 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning for Surgical Vision in Appendicitis Classification: Results of the FedSurg EndoVis 2024 Challenge
Oct 06, 2025Purpose: The FedSurg challenge was designed to benchmark the state of the art in federated learning for surgical video classification. Its goal was to assess how well current methods generalize to unseen clinical centers and adapt through local fine-tuning while enabling collaborative model development without sharing patient data. Methods: Participants developed strategies to classify inflammation stages in appendicitis using a preliminary version of the multi-center Appendix300 video dataset. The challenge evaluated two tasks: generalization to an unseen center and center-specific adaptation after fine-tuning. Submitted approaches included foundation models with linear probing, metric learning with triplet loss, and various FL aggregation schemes (FedAvg, FedMedian, FedSAM). Performance was assessed using F1-score and Expected Cost, with ranking robustness evaluated via bootstrapping and statistical testing. Results: In the generalization task, performance across centers was limited. In the adaptation task, all teams improved after fine-tuning, though ranking stability was low. The ViViT-based submission achieved the strongest overall performance. The challenge highlighted limitations in generalization, sensitivity to class imbalance, and difficulties in hyperparameter tuning in decentralized training, while spatiotemporal modeling and context-aware preprocessing emerged as promising strategies. Conclusion: The FedSurg Challenge establishes the first benchmark for evaluating FL strategies in surgical video classification. Findings highlight the trade-off between local personalization and global robustness, and underscore the importance of architecture choice, preprocessing, and loss design. This benchmarking offers a reference point for future development of imbalance-aware, adaptive, and robust FL methods in clinical surgical AI.
Federated EndoViT: Pretraining Vision Transformers via Federated Learning on Endoscopic Image Collections
Apr 23, 2025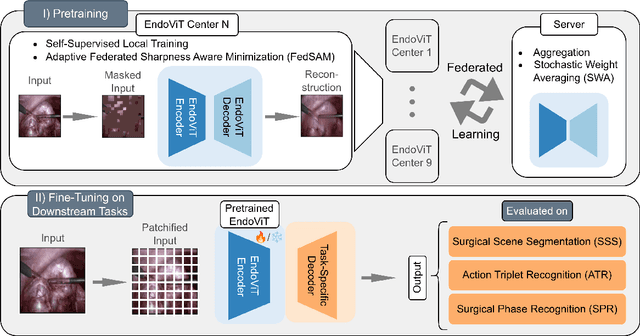
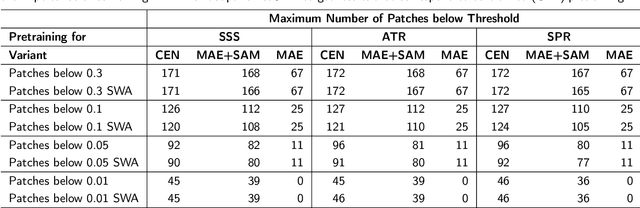
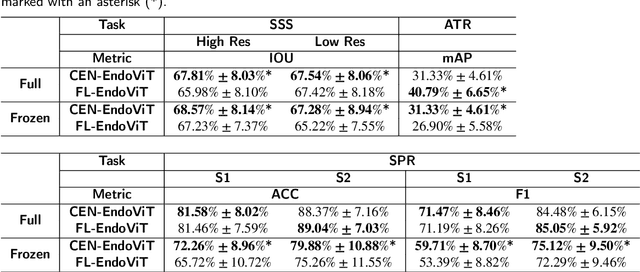
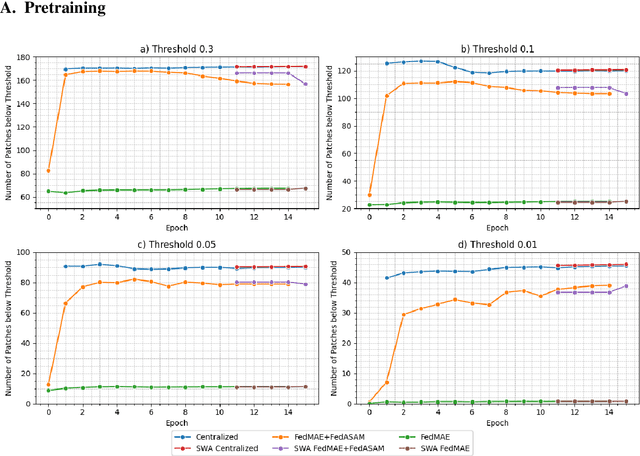
Purpose: In this study, we investigate the training of foundation models using federated learning to address data-sharing limitations and enable collaborative model training without data transfer for minimally invasive surgery. Methods: Inspired by the EndoViT study, we adapt the Masked Autoencoder for federated learning, enhancing it with adaptive Sharpness-Aware Minimization (FedSAM) and Stochastic Weight Averaging (SWA). Our model is pretrained on the Endo700k dataset collection and later fine-tuned and evaluated for tasks such as Semantic Segmentation, Action Triplet Recognition, and Surgical Phase Recognition. Results: Our findings demonstrate that integrating adaptive FedSAM into the federated MAE approach improves pretraining, leading to a reduction in reconstruction loss per patch. The application of FL-EndoViT in surgical downstream tasks results in performance comparable to CEN-EndoViT. Furthermore, FL-EndoViT exhibits advantages over CEN-EndoViT in surgical scene segmentation when data is limited and in action triplet recognition when large datasets are used. Conclusion: These findings highlight the potential of federated learning for privacy-preserving training of surgical foundation models, offering a robust and generalizable solution for surgical data science. Effective collaboration requires adapting federated learning methods, such as the integration of FedSAM, which can accommodate the inherent data heterogeneity across institutions. In future, exploring FL in video-based models may enhance these capabilities by incorporating spatiotemporal dynamics crucial for real-world surgical environments.
Prompt Injection Attacks on Large Language Models in Oncology
Jul 23, 2024



Vision-language artificial intelligence models (VLMs) possess medical knowledge and can be employed in healthcare in numerous ways, including as image interpreters, virtual scribes, and general decision support systems. However, here, we demonstrate that current VLMs applied to medical tasks exhibit a fundamental security flaw: they can be attacked by prompt injection attacks, which can be used to output harmful information just by interacting with the VLM, without any access to its parameters. We performed a quantitative study to evaluate the vulnerabilities to these attacks in four state of the art VLMs which have been proposed to be of utility in healthcare: Claude 3 Opus, Claude 3.5 Sonnet, Reka Core, and GPT-4o. Using a set of N=297 attacks, we show that all of these models are susceptible. Specifically, we show that embedding sub-visual prompts in medical imaging data can cause the model to provide harmful output, and that these prompts are non-obvious to human observers. Thus, our study demonstrates a key vulnerability in medical VLMs which should be mitigated before widespread clinical adoption.
A Good Feature Extractor Is All You Need for Weakly Supervised Learning in Histopathology
Nov 29, 2023Deep learning is revolutionising pathology, offering novel opportunities in disease prognosis and personalised treatment. Historically, stain normalisation has been a crucial preprocessing step in computational pathology pipelines, and persists into the deep learning era. Yet, with the emergence of feature extractors trained using self-supervised learning (SSL) on diverse pathology datasets, we call this practice into question. In an empirical evaluation of publicly available feature extractors, we find that omitting stain normalisation and image augmentations does not compromise downstream performance, while incurring substantial savings in memory and compute. Further, we show that the top-performing feature extractors are remarkably robust to variations in stain and augmentations like rotation in their latent space. Contrary to previous patch-level benchmarking studies, our approach emphasises clinical relevance by focusing on slide-level prediction tasks in a weakly supervised setting with external validation cohorts. This work represents the most comprehensive robustness evaluation of public pathology SSL feature extractors to date, involving more than 6,000 training runs across nine tasks, five datasets, three downstream architectures, and various preprocessing setups. Our findings stand to streamline digital pathology workflows by minimising preprocessing needs and informing the selection of feature extractors.
Using Multiple Dermoscopic Photographs of One Lesion Improves Melanoma Classification via Deep Learning: A Prognostic Diagnostic Accuracy Study
Jun 05, 2023
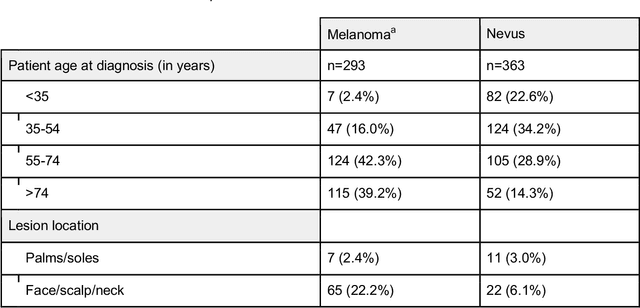
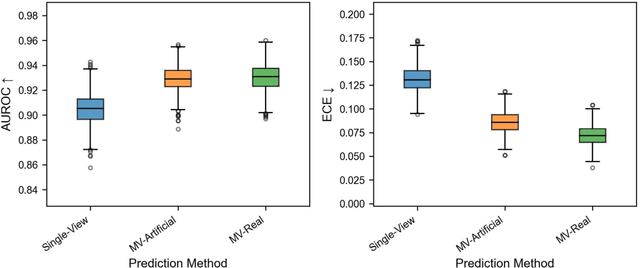
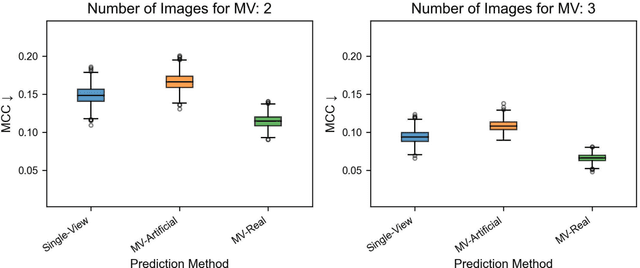
Background: Convolutional neural network (CNN)-based melanoma classifiers face several challenges that limit their usefulness in clinical practice. Objective: To investigate the impact of multiple real-world dermoscopic views of a single lesion of interest on a CNN-based melanoma classifier. Methods: This study evaluated 656 suspected melanoma lesions. Classifier performance was measured using area under the receiver operating characteristic curve (AUROC), expected calibration error (ECE) and maximum confidence change (MCC) for (I) a single-view scenario, (II) a multiview scenario using multiple artificially modified images per lesion and (III) a multiview scenario with multiple real-world images per lesion. Results: The multiview approach with real-world images significantly increased the AUROC from 0.905 (95% CI, 0.879-0.929) in the single-view approach to 0.930 (95% CI, 0.909-0.951). ECE and MCC also improved significantly from 0.131 (95% CI, 0.105-0.159) to 0.072 (95% CI: 0.052-0.093) and from 0.149 (95% CI, 0.125-0.171) to 0.115 (95% CI: 0.099-0.131), respectively. Comparing multiview real-world to artificially modified images showed comparable diagnostic accuracy and uncertainty estimation, but significantly worse robustness for the latter. Conclusion: Using multiple real-world images is an inexpensive method to positively impact the performance of a CNN-based melanoma classifier.
Test Time Transform Prediction for Open Set Histopathological Image Recognition
Jun 27, 2022
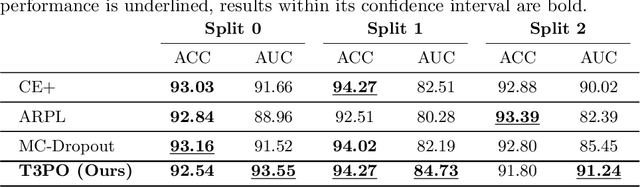
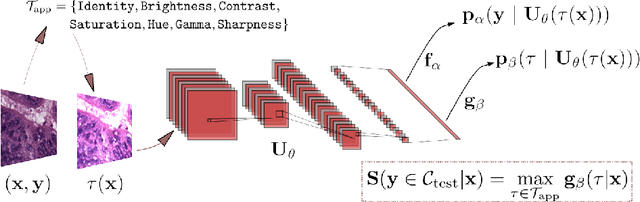
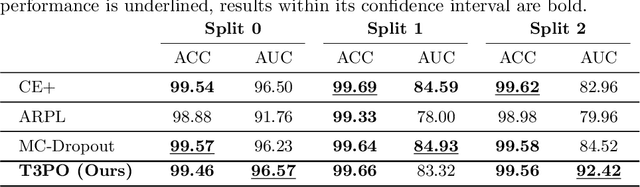
Tissue typology annotation in Whole Slide histological images is a complex and tedious, yet necessary task for the development of computational pathology models. We propose to address this problem by applying Open Set Recognition techniques to the task of jointly classifying tissue that belongs to a set of annotated classes, e.g. clinically relevant tissue categories, while rejecting in test time Open Set samples, i.e. images that belong to categories not present in the training set. To this end, we introduce a new approach for Open Set histopathological image recognition based on training a model to accurately identify image categories and simultaneously predict which data augmentation transform has been applied. In test time, we measure model confidence in predicting this transform, which we expect to be lower for images in the Open Set. We carry out comprehensive experiments in the context of colorectal cancer assessment from histological images, which provide evidence on the strengths of our approach to automatically identify samples from unknown categories. Code is released at https://github.com/agaldran/t3po .