 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fully Interpretable Statistical Approach for Roadside LiDAR Background Subtraction
Oct 25, 2025



We present a fully interpretable and flexible statistical method for background subtraction in roadside LiDAR data, aimed at enhancing infrastructure-based perception in automated driving. Our approach introduces both a Gaussian distribution grid (GDG), which models the spatial statistics of the background using background-only scans, and a filtering algorithm that uses this representation to classify LiDAR points as foreground or background. The method supports diverse LiDAR types, including multiline 360 degree and micro-electro-mechanical systems (MEMS) sensors, and adapts to various configurations. Evaluated on the publicly available RCooper dataset, it outperforms state-of-the-art techniques in accuracy and flexibility, even with minimal background data. Its efficient implementation ensures reliable performance on low-resource hardware, enabling scalable real-world deployment.
Learning Gaze-aware Compositional GAN
May 31, 2024



Gaze-annotated facial data is crucial for training deep neural networks (DNNs) for gaze estimation. However, obtaining these data is labor-intensive and requires specialized equipment due to the challenge of accurately annotating the gaze direction of a subject. In this work, we present a generative framework to create annotated gaze data by leveraging the benefits of labeled and unlabeled data sources. We propose a Gaze-aware Compositional GAN that learns to generate annotated facial images from a limited labeled dataset. Then we transfer this model to an unlabeled data domain to take advantage of the diversity it provides. Experiments demonstrate our approach's effectiveness in generating within-domain image augmentations in the ETH-XGaze dataset and cross-domain augmentations in the CelebAMask-HQ dataset domain for gaze estimation DNN training. We also show additional applications of our work, which include facial image editing and gaze redirection.
* Accepted by ETRA 2024 as Full paper, and as journal paper in Proceedings of the ACM on Computer Graphics and Interactive Techniques
Dynamic Risk Assessment Methodology with an LDM-based System for Parking Scenarios
Apr 05, 2024This paper describes the methodology for building a dynamic risk assessment for ADAS (Advanced Driving Assistance Systems) algorithms in parking scenarios, fusing exterior and interior perception for a better understanding of the scene and a more comprehensive risk estimation. This includes the definition of a dynamic risk methodology that depends on the situation from inside and outside the vehicle, the creation of a multi-sensor dataset of risk assessment for ADAS benchmarking purposes, and a Local Dynamic Map (LDM) that fuses data from the exterior and interior of the car to build an LDM-based Dynamic Risk Assessment System (DRAS).
LiDAR-based curb detection for ground truth annotation in automated driving validation
Dec 01, 2023



Curb detection is essential for environmental awareness in Automated Driving (AD), as it typically limits drivable and non-drivable areas. Annotated data are necessary for developing and validating an AD function. However, the number of public datasets with annotated point cloud curbs is scarce. This paper presents a method for detecting 3D curbs in a sequence of point clouds captured from a LiDAR sensor, which consists of two main steps. First, our approach detects the curbs at each scan using a segmentation deep neural network. Then, a sequence-level processing step estimates the 3D curbs in the reconstructed point cloud using the odometry of the vehicle. From these 3D points of the curb, we obtain polylines structured following ASAM OpenLABEL standard. These detections can be used as pre-annotations in labelling pipelines to efficiently generate curb-related ground truth data. We validate our approach through an experiment in which different human annotators were required to annotate curbs in a group of LiDAR-based sequences with and without our automatically generated pre-annotations. The results show that the manual annotation time is reduced by 50.99% thanks to our detections, keeping the data quality level.
Methodology for generating synthetic labeled datasets for visual container inspection
Jun 26, 2023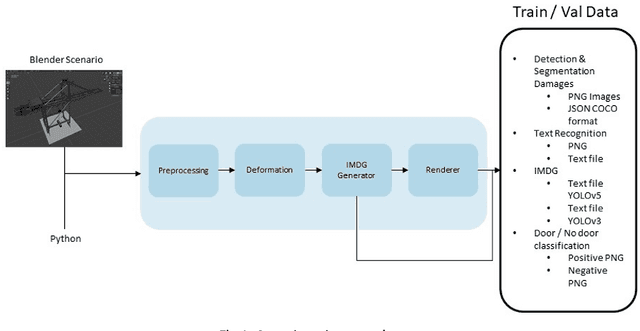



Nowadays, containerized freight transport is one of the most important transportation systems that is undergoing an automation process due to the Deep Learning success. However, it suffers from a lack of annotated data in order to incorporate state-of-the-art neural network models to its systems. In this paper we present an innovative methodology to generate a realistic, varied, balanced, and labelled dataset for visual inspection task of containers in a dock environment. In addition, we validate this methodology with multiple visual tasks recurrently found in the state of the art. We prove that the generated synthetic labelled dataset allows to train a deep neural network that can be used in a real world scenario. On the other side, using this methodology we provide the first open synthetic labelled dataset called SeaFront available in: https://datasets.vicomtech.org/di21-seafront/readme.txt.
3D Object Detection From LiDAR Data Using Distance Dependent Feature Extraction
Mar 03, 2020
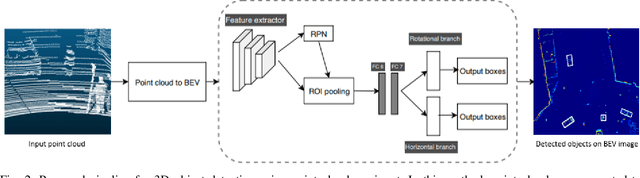
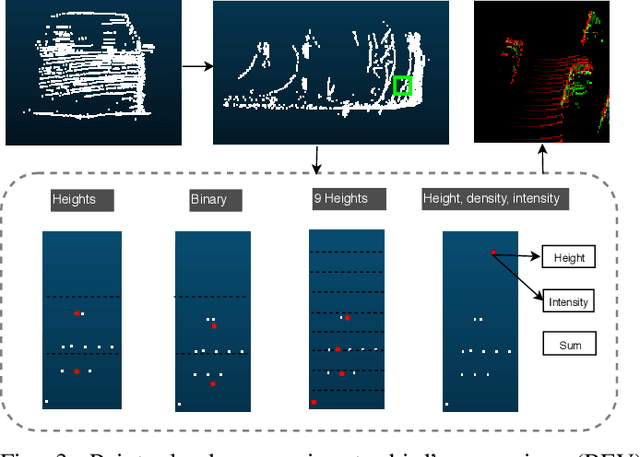

This paper presents a new approach to 3D object detection that leverages the properties of the data obtained by a LiDAR sensor. State-of-the-art detectors use neural network architectures based on assumptions valid for camera images. However, point clouds obtained from LiDAR are fundamentally different. Most detectors use shared filter kernels to extract features which do not take into account the range dependent nature of the point cloud features. To show this, different detectors are trained on two splits of the KITTI dataset: close range (objects up to 25 meters from LiDAR) and long-range. Top view images are generated from point clouds as input for the networks. Combined results outperform the baseline network trained on the full dataset with a single backbone. Additional research compares the effect of using different input features when converting the point cloud to image. The results indicate that the network focuses on the shape and structure of the objects, rather than exact values of the input. This work proposes an improvement for 3D object detectors by taking into account the properties of LiDAR point clouds over distance. Results show that training separate networks for close-range and long-range objects boosts performance for all KITTI benchmark difficulties.
Fully automatic detection and segmentation of abdominal aortic thrombus in post-operative CTA images using deep convolutional neural networks
Apr 01, 2018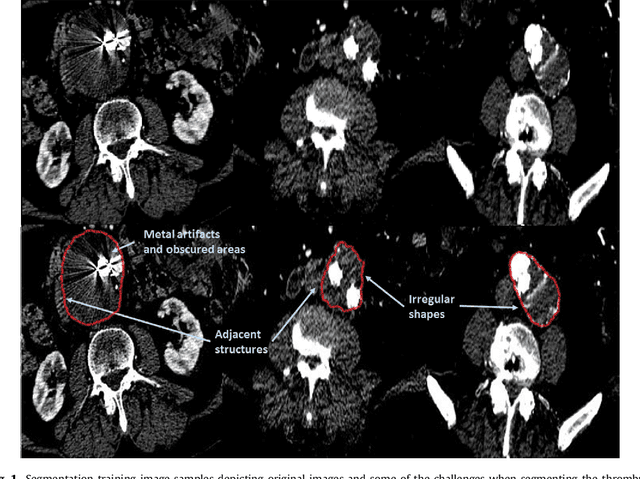
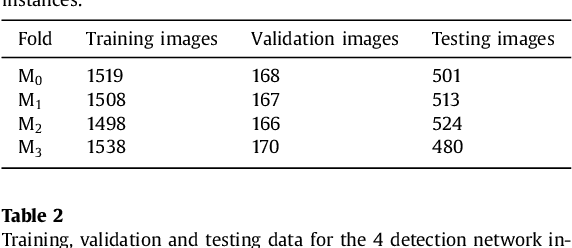
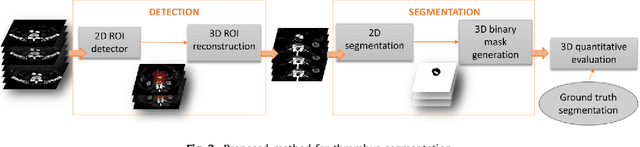

Computerized Tomography Angiography (CTA) based follow-up of Abdominal Aortic Aneurysms (AAA) treated with Endovascular Aneurysm Repair (EVAR) is essential to evaluate the progress of the patient and detect complications. In this context, accurate quantification of post-operative thrombus volume is required. However, a proper evaluation is hindered by the lack of automatic, robust and reproducible thrombus segmentation algorithms. We propose a new fully automatic approach based on Deep Convolutional Neural Networks (DCNN) for robust and reproducible thrombus region of interest detection and subsequent fine thrombus segmentation. The DetecNet detection network is adapted to perform region of interest extraction from a complete CTA and a new segmentation network architecture, based on Fully Convolutional Networks and a Holistically-Nested Edge Detection Network, is presented. These networks are trained, validated and tested in 13 post-operative CTA volumes of different patients using a 4-fold cross-validation approach to provide more robustness to the results. Our pipeline achieves a Dice score of more than 82% for post-operative thrombus segmentation and provides a mean relative volume difference between ground truth and automatic segmentation that lays within the experienced human observer variance without the need of human intervention in most common cases.