 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Good Feature Extractor Is All You Need for Weakly Supervised Learning in Histopathology
Nov 29, 2023


Deep learning is revolutionising pathology, offering novel opportunities in disease prognosis and personalised treatment. Historically, stain normalisation has been a crucial preprocessing step in computational pathology pipelines, and persists into the deep learning era. Yet, with the emergence of feature extractors trained using self-supervised learning (SSL) on diverse pathology datasets, we call this practice into question. In an empirical evaluation of publicly available feature extractors, we find that omitting stain normalisation and image augmentations does not compromise downstream performance, while incurring substantial savings in memory and compute. Further, we show that the top-performing feature extractors are remarkably robust to variations in stain and augmentations like rotation in their latent space. Contrary to previous patch-level benchmarking studies, our approach emphasises clinical relevance by focusing on slide-level prediction tasks in a weakly supervised setting with external validation cohorts. This work represents the most comprehensive robustness evaluation of public pathology SSL feature extractors to date, involving more than 6,000 training runs across nine tasks, five datasets, three downstream architectures, and various preprocessing setups. Our findings stand to streamline digital pathology workflows by minimising preprocessing needs and informing the selection of feature extractors.
Regression-based Deep-Learning predicts molecular biomarkers from pathology slides
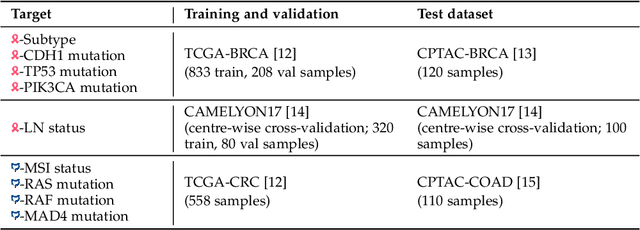
Apr 11, 2023Deep Learning (DL) can predict biomarkers from cancer histopathology. Several clinically approved applications use this technology. Most approaches, however, predict categorical labels, whereas biomarkers are often continuous measurements. We hypothesized that regression-based DL outperforms classification-based DL. Therefore, we developed and evaluated a new self-supervised attention-based weakly supervised regression method that predicts continuous biomarkers directly from images in 11,671 patients across nine cancer types. We tested our method for multiple clinically and biologically relevant biomarkers: homologous repair deficiency (HRD) score, a clinically used pan-cancer biomarker, as well as markers of key biological processes in the tumor microenvironment. Using regression significantly enhances the accuracy of biomarker prediction, while also improving the interpretability of the results over classification. In a large cohort of colorectal cancer patients, regression-based prediction scores provide a higher prognostic value than classification-based scores. Our open-source regression approach offers a promising alternative for continuous biomarker analysis in computational pathology.