 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Port Berth Identification from Automatic Identification System Data
May 17, 2025



Port berthing sites are regions of high interest for monitoring and optimizing port operations. Data sourced from the Automatic Identification System (AIS) can be superimposed on berths enabling their real-time monitoring and revealing long-term utilization patterns. Ultimately, insights from multiple berths can uncover bottlenecks, and lead to the optimization of the underlying supply chain of the port and beyond. However, publicly available documentation of port berths, even when available, is frequently incomplete - e.g. there may be missing berths or inaccuracies such as incorrect boundary boxes - necessitating a more robust, data-driven approach to port berth localization. In this context, we propose an unsupervised spatial modeling method that leverages AIS data clustering and hyperparameter optimization to identify berthing sites. Trained on one month of freely available AIS data and evaluated across ports of varying sizes, our models significantly outperform competing methods, achieving a mean Bhattacharyya distance of 0.85 when comparing Gaussian Mixture Models (GMMs) trained on separate data splits, compared to 13.56 for the best existing method. Qualitative comparison with satellite images and existing berth labels further supports the superiority of our method, revealing more precise berth boundaries and improved spatial resolution across diverse port environments.
LLM Agents Making Agent Tools
Feb 17, 2025


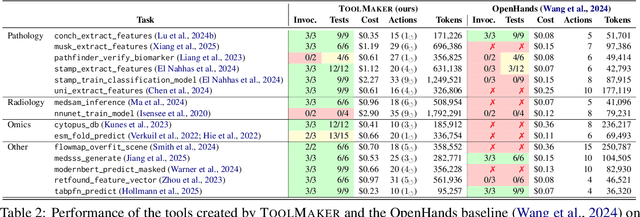
Tool use has turned large language models (LLMs) into powerful agents that can perform complex multi-step tasks by dynamically utilising external software components. However, these tools must be implemented in advance by human developers, hindering the applicability of LLM agents in domains which demand large numbers of highly specialised tools, like in life sciences and medicine. Motivated by the growing trend of scientific studies accompanied by public code repositories, we propose ToolMaker, a novel agentic framework that autonomously transforms papers with code into LLM-compatible tools. Given a short task description and a repository URL, ToolMaker autonomously installs required dependencies and generates code to perform the task, using a closed-loop self-correction mechanism to iteratively diagnose and rectify errors. To evaluate our approach, we introduce a benchmark comprising 15 diverse and complex computational tasks spanning both medical and non-medical domains with over 100 unit tests to objectively assess tool correctness and robustness. ToolMaker correctly implements 80% of the tasks, substantially outperforming current state-of-the-art software engineering agents. ToolMaker therefore is a step towards fully autonomous agent-based scientific workflows.
A Grey-box Attack against Latent Diffusion Model-based Image Editing by Posterior Collapse
Aug 20, 2024
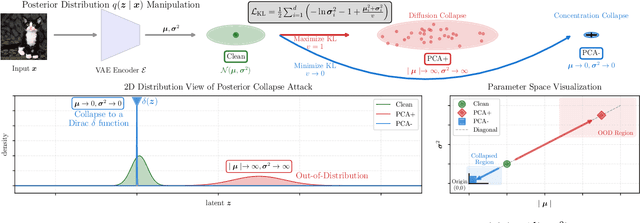


Recent advancements in generative AI, particularly Latent Diffusion Models (LDMs), have revolutionized image synthesis and manipulation. However, these generative techniques raises concerns about data misappropriation and intellectual property infringement. Adversarial attacks on machine learning models have been extensively studied, and a well-established body of research has extended these techniques as a benign metric to prevent the underlying misuse of generative AI. Current approaches to safeguarding images from manipulation by LDMs are limited by their reliance on model-specific knowledge and their inability to significantly degrade semantic quality of generated images. In response to these shortcomings, we propose the Posterior Collapse Attack (PCA) based on the observation that VAEs suffer from posterior collapse during training. Our method minimizes dependence on the white-box information of target models to get rid of the implicit reliance on model-specific knowledge. By accessing merely a small amount of LDM parameters, in specific merely the VAE encoder of LDMs, our method causes a substantial semantic collapse in generation quality, particularly in perceptual consistency, and demonstrates strong transferability across various model architectures. Experimental results show that PCA achieves superior perturbation effects on image generation of LDMs with lower runtime and VRAM. Our method outperforms existing techniques, offering a more robust and generalizable solution that is helpful in alleviating the socio-technical challenges posed by the rapidly evolving landscape of generative AI.
Artwork Protection Against Neural Style Transfer Using Locally Adaptive Adversarial Color Attack
Jan 18, 2024



Neural style transfer (NST) is widely adopted in computer vision to generate new images with arbitrary styles. This process leverages neural networks to merge aesthetic elements of a style image with the structural aspects of a content image into a harmoniously integrated visual result. However, unauthorized NST can exploit artwork. Such misuse raises socio-technical concerns regarding artists' rights and motivates the development of technical approaches for the proactive protection of original creations. Adversarial attack is a concept primarily explored in machine learning security. Our work introduces this technique to protect artists' intellectual property. In this paper Locally Adaptive Adversarial Color Attack (LAACA), a method for altering images in a manner imperceptible to the human eyes but disruptive to NST. Specifically, we design perturbations targeting image areas rich in high-frequency content, generated by disrupting intermediate features. Our experiments and user study confirm that by attacking NST using the proposed method results in visually worse neural style transfer, thus making it an effective solution for visual artwork protection.
A Good Feature Extractor Is All You Need for Weakly Supervised Learning in Histopathology
Nov 29, 2023


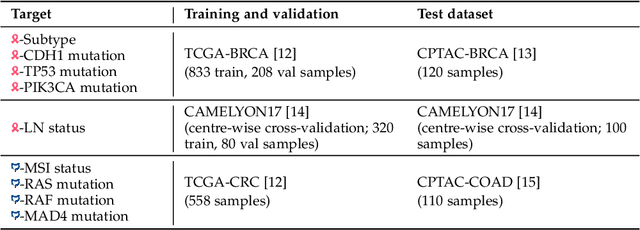
Deep learning is revolutionising pathology, offering novel opportunities in disease prognosis and personalised treatment. Historically, stain normalisation has been a crucial preprocessing step in computational pathology pipelines, and persists into the deep learning era. Yet, with the emergence of feature extractors trained using self-supervised learning (SSL) on diverse pathology datasets, we call this practice into question. In an empirical evaluation of publicly available feature extractors, we find that omitting stain normalisation and image augmentations does not compromise downstream performance, while incurring substantial savings in memory and compute. Further, we show that the top-performing feature extractors are remarkably robust to variations in stain and augmentations like rotation in their latent space. Contrary to previous patch-level benchmarking studies, our approach emphasises clinical relevance by focusing on slide-level prediction tasks in a weakly supervised setting with external validation cohorts. This work represents the most comprehensive robustness evaluation of public pathology SSL feature extractors to date, involving more than 6,000 training runs across nine tasks, five datasets, three downstream architectures, and various preprocessing setups. Our findings stand to streamline digital pathology workflows by minimising preprocessing needs and informing the selection of feature extractors.
Semi-Supervised Crowd Counting with Contextual Modeling: Facilitating Holistic Understanding of Crowd Scenes
Oct 23, 2023To alleviate the heavy annotation burden for training a reliable crowd counting model and thus make the model more practicable and accurate by being able to benefit from more data, this paper presents a new semi-supervised method based on the mean teacher framework. When there is a scarcity of labeled data available, the model is prone to overfit local patches. Within such contexts, the conventional approach of solely improving the accuracy of local patch predictions through unlabeled data proves inadequate. Consequently, we propose a more nuanced approach: fostering the model's intrinsic 'subitizing' capability. This ability allows the model to accurately estimate the count in regions by leveraging its understanding of the crowd scenes, mirroring the human cognitive process. To achieve this goal, we apply masking on unlabeled data, guiding the model to make predictions for these masked patches based on the holistic cues. Furthermore, to help with feature learning, herein we incorporate a fine-grained density classification task. Our method is general and applicable to most existing crowd counting methods as it doesn't have strict structural or loss constraints. In addition, we observe that the model trained with our framework exhibits a 'subitizing'-like behavior. It accurately predicts low-density regions with only a 'glance', while incorporating local details to predict high-density regions. Our method achieves the state-of-the-art performance, surpassing previous approaches by a large margin on challenging benchmarks such as ShanghaiTech A and UCF-QNRF. The code is available at: https://github.com/cha15yq/MRC-Crowd.
A White-Box False Positive Adversarial Attack Method on Contrastive Loss-Based Offline Handwritten Signature Verification Models
Aug 17, 2023


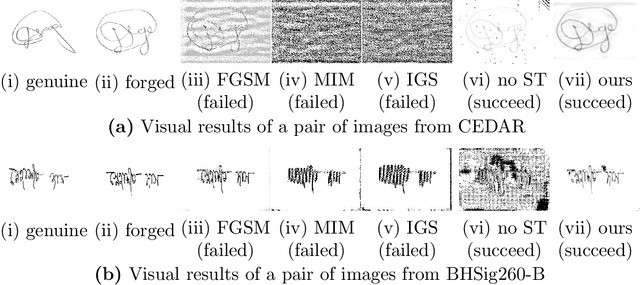
In this paper, we tackle the challenge of white-box false positive adversarial attacks on contrastive loss-based offline handwritten signature verification models. We propose a novel attack method that treats the attack as a style transfer between closely related but distinct writing styles. To guide the generation of deceptive images, we introduce two new loss functions that enhance the attack success rate by perturbing the Euclidean distance between the embedding vectors of the original and synthesized samples, while ensuring minimal perturbations by reducing the difference between the generated image and the original image. Our method demonstrates state-of-the-art performance in white-box attacks on contrastive loss-based offline handwritten signature verification models, as evidenced by our experiments. The key contributions of this paper include a novel false positive attack method, two new loss functions, effective style transfer in handwriting styles, and superior performance in white-box false positive attacks compared to other white-box attack methods.
Deep Multiple Instance Learning with Distance-Aware Self-Attention
May 20, 2023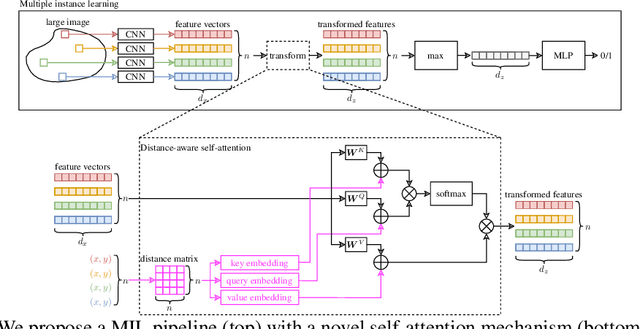
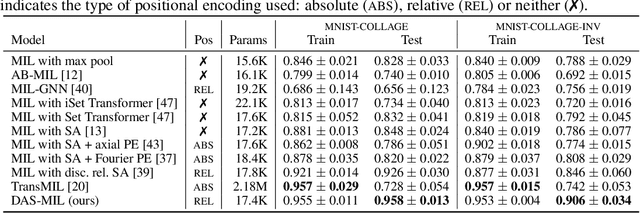

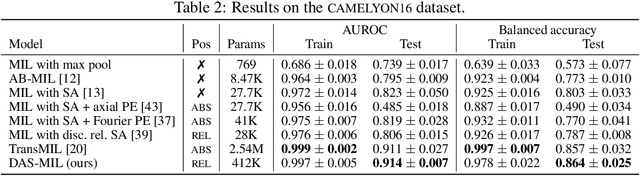
Traditional supervised learning tasks require a label for every instance in the training set, but in many real-world applications, labels are only available for collections (bags) of instances. This problem setting, known as multiple instance learning (MIL), is particularly relevant in the medical domain, where high-resolution images are split into smaller patches, but labels apply to the image as a whole. Recent MIL models are able to capture correspondences between patches by employing self-attention, allowing them to weigh each patch differently based on all other patches in the bag. However, these approaches still do not consider the relative spatial relationships between patches within the larger image, which is especially important in computational pathology. To this end, we introduce a novel MIL model with distance-aware self-attention (DAS-MIL), which explicitly takes into account relative spatial information when modelling the interactions between patches. Unlike existing relative position representations for self-attention which are discrete, our approach introduces continuous distance-dependent terms into the computation of the attention weights, and is the first to apply relative position representations in the context of MIL. We evaluate our model on a custom MNIST-based MIL dataset that requires the consideration of relative spatial information, as well as on CAMELYON16, a publicly available cancer metastasis detection dataset, where we achieve a test AUROC score of 0.91. On both datasets, our model outperforms existing MIL approaches that employ absolute positional encodings, as well as existing relative position representation schemes applied to MIL. Our code is available at https://anonymous.4open.science/r/das-mil.
HoechstGAN: Virtual Lymphocyte Staining Using Generative Adversarial Networks
Oct 17, 2022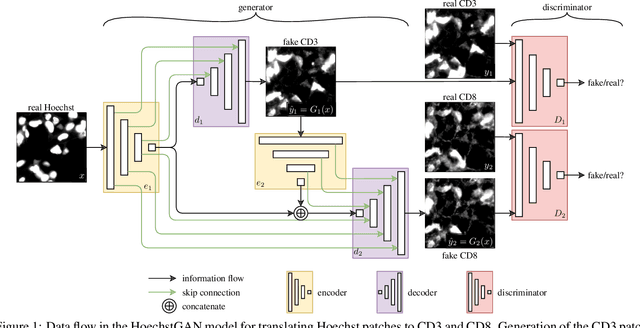


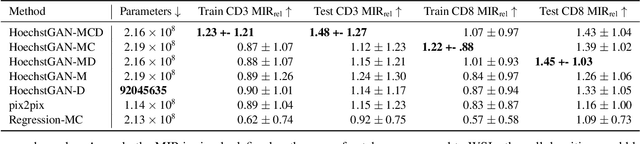
The presence and density of specific types of immune cells are important to understand a patient's immune response to cancer. However, immunofluorescence staining required to identify T cell subtypes is expensive, time-consuming, and rarely performed in clinical settings. We present a framework to virtually stain Hoechst images (which are cheap and widespread) with both CD3 and CD8 to identify T cell subtypes in clear cell renal cell carcinoma using generative adversarial networks. Our proposed method jointly learns both staining tasks, incentivising the network to incorporate mutually beneficial information from each task. We devise a novel metric to quantify the virtual staining quality, and use it to evaluate our method.
MultiPathGAN: Structure Preserving Stain Normalization using Unsupervised Multi-domain Adversarial Network with Perception Loss
Apr 20, 2022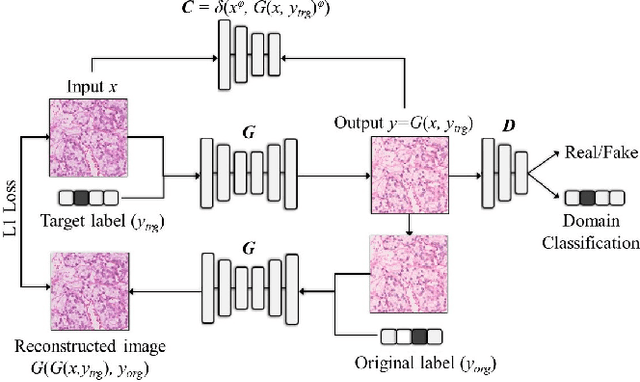
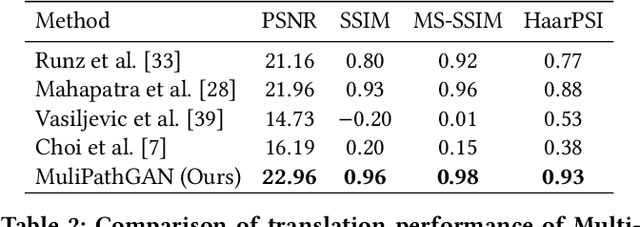
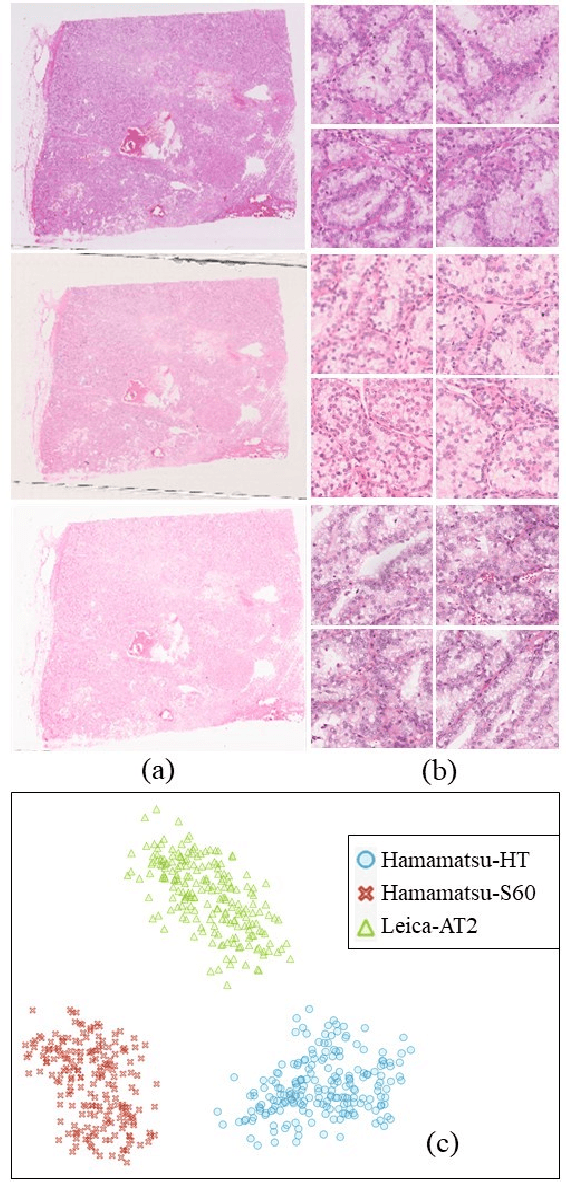
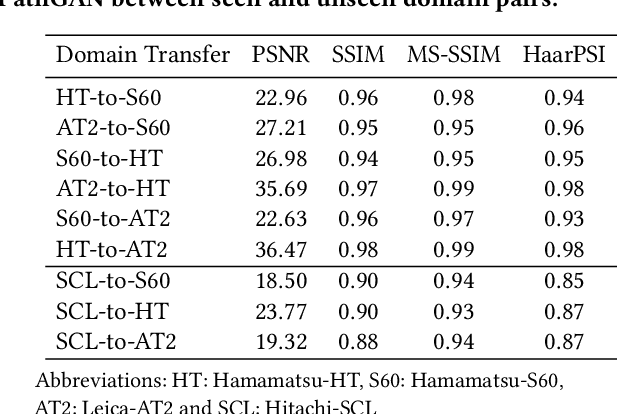
Histopathology relies on the analysis of microscopic tissue images to diagnose disease. A crucial part of tissue preparation is staining whereby a dye is used to make the salient tissue components more distinguishable. However, differences in laboratory protocols and scanning devices result in significant confounding appearance variation in the corresponding images. This variation increases both human error and the inter-rater variability, as well as hinders the performance of automatic or semi-automatic methods. In the present paper we introduce an unsupervised adversarial network to translate (and hence normalize) whole slide images across multiple data acquisition domains. Our key contributions are: (i) an adversarial architecture which learns across multiple domains with a single generator-discriminator network using an information flow branch which optimizes for perceptual loss, and (ii) the inclusion of an additional feature extraction network during training which guides the transformation network to keep all the structural features in the tissue image intact. We: (i) demonstrate the effectiveness of the proposed method firstly on H\&E slides of 120 cases of kidney cancer, as well as (ii) show the benefits of the approach on more general problems, such as flexible illumination based natural image enhancement and light source adaptation.