 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Avatar Fingerprinting: A Multi-Generator Photorealistic Talking-Head Public Database and Benchmark
Mar 27, 2026Recent advances in photorealistic avatar generation have enabled highly realistic talking-head avatars, raising security concerns regarding identity impersonation in AI-mediated communication. To advance in this challenging problem, the task of avatar fingerprinting aims to determine whether two avatar videos are driven by the same human operator or not. However, current public databases in the literature are scarce and based solely on old-fashioned talking-head avatar generators, not representing realistic scenarios for the current task of avatar fingerprinting. To overcome this situation, the present article introduces AVAPrintDB, a new publicly available multi-generator talking-head avatar database for avatar fingerprinting. AVAPrintDB is constructed from two audiovisual corpora and three state-of-the-art avatar generators (GAGAvatar, LivePortrait, HunyuanPortrait), representing different synthesis paradigms, and includes both self- and cross-reenactments to simulate legitimate usage and impersonation scenarios. Building on this database, we also define a standardized and reproducible benchmark for avatar fingerprinting, considering public state-of-the-art avatar fingerprinting systems and exploring novel methods based on Foundation Models (DINOv2 and CLIP). Also, we conduct a comprehensive analysis under generator and dataset shift. Our results show that, while identity-related motion cues persist across synthetic avatars, current avatar fingerprinting systems remain highly sensitive to changes in the synthesis pipeline and source domain. The AVAPrintDB, benchmark protocols, and avatar fingerprinting systems are publicly available to facilitate reproducible research.
Longitudinal Digital Phenotyping for Early Cognitive-Motor Screening
Mar 26, 2026Early detection of atypical cognitive-motor development is critical for timely intervention, yet traditional assessments rely heavily on subjective, static evaluations. The integration of digital devices offers an opportunity for continuous, objective monitoring through digital biomarkers. In this work, we propose an AI-driven longitudinal framework to model developmental trajectories in children aged 18 months to 8 years. Using a dataset of tablet-based interactions collected over multiple academic years, we analyzed six cognitive-motor tasks (e.g., fine motor control, reaction time). We applied dimensionality reduction (t-SNE) and unsupervised clustering (K-Means++) to identify distinct developmental phenotypes and tracked individual transitions between these profiles over time. Our analysis reveals three distinct profiles: low, medium, and high performance. Crucially, longitudinal tracking highlights a high stability in the low-performance cluster (>90% retention in early years), suggesting that early deficits tend to persist without intervention. Conversely, higher-performance clusters show greater variability, potentially reflecting engagement factors. This study validates the use of unsupervised learning on touchscreen data to uncover heterogeneous developmental paths. The identified profiles serve as scalable, data-driven proxies for cognitive growth, offering a foundation for early screening tools and personalized pediatric interventions.
Exploring Deep Learning and Ultra-Widefield Imaging for Diabetic Retinopathy and Macular Edema
Mar 09, 2026Diabetic retinopathy (DR) and diabetic macular edema (DME) are leading causes of preventable blindness among working-age adults. Traditional approaches in the literature focus on standard color fundus photography (CFP) for the detection of these conditions. Nevertheless, recent ultra-widefield imaging (UWF) offers a significantly wider field of view in comparison to CFP. Motivated by this, the present study explores state-of-the-art deep learning (DL) methods and UWF imaging on three clinically relevant tasks: i) image quality assessment for UWF, ii) identification of referable diabetic retinopathy (RDR), and iii) identification of DME. Using the publicly available UWF4DR Challenge dataset, released as part of the MICCAI 2024 conference, we benchmark DL models in the spatial (RGB) and frequency domains, including popular convolutional neural networks (CNNs) as well as recent vision transformers (ViTs) and foundation models. In addition, we explore a final feature-level fusion to increase robustness. Finally, we also analyze the decisions of the DL models using Grad-CAM, increasing the explainability. Our proposal achieves consistently strong performance across all architectures, underscoring the competitiveness of emerging ViTs and foundation models and the promise of feature-level fusion and frequency-domain representations for UWF analysis.
EduEVAL-DB: A Role-Based Dataset for Pedagogical Risk Evaluation in Educational Explanations
Feb 19, 2026This work introduces EduEVAL-DB, a dataset based on teacher roles designed to support the evaluation and training of automatic pedagogical evaluators and AI tutors for instructional explanations. The dataset comprises 854 explanations corresponding to 139 questions from a curated subset of the ScienceQA benchmark, spanning science, language, and social science across K-12 grade levels. For each question, one human-teacher explanation is provided and six are generated by LLM-simulated teacher roles. These roles are inspired by instructional styles and shortcomings observed in real educational practice and are instantiated via prompt engineering. We further propose a pedagogical risk rubric aligned with established educational standards, operationalizing five complementary risk dimensions: factual correctness, explanatory depth and completeness, focus and relevance, student-level appropriateness, and ideological bias. All explanations are annotated with binary risk labels through a semi-automatic process with expert teacher review. Finally, we present preliminary validation experiments to assess the suitability of EduEVAL-DB for evaluation. We benchmark a state-of-the-art education-oriented model (Gemini 2.5 Pro) against a lightweight local Llama 3.1 8B model and examine whether supervised fine-tuning on EduEVAL-DB supports pedagogical risk detection using models deployable on consumer hardware.
GenAI-LA: Generative AI and Learning Analytics Workshop (LAK 2026), April 27--May 1, 2026, Bergen, Norway
Feb 17, 2026This work introduces EduEVAL-DB, a dataset based on teacher roles designed to support the evaluation and training of automatic pedagogical evaluators and AI tutors for instructional explanations. The dataset comprises 854 explanations corresponding to 139 questions from a curated subset of the ScienceQA benchmark, spanning science, language, and social science across K-12 grade levels. For each question, one human-teacher explanation is provided and six are generated by LLM-simulated teacher roles. These roles are inspired by instructional styles and shortcomings observed in real educational practice and are instantiated via prompt engineering. We further propose a pedagogical risk rubric aligned with established educational standards, operationalizing five complementary risk dimensions: factual correctness, explanatory depth and completeness, focus and relevance, student-level appropriateness, and ideological bias. All explanations are annotated with binary risk labels through a semi-automatic process with expert teacher review. Finally, we present preliminary validation experiments to assess the suitability of EduEVAL-DB for evaluation. We benchmark a state-of-the-art education-oriented model (Gemini 2.5 Pro) against a lightweight local Llama 3.1 8B model and examine whether supervised fine-tuning on EduEVAL-DB supports pedagogical risk detection using models deployable on consumer hardware.
Membership Inference Test: Auditing Training Data in Object Classification Models
Jan 19, 2026In this research, we analyze the performance of Membership Inference Tests (MINT), focusing on determining whether given data were utilized during the training phase, specifically in the domain of object recognition. Within the area of object recognition, we propose and develop architectures tailored for MINT models. These architectures aim to optimize performance and efficiency in data utilization, offering a tailored solution to tackle the complexities inherent in the object recognition domain. We conducted experiments involving an object detection model, an embedding extractor, and a MINT module. These experiments were performed in three public databases, totaling over 174K images. The proposed architecture leverages convolutional layers to capture and model the activation patterns present in the data during the training process. Through our analysis, we are able to identify given data used for testing and training, achieving precision rates ranging between 70% and 80%, contingent upon the depth of the detection module layer chosen for input to the MINT module. Additionally, our studies entail an analysis of the factors influencing the MINT Module, delving into the contributing elements behind more transparent training processes.
Is Visual Realism Enough? Evaluating Gait Biometric Fidelity in Generative AI Human Animation
Dec 22, 2025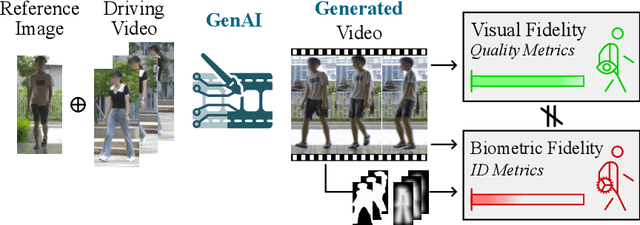

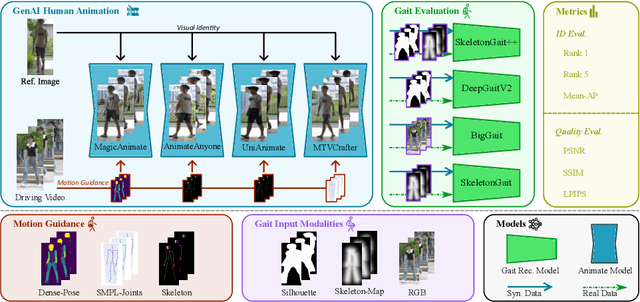
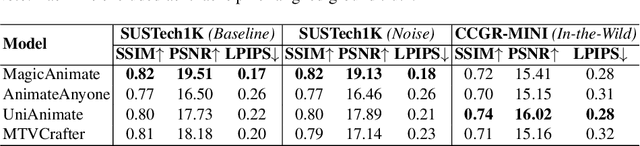
Generative AI (GenAI) models have revolutionized animation, enabling the synthesis of humans and motion patterns with remarkable visual fidelity. However, generating truly realistic human animation remains a formidable challenge, where even minor inconsistencies can make a subject appear unnatural. This limitation is particularly critical when AI-generated videos are evaluated for behavioral biometrics, where subtle motion cues that define identity are easily lost or distorted. The present study investigates whether state-of-the-art GenAI human animation models can preserve the subtle spatio-temporal details needed for person identification through gait biometrics. Specifically, we evaluate four different GenAI models across two primary evaluation tasks to assess their ability to i) restore gait patterns from reference videos under varying conditions of complexity, and ii) transfer these gait patterns to different visual identities. Our results show that while visual quality is mostly high, biometric fidelity remains low in tasks focusing on identification, suggesting that current GenAI models struggle to disentangle identity from motion. Furthermore, through an identity transfer task, we expose a fundamental flaw in appearance-based gait recognition: when texture is disentangled from motion, identification collapses, proving current GenAI models rely on visual attributes rather than temporal dynamics.
Active Membership Inference Test (aMINT): Enhancing Model Auditability with Multi-Task Learning
Sep 09, 2025Active Membership Inference Test (aMINT) is a method designed to detect whether given data were used during the training of machine learning models. In Active MINT, we propose a novel multitask learning process that involves training simultaneously two models: the original or Audited Model, and a secondary model, referred to as the MINT Model, responsible for identifying the data used for training the Audited Model. This novel multi-task learning approach has been designed to incorporate the auditability of the model as an optimization objective during the training process of neural networks. The proposed approach incorporates intermediate activation maps as inputs to the MINT layers, which are trained to enhance the detection of training data. We present results using a wide range of neural networks, from lighter architectures such as MobileNet to more complex ones such as Vision Transformers, evaluated in 5 public benchmarks. Our proposed Active MINT achieves over 80% accuracy in detecting if given data was used for training, significantly outperforming previous approaches in the literature. Our aMINT and related methodological developments contribute to increasing transparency in AI models, facilitating stronger safeguards in AI deployments to achieve proper security, privacy, and copyright protection.
Is It Really You? Exploring Biometric Verification Scenarios in Photorealistic Talking-Head Avatar Videos
Aug 01, 2025



Photorealistic talking-head avatars are becoming increasingly common in virtual meetings, gaming, and social platforms. These avatars allow for more immersive communication, but they also introduce serious security risks. One emerging threat is impersonation: an attacker can steal a user's avatar-preserving their appearance and voice-making it nearly impossible to detect its fraudulent usage by sight or sound alone. In this paper, we explore the challenge of biometric verification in such avatar-mediated scenarios. Our main question is whether an individual's facial motion patterns can serve as reliable behavioral biometrics to verify their identity when the avatar's visual appearance is a facsimile of its owner. To answer this question, we introduce a new dataset of realistic avatar videos created using a state-of-the-art one-shot avatar generation model, GAGAvatar, with genuine and impostor avatar videos. We also propose a lightweight, explainable spatio-temporal Graph Convolutional Network architecture with temporal attention pooling, that uses only facial landmarks to model dynamic facial gestures. Experimental results demonstrate that facial motion cues enable meaningful identity verification with AUC values approaching 80%. The proposed benchmark and biometric system are available for the research community in order to bring attention to the urgent need for more advanced behavioral biometric defenses in avatar-based communication systems.
Addressing Bias in LLMs: Strategies and Application to Fair AI-based Recruitment
Jun 13, 2025The use of language technologies in high-stake settings is increasing in recent years, mostly motivated by the success of Large Language Models (LLMs). However, despite the great performance of LLMs, they are are susceptible to ethical concerns, such as demographic biases, accountability, or privacy. This work seeks to analyze the capacity of Transformers-based systems to learn demographic biases present in the data, using a case study on AI-based automated recruitment. We propose a privacy-enhancing framework to reduce gender information from the learning pipeline as a way to mitigate biased behaviors in the final tools. Our experiments analyze the influence of data biases on systems built on two different LLMs, and how the proposed framework effectively prevents trained systems from reproducing the bias in the data.