 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecond FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
SDFR: Synthetic Data for Face Recognition Competition
Apr 09, 2024



Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.
Model Pairing Using Embedding Translation for Backdoor Attack Detection on Open-Set Classification Tasks
Feb 28, 2024



Backdoor attacks allow an attacker to embed a specific vulnerability in a machine learning algorithm, activated when an attacker-chosen pattern is presented, causing a specific misprediction. The need to identify backdoors in biometric scenarios has led us to propose a novel technique with different trade-offs. In this paper we propose to use model pairs on open-set classification tasks for detecting backdoors. Using a simple linear operation to project embeddings from a probe model's embedding space to a reference model's embedding space, we can compare both embeddings and compute a similarity score. We show that this score, can be an indicator for the presence of a backdoor despite models being of different architectures, having been trained independently and on different datasets. Additionally, we show that backdoors can be detected even when both models are backdoored. The source code is made available for reproducibility purposes.
FRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data
Nov 17, 2023



Despite the widespread adoption of face recognition technology around the world, and its remarkable performance on current benchmarks, there are still several challenges that must be covered in more detail. This paper offers an overview of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at WACV 2024. This is the first international challenge aiming to explore the use of synthetic data in face recognition to address existing limitations in the technology. Specifically, the FRCSyn Challenge targets concerns related to data privacy issues, demographic biases, generalization to unseen scenarios, and performance limitations in challenging scenarios, including significant age disparities between enrollment and testing, pose variations, and occlusions. The results achieved in the FRCSyn Challenge, together with the proposed benchmark, contribute significantly to the application of synthetic data to improve face recognition technology.
An anomaly detection approach for backdoored neural networks: face recognition as a case study
Aug 22, 2022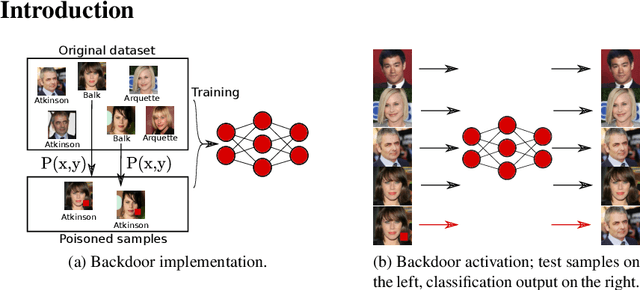
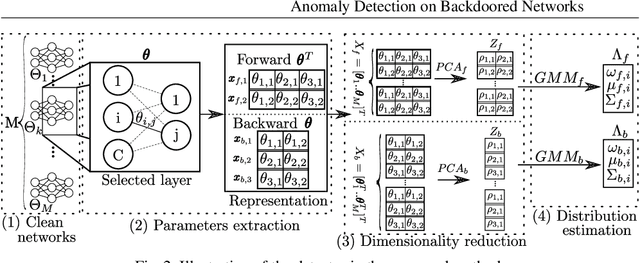
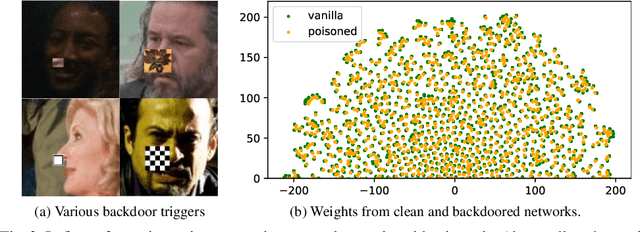

Backdoor attacks allow an attacker to embed functionality jeopardizing proper behavior of any algorithm, machine learning or not. This hidden functionality can remain inactive for normal use of the algorithm until activated by the attacker. Given how stealthy backdoor attacks are, consequences of these backdoors could be disastrous if such networks were to be deployed for applications as critical as border or access control. In this paper, we propose a novel backdoored network detection method based on the principle of anomaly detection, involving access to the clean part of the training data and the trained network. We highlight its promising potential when considering various triggers, locations and identity pairs, without the need to make any assumptions on the nature of the backdoor and its setup. We test our method on a novel dataset of backdoored networks and report detectability results with perfect scores.
DMD: A Large-Scale Multi-Modal Driver Monitoring Dataset for Attention and Alertness Analysis
Aug 27, 2020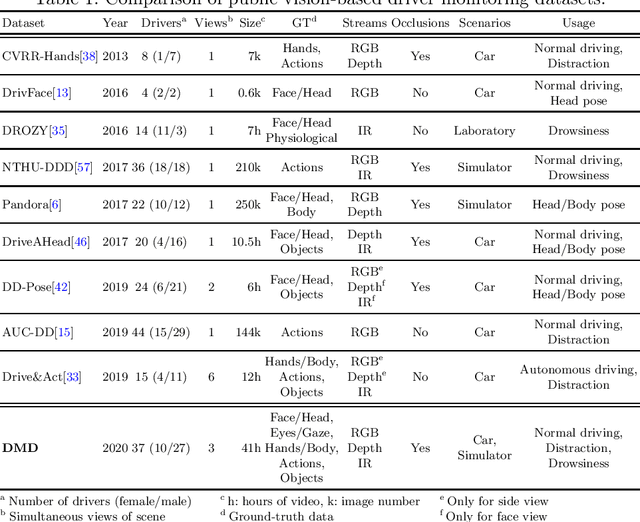
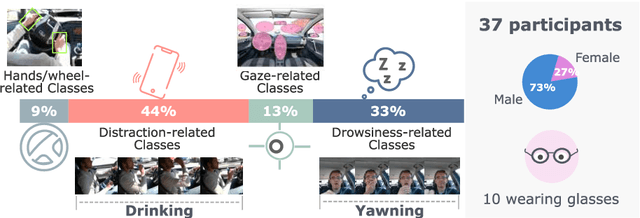
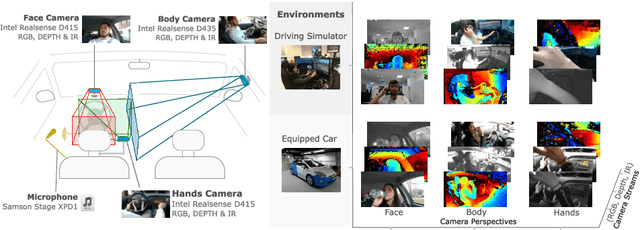

Vision is the richest and most cost-effective technology for Driver Monitoring Systems (DMS), especially after the recent success of Deep Learning (DL) methods. The lack of sufficiently large and comprehensive datasets is currently a bottleneck for the progress of DMS development, crucial for the transition of automated driving from SAE Level-2 to SAE Level-3. In this paper, we introduce the Driver Monitoring Dataset (DMD), an extensive dataset which includes real and simulated driving scenarios: distraction, gaze allocation, drowsiness, hands-wheel interaction and context data, in 41 hours of RGB, depth and IR videos from 3 cameras capturing face, body and hands of 37 drivers. A comparison with existing similar datasets is included, which shows the DMD is more extensive, diverse, and multi-purpose. The usage of the DMD is illustrated by extracting a subset of it, the dBehaviourMD dataset, containing 13 distraction activities, prepared to be used in DL training processes. Furthermore, we propose a robust and real-time driver behaviour recognition system targeting a real-world application that can run on cost-efficient CPU-only platforms, based on the dBehaviourMD. Its performance is evaluated with different types of fusion strategies, which all reach enhanced accuracy still providing real-time response.
Real-Time Driver State Monitoring Using a CNN Based Spatio-Temporal Approach
Jul 18, 2019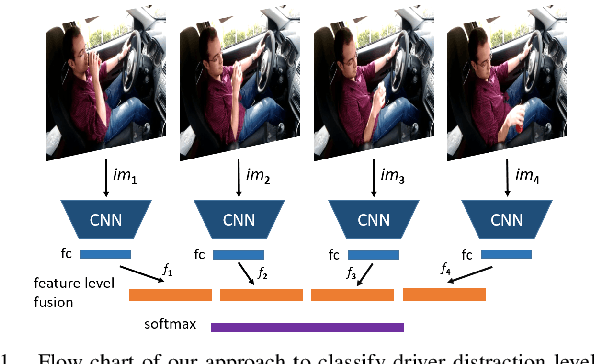


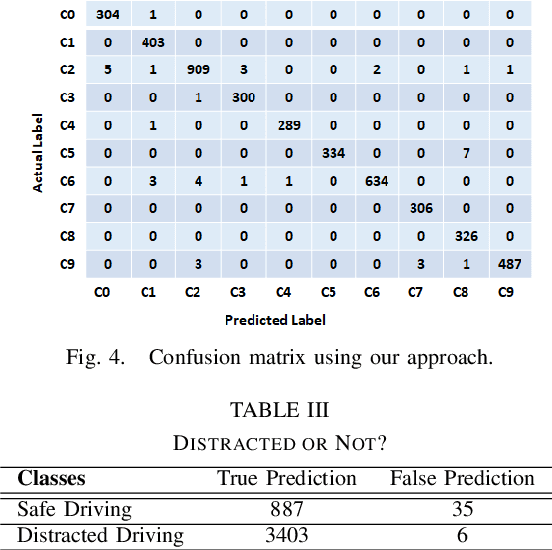
Many road accidents occur due to distracted drivers. Today, driver monitoring is essential even for the latest autonomous vehicles to alert distracted drivers in order to take over control of the vehicle in case of emergency. In this paper, a spatio-temporal approach is applied to classify drivers' distraction level and movement decisions using convolutional neural networks (CNNs). We approach this problem as action recognition to benefit from temporal information in addition to spatial information. Our approach relies on features extracted from sparsely selected frames of an action using a pre-trained BN-Inception network. Experiments show that our approach outperforms the state-of-the art results on the Distracted Driver Dataset (96.31%), with an accuracy of 99.10% for 10-class classification while providing real-time performance. We also analyzed the impact of fusion using RGB and optical flow modalities with a very recent data level fusion strategy. The results on the Distracted Driver and Brain4Cars datasets show that fusion of these modalities further increases the accuracy.