 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic UAV-based Airport Pavement Inspection Using Mixed Real and Virtual Scenarios
Jan 11, 2024Runway and taxiway pavements are exposed to high stress during their projected lifetime, which inevitably leads to a decrease in their condition over time. To make sure airport pavement condition ensure uninterrupted and resilient operations, it is of utmost importance to monitor their condition and conduct regular inspections. UAV-based inspection is recently gaining importance due to its wide range monitoring capabilities and reduced cost. In this work, we propose a vision-based approach to automatically identify pavement distress using images captured by UAVs. The proposed method is based on Deep Learning (DL) to segment defects in the image. The DL architecture leverages the low computational capacities of embedded systems in UAVs by using an optimised implementation of EfficientNet feature extraction and Feature Pyramid Network segmentation. To deal with the lack of annotated data for training we have developed a synthetic dataset generation methodology to extend available distress datasets. We demonstrate that the use of a mixed dataset composed of synthetic and real training images yields better results when testing the training models in real application scenarios.
* 12 pages, 6 figures, published in proceedings of 15th International Conference on Machine Vision (ICMV)
Virtual passengers for real car solutions: synthetic datasets
May 13, 2022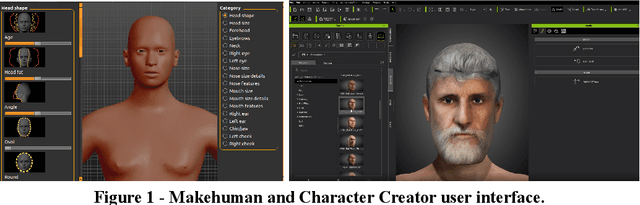


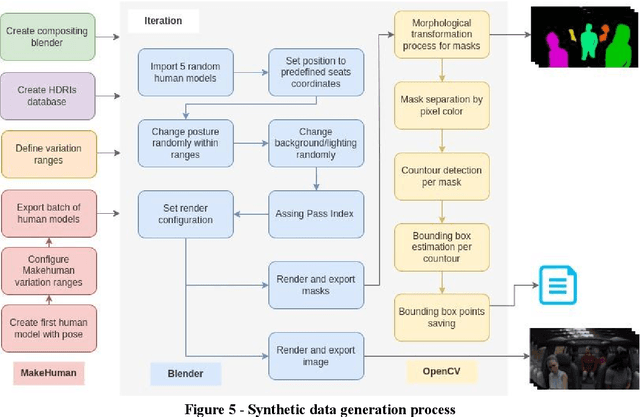
Strategies that include the generation of synthetic data are beginning to be viable as obtaining real data can be logistically complicated, very expensive or slow. Not only the capture of the data can lead to complications, but also its annotation. To achieve high-fidelity data for training intelligent systems, we have built a 3D scenario and set-up to resemble reality as closely as possible. With our approach, it is possible to configure and vary parameters to add randomness to the scene and, in this way, allow variation in data, which is so important in the construction of a dataset. Besides, the annotation task is already included in the data generation exercise, rather than being a post-capture task, which can save a lot of resources. We present the process and concept of synthetic data generation in an automotive context, specifically for driver and passenger monitoring purposes, as an alternative to real data capturing.
DMD: A Large-Scale Multi-Modal Driver Monitoring Dataset for Attention and Alertness Analysis
Aug 27, 2020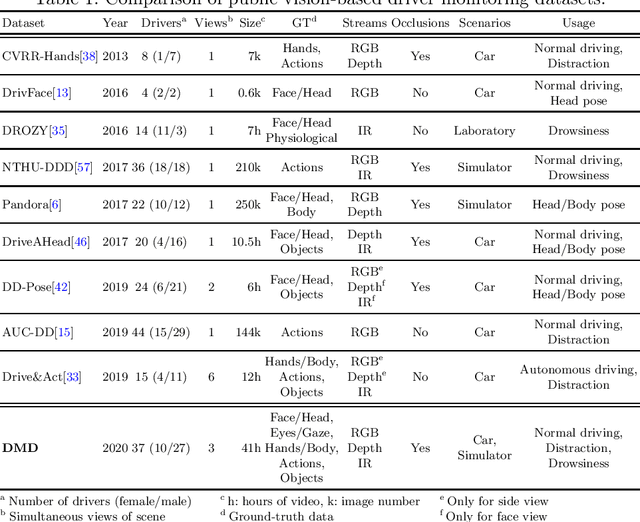
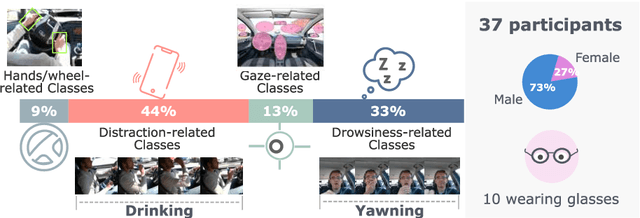
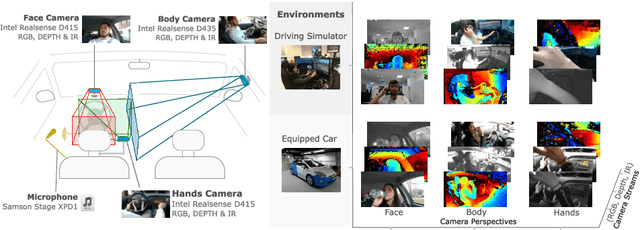

Vision is the richest and most cost-effective technology for Driver Monitoring Systems (DMS), especially after the recent success of Deep Learning (DL) methods. The lack of sufficiently large and comprehensive datasets is currently a bottleneck for the progress of DMS development, crucial for the transition of automated driving from SAE Level-2 to SAE Level-3. In this paper, we introduce the Driver Monitoring Dataset (DMD), an extensive dataset which includes real and simulated driving scenarios: distraction, gaze allocation, drowsiness, hands-wheel interaction and context data, in 41 hours of RGB, depth and IR videos from 3 cameras capturing face, body and hands of 37 drivers. A comparison with existing similar datasets is included, which shows the DMD is more extensive, diverse, and multi-purpose. The usage of the DMD is illustrated by extracting a subset of it, the dBehaviourMD dataset, containing 13 distraction activities, prepared to be used in DL training processes. Furthermore, we propose a robust and real-time driver behaviour recognition system targeting a real-world application that can run on cost-efficient CPU-only platforms, based on the dBehaviourMD. Its performance is evaluated with different types of fusion strategies, which all reach enhanced accuracy still providing real-time response.