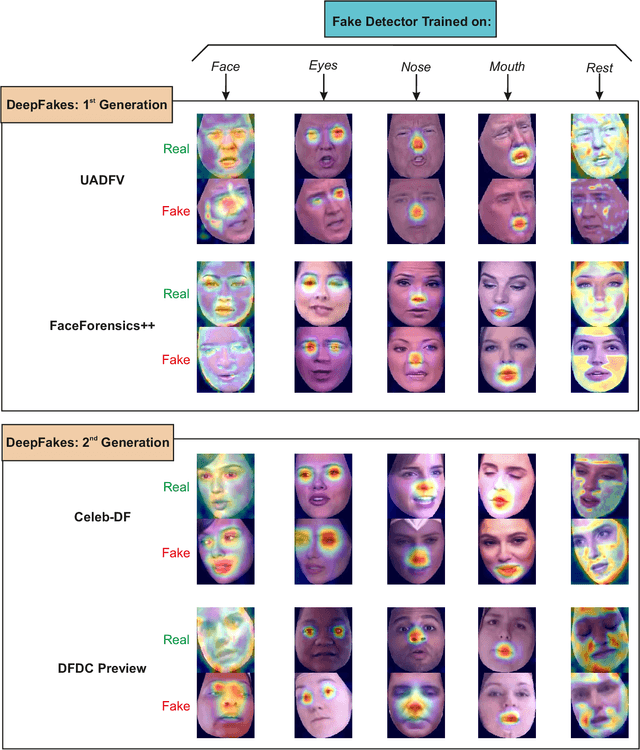

Media forensics has attracted a lot of attention in the last years in part due to the increasing concerns around DeepFakes. Since the initial DeepFake databases from the 1st generation such as UADFV and FaceForensics++ up to the latest databases of the 2nd generation such as Celeb-DF and DFDC, many visual improvements have been carried out, making fake videos almost indistinguishable to the human eye. This study provides an exhaustive analysis of both 1st and 2nd DeepFake generations in terms of facial regions and fake detection performance. Two different approaches are considered in our experimental framework: i) selecting the entire face as input to the fake detection system, and ii) selecting specific facial regions such as the eyes or nose, among others, as input to the fake detection system. Among all the findings resulting from our experiments, we highlight the poor fake detection results achieved even by the strongest state-of-the-art fake detectors in the latest DeepFake databases of the 2nd generation, with Equal Error Rate results ranging from 15% to 30%. These results remark the necessity of further research in order to develop more sophisticated fake detection systems.