 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Rater Calibrated Segmentation Models
May 04, 2026Objective: Accurate probability estimates are essential for the safe deployment of medical image segmentation models in clinical decision-making. However, modern deep segmentation networks are often poorly calibrated, a problem exacerbated when multiple expert annotations exhibit substantial disagreement. While inter-rater variability is typically treated as noise, it provides valuable information about intrinsic annotation ambiguity that must be reflected in model confidence. Methods: We improve the probabilistic calibration of medical image segmentation models by reformulating multi-rater supervision as an ordinal learning problem. Voxel-wise annotator agreement is treated as an ordered target, linking predictive confidence to the empirical variability in training data. This formulation allows the use of ordinal-aware scoring rules, such as the Ranked Probability Score ordinal loss, combined with a standard binary objective to preserve discriminative performance. Results: We evaluated the proposed approach across four public segmentation benchmarks spanning ophthalmology, histopathology, and thoracic imaging. Calibration was assessed using a multi-rater extension of expected calibration error. Results consistently show that ordinal-aware training yields substantially improved calibration with respect to inter-rater agreement without degrading segmentation accuracy. Conclusions: Treating multi-rater annotations as ordered information provides a principled and architecture-agnostic route to more reliable probabilistic segmentation models.
Towards interpretable AI with quantum annealing feature selection
Apr 28, 2026Deep learning models are used in critical applications, in which mistakes can have serious consequences. Therefore, it is crucial to understand how and why models generate predictions. This understanding provides useful information to check whether the model is learning the right patterns, detect biases in the data, improve model design, and build systems that can be trusted. This work proposes a new method for interpreting Convolutional Neural Networks in image classification tasks. The approach works by selecting the most important feature maps that contribute to each prediction. To solve this combinatorial problem, we encode it into a quantum constrained optimization problem and propose to solve it using quantum annealing. We evaluate our method against the state-of-the-art explainable AI techniques, specifically GradCAM and GradCAM++, and observe an improved class disentanglement, i.e. the model's decision boundaries become more distinct and its reasoning more transparent. This demonstrates that our approach enhances the quality of explanations, making it easier to understand which features the model relies on for specific predictions. In addition, we study the computational behavior of the quantum annealing algorithm. Specifically, we analyze the minimum energy gap of the system during computation and the probability that the algorithm finds the correct solution. These analyses provide theoretical insight into why the method works effectively in practice.
Data-Centric Label Smoothing for Explainable Glaucoma Screening from Eye Fundus Images
Jun 06, 2024As current computing capabilities increase, modern machine learning and computer vision system tend to increase in complexity, mostly by means of larger models and advanced optimization strategies. Although often neglected, in many problems there is also much to be gained by considering potential improvements in understanding and better leveraging already-available training data, including annotations. This so-called data-centric approach can lead to substantial performance increases, sometimes beyond what can be achieved by larger models. In this paper we adopt such an approach for the task of justifiable glaucoma screening from retinal images. In particular, we focus on how to combine information from multiple annotators of different skills into a tailored label smoothing scheme that allows us to better employ a large collection of fundus images, instead of discarding samples suffering from inter-rater variability. Internal validation results indicate that our bespoke label smoothing approach surpasses the performance of a standard resnet50 model and also the same model trained with conventional label smoothing techniques, in particular for the multi-label scenario of predicting clinical reasons of glaucoma likelihood in a highly imbalanced screening context. Our code is made available at github.com/agaldran/justraigs .
Unsupervised Segmentation of Fetal Brain MRI using Deep Learning Cascaded Registration
Jul 07, 2023



Accurate segmentation of fetal brain magnetic resonance images is crucial for analyzing fetal brain development and detecting potential neurodevelopmental abnormalities. Traditional deep learning-based automatic segmentation, although effective, requires extensive training data with ground-truth labels, typically produced by clinicians through a time-consuming annotation process. To overcome this challenge, we propose a novel unsupervised segmentation method based on multi-atlas segmentation, that accurately segments multiple tissues without relying on labeled data for training. Our method employs a cascaded deep learning network for 3D image registration, which computes small, incremental deformations to the moving image to align it precisely with the fixed image. This cascaded network can then be used to register multiple annotated images with the image to be segmented, and combine the propagated labels to form a refined segmentation. Our experiments demonstrate that the proposed cascaded architecture outperforms the state-of-the-art registration methods that were tested. Furthermore, the derived segmentation method achieves similar performance and inference time to nnU-Net while only using a small subset of annotated data for the multi-atlas segmentation task and none for training the network. Our pipeline for registration and multi-atlas segmentation is publicly available at https://github.com/ValBcn/CasReg.
Multi-Head Multi-Loss Model Calibration
Mar 02, 2023Delivering meaningful uncertainty estimates is essential for a successful deployment of machine learning models in the clinical practice. A central aspect of uncertainty quantification is the ability of a model to return predictions that are well-aligned with the actual probability of the model being correct, also known as model calibration. Although many methods have been proposed to improve calibration, no technique can match the simple, but expensive approach of training an ensemble of deep neural networks. In this paper we introduce a form of simplified ensembling that bypasses the costly training and inference of deep ensembles, yet it keeps its calibration capabilities. The idea is to replace the common linear classifier at the end of a network by a set of heads that are supervised with different loss functions to enforce diversity on their predictions. Specifically, each head is trained to minimize a weighted Cross-Entropy loss, but the weights are different among the different branches. We show that the resulting averaged predictions can achieve excellent calibration without sacrificing accuracy in two challenging datasets for histopathological and endoscopic image classification. Our experiments indicate that Multi-Head Multi-Loss classifiers are inherently well-calibrated, outperforming other recent calibration techniques and even challenging Deep Ensembles' performance. Code to reproduce our experiments can be found at \url{https://github.com/agaldran/mhml_calibration} .
Test Time Transform Prediction for Open Set Histopathological Image Recognition
Jun 27, 2022
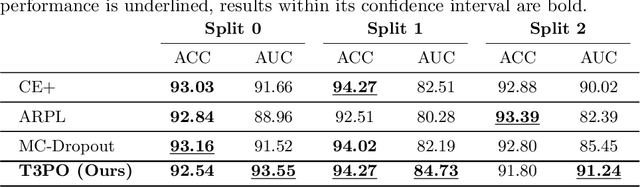
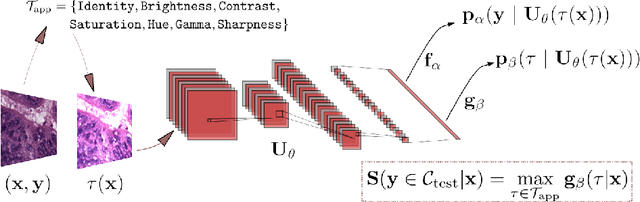
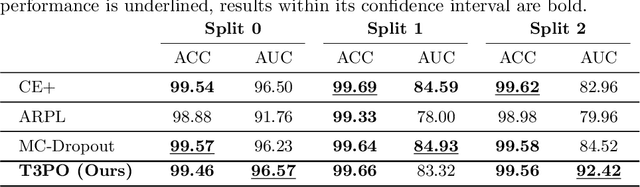
Tissue typology annotation in Whole Slide histological images is a complex and tedious, yet necessary task for the development of computational pathology models. We propose to address this problem by applying Open Set Recognition techniques to the task of jointly classifying tissue that belongs to a set of annotated classes, e.g. clinically relevant tissue categories, while rejecting in test time Open Set samples, i.e. images that belong to categories not present in the training set. To this end, we introduce a new approach for Open Set histopathological image recognition based on training a model to accurately identify image categories and simultaneously predict which data augmentation transform has been applied. In test time, we measure model confidence in predicting this transform, which we expect to be lower for images in the Open Set. We carry out comprehensive experiments in the context of colorectal cancer assessment from histological images, which provide evidence on the strengths of our approach to automatically identify samples from unknown categories. Code is released at https://github.com/agaldran/t3po .
A Hierarchical Multi-Task Approach to Gastrointestinal Image Analysis
Nov 16, 2021
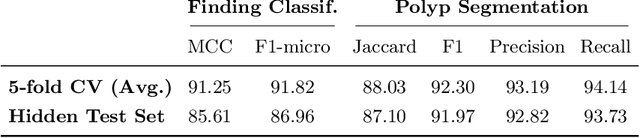
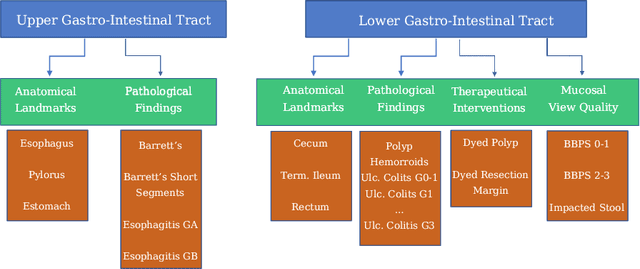
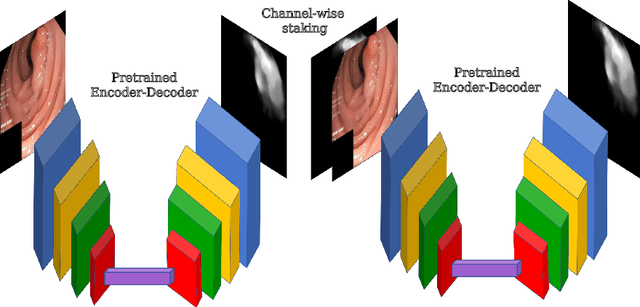
A large number of different lesions and pathologies can affect the human digestive system, resulting in life-threatening situations. Early detection plays a relevant role in the successful treatment and the increase of current survival rates to, e.g., colorectal cancer. The standard procedure enabling detection, endoscopic video analysis, generates large quantities of visual data that need to be carefully analyzed by an specialist. Due to the wide range of color, shape, and general visual appearance of pathologies, as well as highly varying image quality, such process is greatly dependent on the human operator experience and skill. In this work, we detail our solution to the task of multi-category classification of images from the gastrointestinal (GI) human tract within the 2020 Endotect Challenge. Our approach is based on a Convolutional Neural Network minimizing a hierarchical error function that takes into account not only the finding category, but also its location within the GI tract (lower/upper tract), and the type of finding (pathological finding/therapeutic intervention/anatomical landmark/mucosal views' quality). We also describe in this paper our solution for the challenge task of polyp segmentation in colonoscopies, which was addressed with a pretrained double encoder-decoder network. Our internal cross-validation results show an average performance of 91.25 Mathews Correlation Coefficient (MCC) and 91.82 Micro-F1 score for the classification task, and a 92.30 F1 score for the polyp segmentation task. The organization provided feedback on the performance in a hidden test set for both tasks, which resulted in 85.61 MCC and 86.96 F1 score for classification, and 91.97 F1 score for polyp segmentation. At the time of writing no public ranking for this challenge had been released.
Convolutional Nets Versus Vision Transformers for Diabetic Foot Ulcer Classification
Nov 12, 2021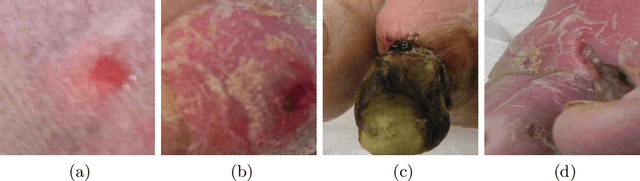
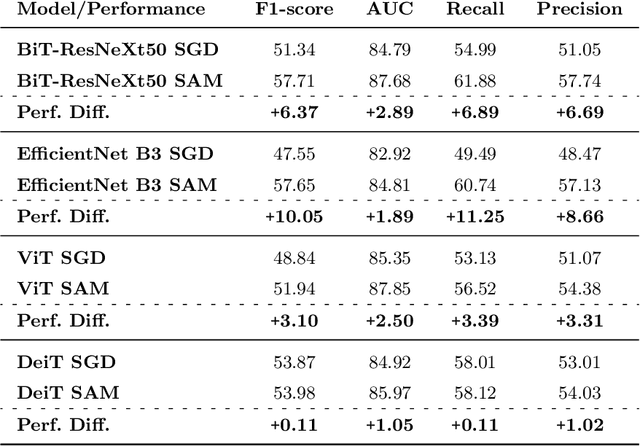
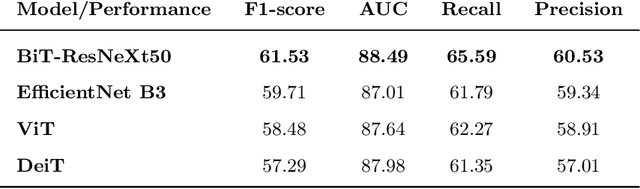
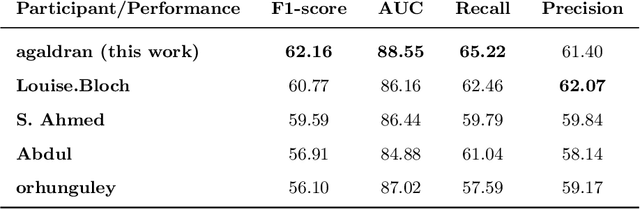
This paper compares well-established Convolutional Neural Networks (CNNs) to recently introduced Vision Transformers for the task of Diabetic Foot Ulcer Classification, in the context of the DFUC 2021 Grand-Challenge, in which this work attained the first position. Comprehensive experiments demonstrate that modern CNNs are still capable of outperforming Transformers in a low-data regime, likely owing to their ability for better exploiting spatial correlations. In addition, we empirically demonstrate that the recent Sharpness-Aware Minimization (SAM) optimization algorithm considerably improves the generalization capability of both kinds of models. Our results demonstrate that for this task, the combination of CNNs and the SAM optimization process results in superior performance than any other of the considered approaches.
Double Encoder-Decoder Networks for Gastrointestinal Polyp Segmentation
Oct 05, 2021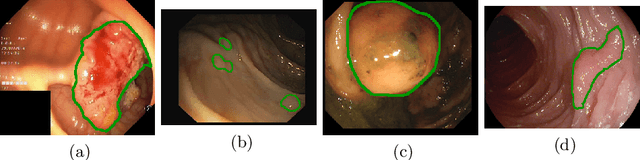

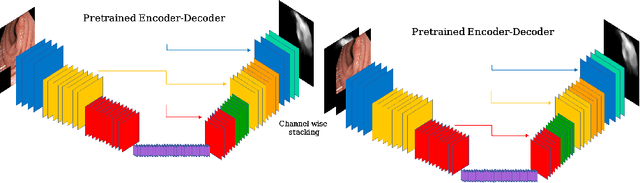
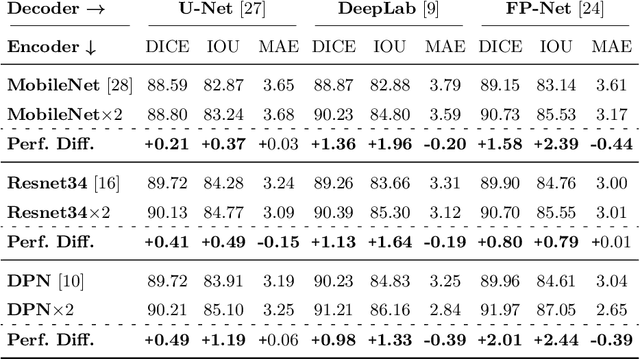
Polyps represent an early sign of the development of Colorectal Cancer. The standard procedure for their detection consists of colonoscopic examination of the gastrointestinal tract. However, the wide range of polyp shapes and visual appearances, as well as the reduced quality of this image modality, turn their automatic identification and segmentation with computational tools into a challenging computer vision task. In this work, we present a new strategy for the delineation of gastrointestinal polyps from endoscopic images based on a direct extension of common encoder-decoder networks for semantic segmentation. In our approach, two pretrained encoder-decoder networks are sequentially stacked: the second network takes as input the concatenation of the original frame and the initial prediction generated by the first network, which acts as an attention mechanism enabling the second network to focus on interesting areas within the image, thereby improving the quality of its predictions. Quantitative evaluation carried out on several polyp segmentation databases shows that double encoder-decoder networks clearly outperform their single encoder-decoder counterparts in all cases. In addition, our best double encoder-decoder combination attains excellent segmentation accuracy and reaches state-of-the-art performance results in all the considered datasets, with a remarkable boost of accuracy on images extracted from datasets not used for training.
Balanced-MixUp for Highly Imbalanced Medical Image Classification
Sep 20, 2021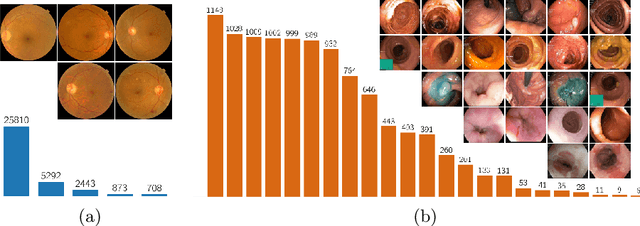
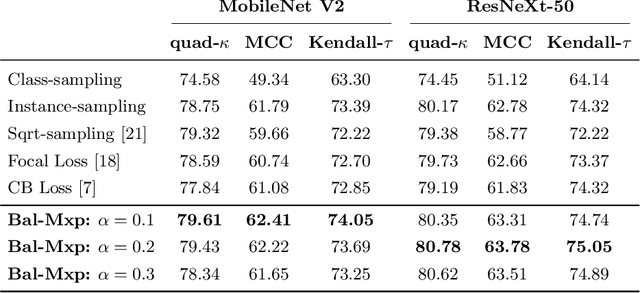

Highly imbalanced datasets are ubiquitous in medical image classification problems. In such problems, it is often the case that rare classes associated to less prevalent diseases are severely under-represented in labeled databases, typically resulting in poor performance of machine learning algorithms due to overfitting in the learning process. In this paper, we propose a novel mechanism for sampling training data based on the popular MixUp regularization technique, which we refer to as Balanced-MixUp. In short, Balanced-MixUp simultaneously performs regular (i.e., instance-based) and balanced (i.e., class-based) sampling of the training data. The resulting two sets of samples are then mixed-up to create a more balanced training distribution from which a neural network can effectively learn without incurring in heavily under-fitting the minority classes. We experiment with a highly imbalanced dataset of retinal images (55K samples, 5 classes) and a long-tail dataset of gastro-intestinal video frames (10K images, 23 classes), using two CNNs of varying representation capabilities. Experimental results demonstrate that applying Balanced-MixUp outperforms other conventional sampling schemes and loss functions specifically designed to deal with imbalanced data. Code is released at https://github.com/agaldran/balanced_mixup .