 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration of VLMs for Driver Monitoring Systems Applications
Mar 15, 2025



In recent years, we have witnessed significant progress in emerging deep learning models, particularly Large Language Models (LLMs) and Vision-Language Models (VLMs). These models have demonstrated promising results, indicating a new era of Artificial Intelligence (AI) that surpasses previous methodologies. Their extensive knowledge and zero-shot capabilities suggest a paradigm shift in developing deep learning solutions, moving from data capturing and algorithm training to just writing appropriate prompts. While the application of these technologies has been explored across various industries, including automotive, there is a notable gap in the scientific literature regarding their use in Driver Monitoring Systems (DMS). This paper presents our initial approach to implementing VLMs in this domain, utilising the Driver Monitoring Dataset to evaluate their performance and discussing their advantages and challenges when implemented in real-world scenarios.
Learning Gaze-aware Compositional GAN
May 31, 2024



Gaze-annotated facial data is crucial for training deep neural networks (DNNs) for gaze estimation. However, obtaining these data is labor-intensive and requires specialized equipment due to the challenge of accurately annotating the gaze direction of a subject. In this work, we present a generative framework to create annotated gaze data by leveraging the benefits of labeled and unlabeled data sources. We propose a Gaze-aware Compositional GAN that learns to generate annotated facial images from a limited labeled dataset. Then we transfer this model to an unlabeled data domain to take advantage of the diversity it provides. Experiments demonstrate our approach's effectiveness in generating within-domain image augmentations in the ETH-XGaze dataset and cross-domain augmentations in the CelebAMask-HQ dataset domain for gaze estimation DNN training. We also show additional applications of our work, which include facial image editing and gaze redirection.
* Accepted by ETRA 2024 as Full paper, and as journal paper in Proceedings of the ACM on Computer Graphics and Interactive Techniques
Monetisation of and Access to in-Vehicle data and resources: the 5GMETA approach
Aug 24, 2022
Today's vehicles are increasingly embedded with computers and sensors which produce huge amount of data. The data are exploited for internal purposes and with the development of connected infrastructures and smart cities, the vehicles interact with each other as well as with road users generating other types of data. The access to these data and in-vehicle resources and their monetisation faces many challenges which are presented in this paper. Furthermore, the most important commercial solution compared to the open and novel approach faced in the H2020 5GMETA project.
Virtual passengers for real car solutions: synthetic datasets
May 13, 2022


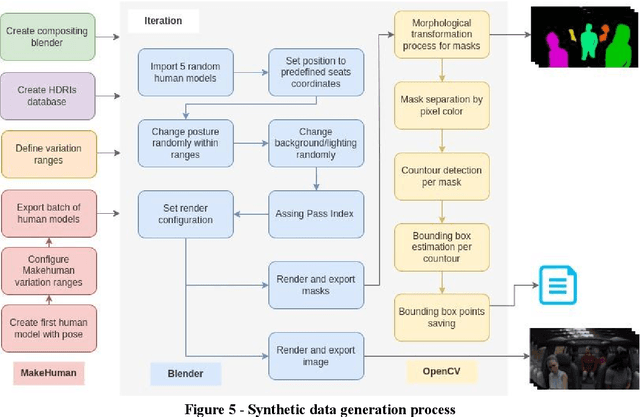
Strategies that include the generation of synthetic data are beginning to be viable as obtaining real data can be logistically complicated, very expensive or slow. Not only the capture of the data can lead to complications, but also its annotation. To achieve high-fidelity data for training intelligent systems, we have built a 3D scenario and set-up to resemble reality as closely as possible. With our approach, it is possible to configure and vary parameters to add randomness to the scene and, in this way, allow variation in data, which is so important in the construction of a dataset. Besides, the annotation task is already included in the data generation exercise, rather than being a post-capture task, which can save a lot of resources. We present the process and concept of synthetic data generation in an automotive context, specifically for driver and passenger monitoring purposes, as an alternative to real data capturing.
RTMaps-based Local Dynamic Map for multi-ADAS data fusion
May 13, 2022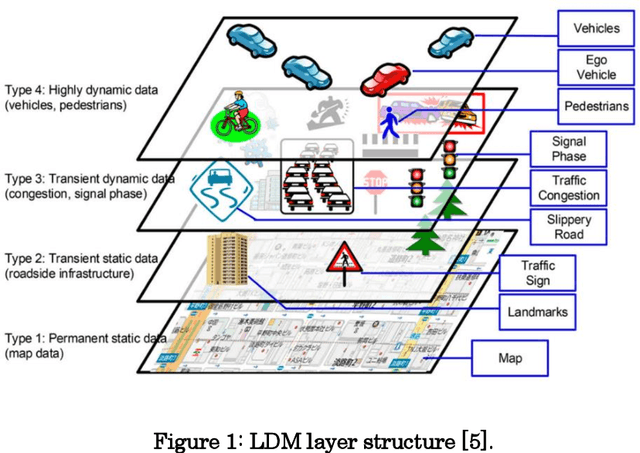
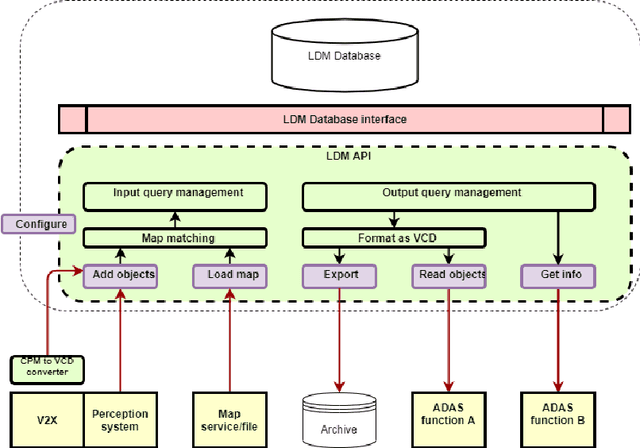
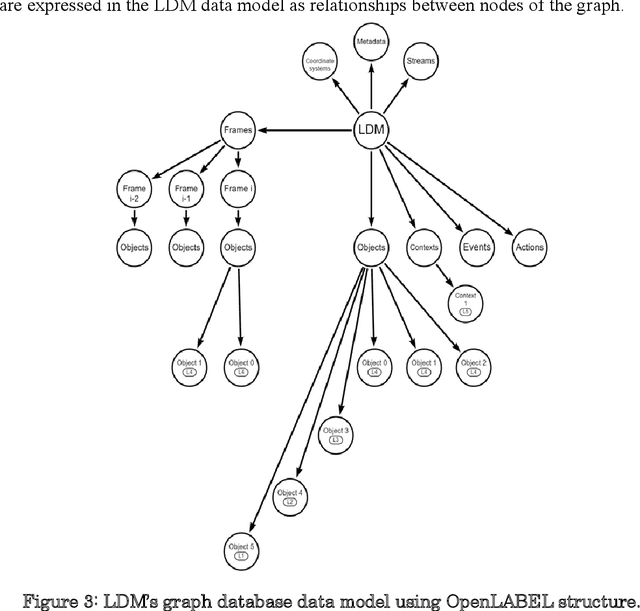
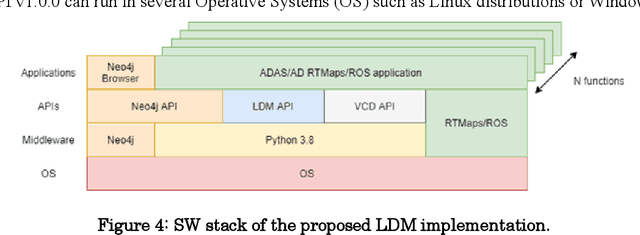
Work on Local Dynamic Maps (LDM) implementation is still in its early stages, as the LDM standards only define how information shall be structured in databases, while the mechanism to fuse or link information across different layers is left undefined. A working LDM component, as a real-time database inside the vehicle is an attractive solution to multi-ADAS systems, which may feed a real-time LDM database that serves as a central point of information inside the vehicle, exposing fused and structured information to other components (e.g., decision-making systems). In this paper we describe our approach implementing a real-time LDM component using the RTMaps middleware, as a database deployed in a vehicle, but also at road-side units (RSU), making use of the three pillars that guide a successful fusion strategy: utilisation of standards (with conversions between domains), middlewares to unify multiple ADAS sources, and linkage of data via semantic concepts.
5G Features and Standards for Vehicle Data Exploitation
Apr 13, 2022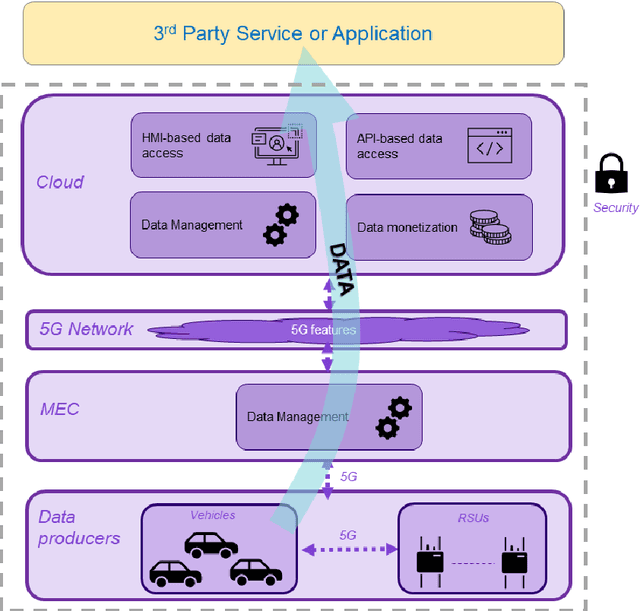



Cars capture and generate huge volumes of data in real-time about the driving dynamics, the environment, and the driver and passengers' activities. Due to the proliferation of cooperative, connected and automated mobility (CCAM), the value of data from vehicles is getting strategic, not just for the automotive industry, but also for many diverse stakeholders including small and medium-sized enterprises (SMEs) and start-ups. 5G can enable car-captured data to feed innovative applications and services deployed in the cloud ensuring lower latency and higher throughput than previous cellular technologies. This paper identifies and discusses the relevance of the main 5G features that can contribute to a scalable, flexible, reliable and secure data pipeline, pointing to the standards and technical reports that specify their implementation.
DMD: A Large-Scale Multi-Modal Driver Monitoring Dataset for Attention and Alertness Analysis
Aug 27, 2020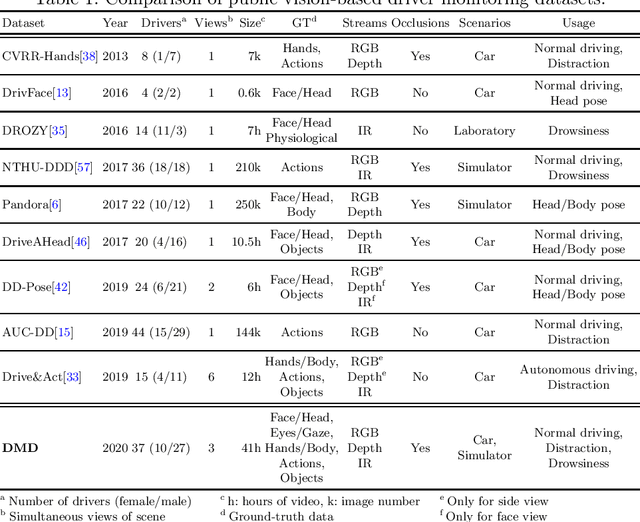
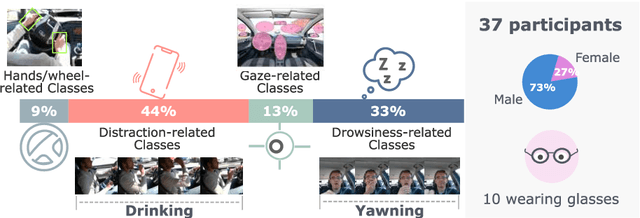
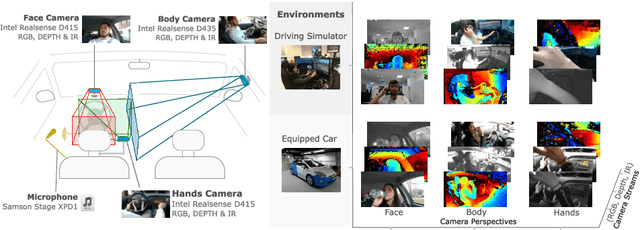

Vision is the richest and most cost-effective technology for Driver Monitoring Systems (DMS), especially after the recent success of Deep Learning (DL) methods. The lack of sufficiently large and comprehensive datasets is currently a bottleneck for the progress of DMS development, crucial for the transition of automated driving from SAE Level-2 to SAE Level-3. In this paper, we introduce the Driver Monitoring Dataset (DMD), an extensive dataset which includes real and simulated driving scenarios: distraction, gaze allocation, drowsiness, hands-wheel interaction and context data, in 41 hours of RGB, depth and IR videos from 3 cameras capturing face, body and hands of 37 drivers. A comparison with existing similar datasets is included, which shows the DMD is more extensive, diverse, and multi-purpose. The usage of the DMD is illustrated by extracting a subset of it, the dBehaviourMD dataset, containing 13 distraction activities, prepared to be used in DL training processes. Furthermore, we propose a robust and real-time driver behaviour recognition system targeting a real-world application that can run on cost-efficient CPU-only platforms, based on the dBehaviourMD. Its performance is evaluated with different types of fusion strategies, which all reach enhanced accuracy still providing real-time response.
3D Object Detection From LiDAR Data Using Distance Dependent Feature Extraction
Mar 03, 2020
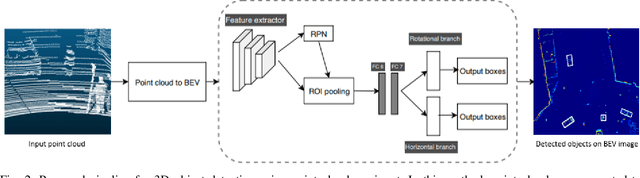
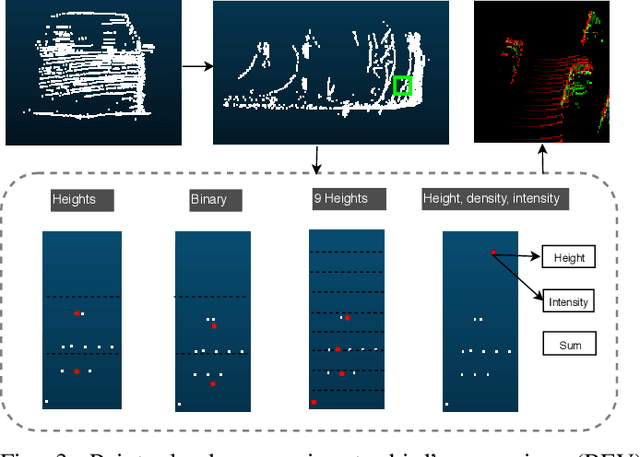

This paper presents a new approach to 3D object detection that leverages the properties of the data obtained by a LiDAR sensor. State-of-the-art detectors use neural network architectures based on assumptions valid for camera images. However, point clouds obtained from LiDAR are fundamentally different. Most detectors use shared filter kernels to extract features which do not take into account the range dependent nature of the point cloud features. To show this, different detectors are trained on two splits of the KITTI dataset: close range (objects up to 25 meters from LiDAR) and long-range. Top view images are generated from point clouds as input for the networks. Combined results outperform the baseline network trained on the full dataset with a single backbone. Additional research compares the effect of using different input features when converting the point cloud to image. The results indicate that the network focuses on the shape and structure of the objects, rather than exact values of the input. This work proposes an improvement for 3D object detectors by taking into account the properties of LiDAR point clouds over distance. Results show that training separate networks for close-range and long-range objects boosts performance for all KITTI benchmark difficulties.
Embedded Platforms for Computer Vision-based Advanced Driver Assistance Systems: a Survey
Apr 28, 2015Computer Vision, either alone or combined with other technologies such as radar or Lidar, is one of the key technologies used in Advanced Driver Assistance Systems (ADAS). Its role understanding and analysing the driving scene is of great importance as it can be noted by the number of ADAS applications that use this technology. However, porting a vision algorithm to an embedded automotive system is still very challenging, as there must be a trade-off between several design requisites. Furthermore, there is not a standard implementation platform, so different alternatives have been proposed by both the scientific community and the industry. This paper aims to review the requisites and the different embedded implementation platforms that can be used for Computer Vision-based ADAS, with a critical analysis and an outlook to future trends.