 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeceptive Beauty: Evaluating the Impact of Beauty Filters on Deepfake and Morphing Attack Detection
Sep 17, 2025
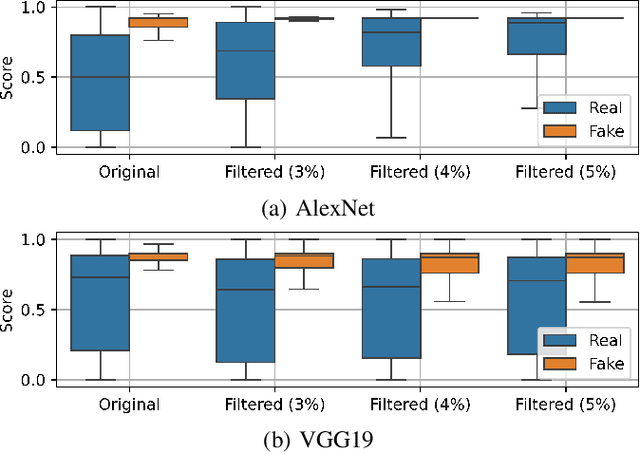
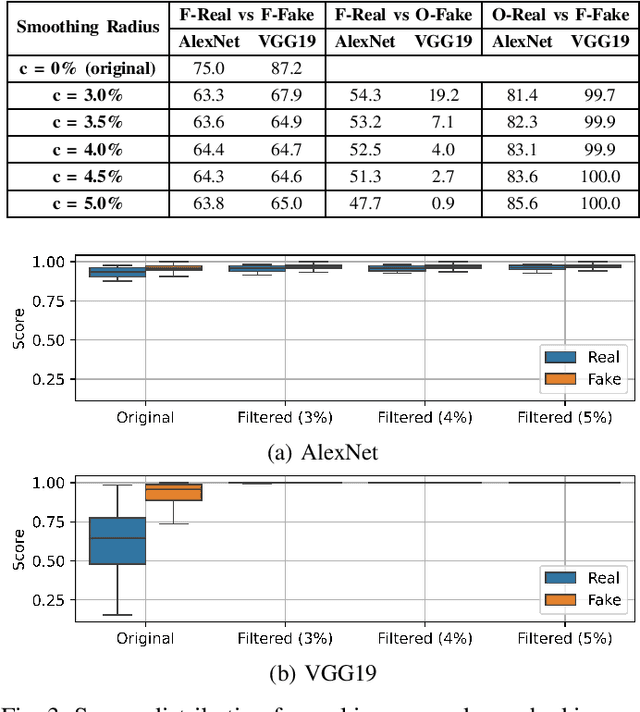

Digital beautification through social media filters has become increasingly popular, raising concerns about the reliability of facial images and videos and the effectiveness of automated face analysis. This issue is particularly critical for digital manipulation detectors, systems aiming at distinguishing between genuine and manipulated data, especially in cases involving deepfakes and morphing attacks designed to deceive humans and automated facial recognition. This study examines whether beauty filters impact the performance of deepfake and morphing attack detectors. We perform a comprehensive analysis, evaluating multiple state-of-the-art detectors on benchmark datasets before and after applying various smoothing filters. Our findings reveal performance degradation, highlighting vulnerabilities introduced by facial enhancements and underscoring the need for robust detection models resilient to such alterations.
Exploiting Multiple Representations: 3D Face Biometrics Fusion with Application to Surveillance
Apr 26, 2025



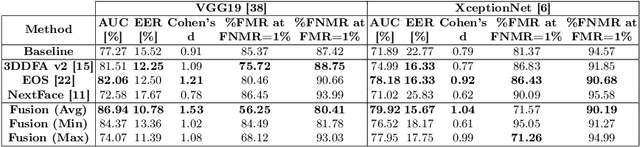
3D face reconstruction (3DFR) algorithms are based on specific assumptions tailored to the limits and characteristics of the different application scenarios. In this study, we investigate how multiple state-of-the-art 3DFR algorithms can be used to generate a better representation of subjects, with the final goal of improving the performance of face recognition systems in challenging uncontrolled scenarios. We also explore how different parametric and non-parametric score-level fusion methods can exploit the unique strengths of multiple 3DFR algorithms to enhance biometric recognition robustness. With this goal, we propose a comprehensive analysis of several face recognition systems across diverse conditions, such as varying distances and camera setups, intra-dataset and cross-dataset, to assess the robustness of the proposed ensemble method. The results demonstrate that the distinct information provided by different 3DFR algorithms can alleviate the problem of generalizing over multiple application scenarios. In addition, the present study highlights the potential of advanced fusion strategies to enhance the reliability of 3DFR-based face recognition systems, providing the research community with key insights to exploit them in real-world applications effectively. Although the experiments are carried out in a specific face verification setup, our proposed fusion-based 3DFR methods may be applied to other tasks around face biometrics that are not strictly related to identity recognition.
Exploring 3D Face Reconstruction and Fusion Methods for Face Verification: A Case-Study in Video Surveillance
Sep 16, 2024
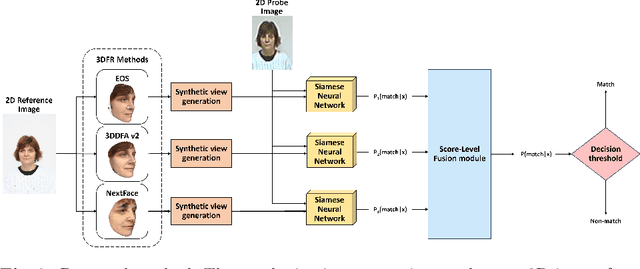
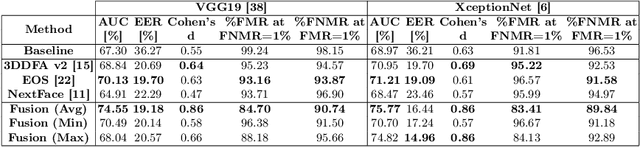
3D face reconstruction (3DFR) algorithms are based on specific assumptions tailored to distinct application scenarios. These assumptions limit their use when acquisition conditions, such as the subject's distance from the camera or the camera's characteristics, are different than expected, as typically happens in video surveillance. Additionally, 3DFR algorithms follow various strategies to address the reconstruction of a 3D shape from 2D data, such as statistical model fitting, photometric stereo, or deep learning. In the present study, we explore the application of three 3DFR algorithms representative of the SOTA, employing each one as the template set generator for a face verification system. The scores provided by each system are combined by score-level fusion. We show that the complementarity induced by different 3DFR algorithms improves performance when tests are conducted at never-seen-before distances from the camera and camera characteristics (cross-distance and cross-camera settings), thus encouraging further investigations on multiple 3DFR-based approaches.
SDFR: Synthetic Data for Face Recognition Competition
Apr 09, 2024



Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.
LivDet2023 -- Fingerprint Liveness Detection Competition: Advancing Generalization
Sep 27, 2023



The International Fingerprint Liveness Detection Competition (LivDet) is a biennial event that invites academic and industry participants to prove their advancements in Fingerprint Presentation Attack Detection (PAD). This edition, LivDet2023, proposed two challenges, Liveness Detection in Action and Fingerprint Representation, to evaluate the efficacy of PAD embedded in verification systems and the effectiveness and compactness of feature sets. A third, hidden challenge is the inclusion of two subsets in the training set whose sensor information is unknown, testing participants ability to generalize their models. Only bona fide fingerprint samples were provided to participants, and the competition reports and assesses the performance of their algorithms suffering from this limitation in data availability.
LivDet 2021 Fingerprint Liveness Detection Competition -- Into the unknown
Aug 23, 2021
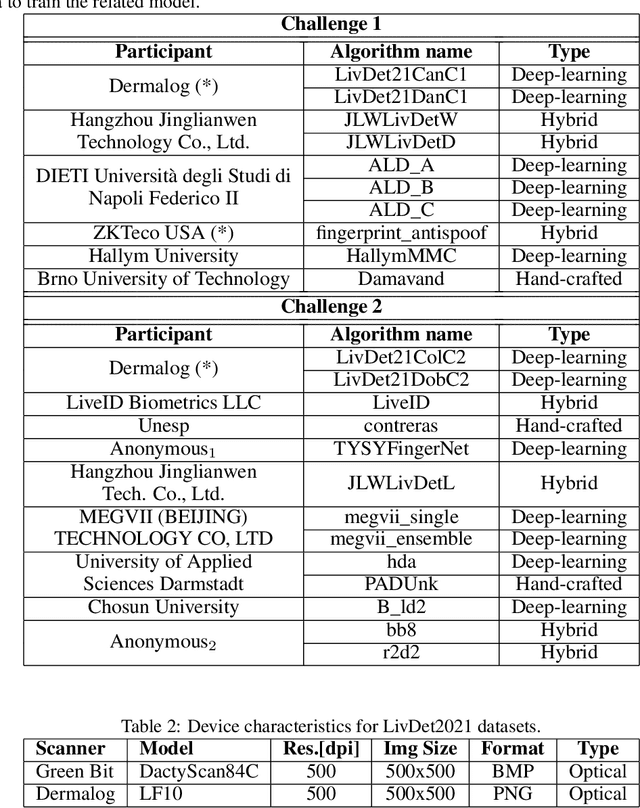


The International Fingerprint Liveness Detection Competition is an international biennial competition open to academia and industry with the aim to assess and report advances in Fingerprint Presentation Attack Detection. The proposed "Liveness Detection in Action" and "Fingerprint representation" challenges were aimed to evaluate the impact of a PAD embedded into a verification system, and the effectiveness and compactness of feature sets for mobile applications. Furthermore, we experimented a new spoof fabrication method that has particularly affected the final results. Twenty-three algorithms were submitted to the competition, the maximum number ever achieved by LivDet.
* Preprint version of a paper accepted at IJCB 2021