 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentityStory: Taming Your Identity-Preserving Generator for Human-Centric Story Generation
Dec 29, 2025Recent visual generative models enable story generation with consistent characters from text, but human-centric story generation faces additional challenges, such as maintaining detailed and diverse human face consistency and coordinating multiple characters across different images. This paper presents IdentityStory, a framework for human-centric story generation that ensures consistent character identity across multiple sequential images. By taming identity-preserving generators, the framework features two key components: Iterative Identity Discovery, which extracts cohesive character identities, and Re-denoising Identity Injection, which re-denoises images to inject identities while preserving desired context. Experiments on the ConsiStory-Human benchmark demonstrate that IdentityStory outperforms existing methods, particularly in face consistency, and supports multi-character combinations. The framework also shows strong potential for applications such as infinite-length story generation and dynamic character composition.
AsyncDiff: Asynchronous Timestep Conditioning for Enhanced Text-to-Image Diffusion Inference
Dec 21, 2025Text-to-image diffusion inference typically follows synchronized schedules, where the numerical integrator advances the latent state to the same timestep at which the denoiser is conditioned. We propose an asynchronous inference mechanism that decouples these two, allowing the denoiser to be conditioned at a different, learned timestep while keeping image update schedule unchanged. A lightweight timestep prediction module (TPM), trained with Group Relative Policy Optimization (GRPO), selects a more feasible conditioning timestep based on the current state, effectively choosing a desired noise level to control image detail and textural richness. At deployment, a scaling hyper-parameter can be used to interpolate between the original and de-synchronized timesteps, enabling conservative or aggressive adjustments. To keep the study computationally affordable, we cap the inference at 15 steps for SD3.5 and 10 steps for Flux. Evaluated on Stable Diffusion 3.5 Medium and Flux.1-dev across MS-COCO 2014 and T2I-CompBench datasets, our method optimizes a composite reward that averages Image Reward, HPSv2, CLIP Score and Pick Score, and shows consistent improvement.
SceneDecorator: Towards Scene-Oriented Story Generation with Scene Planning and Scene Consistency
Oct 27, 2025Recent text-to-image models have revolutionized image generation, but they still struggle with maintaining concept consistency across generated images. While existing works focus on character consistency, they often overlook the crucial role of scenes in storytelling, which restricts their creativity in practice. This paper introduces scene-oriented story generation, addressing two key challenges: (i) scene planning, where current methods fail to ensure scene-level narrative coherence by relying solely on text descriptions, and (ii) scene consistency, which remains largely unexplored in terms of maintaining scene consistency across multiple stories. We propose SceneDecorator, a training-free framework that employs VLM-Guided Scene Planning to ensure narrative coherence across different scenes in a ``global-to-local'' manner, and Long-Term Scene-Sharing Attention to maintain long-term scene consistency and subject diversity across generated stories. Extensive experiments demonstrate the superior performance of SceneDecorator, highlighting its potential to unleash creativity in the fields of arts, films, and games.
HERO: Hierarchical Extrapolation and Refresh for Efficient World Models
Aug 25, 2025
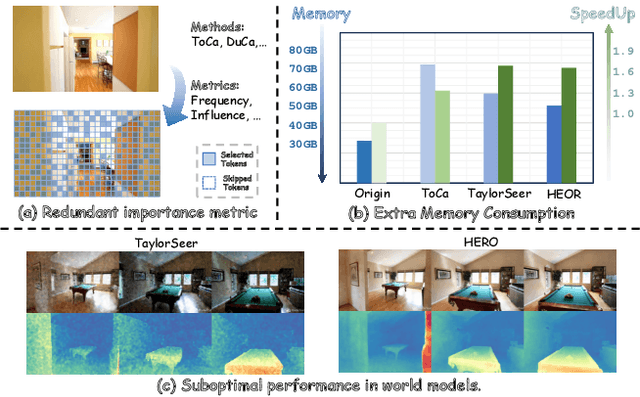
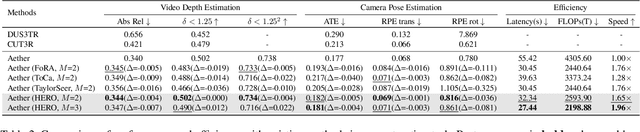

Generation-driven world models create immersive virtual environments but suffer slow inference due to the iterative nature of diffusion models. While recent advances have improved diffusion model efficiency, directly applying these techniques to world models introduces limitations such as quality degradation. In this paper, we present HERO, a training-free hierarchical acceleration framework tailored for efficient world models. Owing to the multi-modal nature of world models, we identify a feature coupling phenomenon, wherein shallow layers exhibit high temporal variability, while deeper layers yield more stable feature representations. Motivated by this, HERO adopts hierarchical strategies to accelerate inference: (i) In shallow layers, a patch-wise refresh mechanism efficiently selects tokens for recomputation. With patch-wise sampling and frequency-aware tracking, it avoids extra metric computation and remain compatible with FlashAttention. (ii) In deeper layers, a linear extrapolation scheme directly estimates intermediate features. This completely bypasses the computations in attention modules and feed-forward networks. Our experiments show that HERO achieves a 1.73$\times$ speedup with minimal quality degradation, significantly outperforming existing diffusion acceleration methods.
Consistent and Controllable Image Animation with Motion Linear Diffusion Transformers
Aug 10, 2025



Image animation has seen significant progress, driven by the powerful generative capabilities of diffusion models. However, maintaining appearance consistency with static input images and mitigating abrupt motion transitions in generated animations remain persistent challenges. While text-to-video (T2V) generation has demonstrated impressive performance with diffusion transformer models, the image animation field still largely relies on U-Net-based diffusion models, which lag behind the latest T2V approaches. Moreover, the quadratic complexity of vanilla self-attention mechanisms in Transformers imposes heavy computational demands, making image animation particularly resource-intensive. To address these issues, we propose MiraMo, a framework designed to enhance efficiency, appearance consistency, and motion smoothness in image animation. Specifically, MiraMo introduces three key elements: (1) A foundational text-to-video architecture replacing vanilla self-attention with efficient linear attention to reduce computational overhead while preserving generation quality; (2) A novel motion residual learning paradigm that focuses on modeling motion dynamics rather than directly predicting frames, improving temporal consistency; and (3) A DCT-based noise refinement strategy during inference to suppress sudden motion artifacts, complemented by a dynamics control module to balance motion smoothness and expressiveness. Extensive experiments against state-of-the-art methods validate the superiority of MiraMo in generating consistent, smooth, and controllable animations with accelerated inference speed. Additionally, we demonstrate the versatility of MiraMo through applications in motion transfer and video editing tasks.
Training-free Stylized Text-to-Image Generation with Fast Inference
May 25, 2025Although diffusion models exhibit impressive generative capabilities, existing methods for stylized image generation based on these models often require textual inversion or fine-tuning with style images, which is time-consuming and limits the practical applicability of large-scale diffusion models. To address these challenges, we propose a novel stylized image generation method leveraging a pre-trained large-scale diffusion model without requiring fine-tuning or any additional optimization, termed as OmniPainter. Specifically, we exploit the self-consistency property of latent consistency models to extract the representative style statistics from reference style images to guide the stylization process. Additionally, we then introduce the norm mixture of self-attention, which enables the model to query the most relevant style patterns from these statistics for the intermediate output content features. This mechanism also ensures that the stylized results align closely with the distribution of the reference style images. Our qualitative and quantitative experimental results demonstrate that the proposed method outperforms state-of-the-art approaches.
3D Surface Reconstruction with Enhanced High-Frequency Details
May 06, 2025Neural implicit 3D reconstruction can reproduce shapes without 3D supervision, and it learns the 3D scene through volume rendering methods and neural implicit representations. Current neural surface reconstruction methods tend to randomly sample the entire image, making it difficult to learn high-frequency details on the surface, and thus the reconstruction results tend to be too smooth. We designed a method (FreNeuS) based on high-frequency information to solve the problem of insufficient surface detail. Specifically, FreNeuS uses pixel gradient changes to easily acquire high-frequency regions in an image and uses the obtained high-frequency information to guide surface detail reconstruction. High-frequency information is first used to guide the dynamic sampling of rays, applying different sampling strategies according to variations in high-frequency regions. To further enhance the focus on surface details, we have designed a high-frequency weighting method that constrains the representation of high-frequency details during the reconstruction process. Qualitative and quantitative results show that our method can reconstruct fine surface details and obtain better surface reconstruction quality compared to existing methods. In addition, our method is more applicable and can be generalized to any NeuS-based work.
Template Matters: Understanding the Role of Instruction Templates in Multimodal Language Model Evaluation and Training
Dec 11, 2024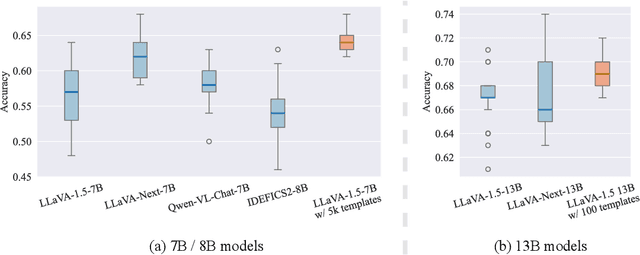
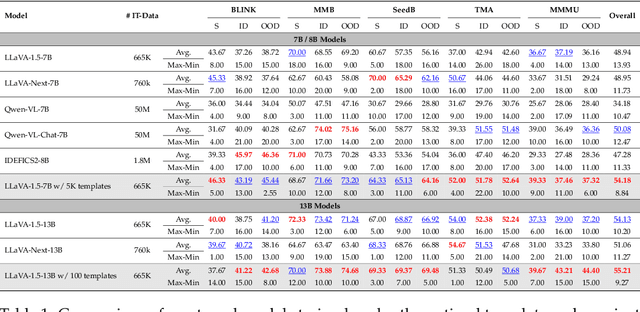

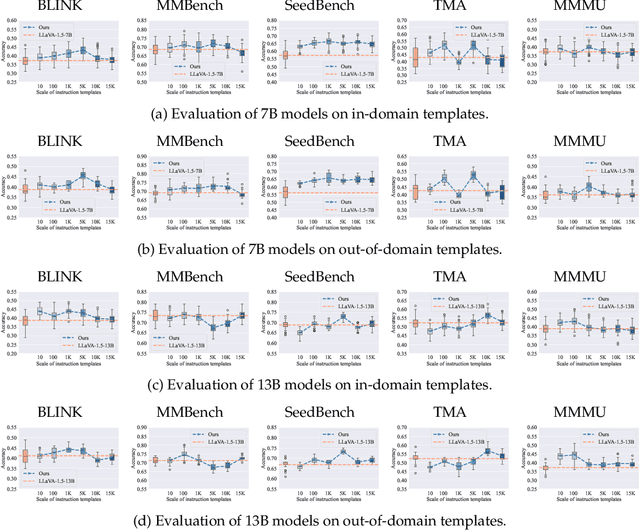
Current multimodal language models (MLMs) evaluation and training approaches overlook the influence of instruction format, presenting an elephant-in-the-room problem. Previous research deals with this problem by manually crafting instructions, failing to yield significant insights due to limitations in diversity and scalability. In this work, we propose a programmatic instruction template generator capable of producing over 39B unique template combinations by filling randomly sampled positional synonyms into weighted sampled meta templates, enabling us to comprehensively examine the MLM's performance across diverse instruction templates. Our experiments across eight common MLMs on five benchmark datasets reveal that MLMs have high template sensitivities with at most 29% performance gaps between different templates. We further augment the instruction tuning dataset of LLaVA-1.5 with our template generator and perform instruction tuning on LLaVA-1.5-7B and LLaVA-1.5-13B. Models tuned on our augmented dataset achieve the best overall performance when compared with the same scale MLMs tuned on at most 75 times the scale of our augmented dataset, highlighting the importance of instruction templates in MLM training. The code is available at https://github.com/shijian2001/TemplateMatters .
REHRSeg: Unleashing the Power of Self-Supervised Super-Resolution for Resource-Efficient 3D MRI Segmentation
Oct 14, 2024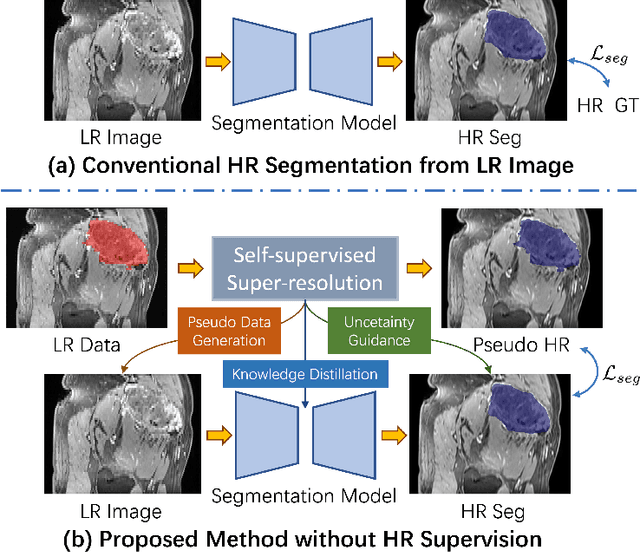
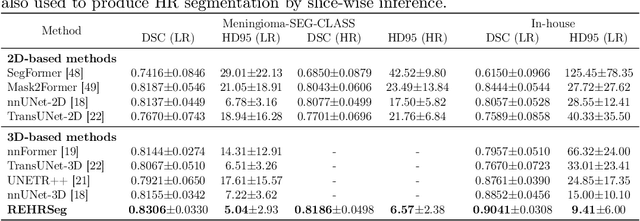
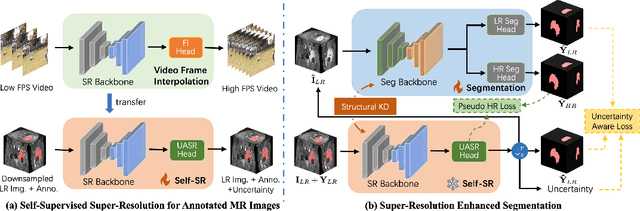
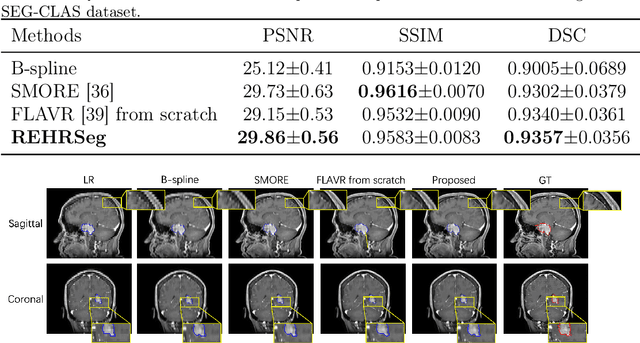
High-resolution (HR) 3D magnetic resonance imaging (MRI) can provide detailed anatomical structural information, enabling precise segmentation of regions of interest for various medical image analysis tasks. Due to the high demands of acquisition device, collection of HR images with their annotations is always impractical in clinical scenarios. Consequently, segmentation results based on low-resolution (LR) images with large slice thickness are often unsatisfactory for subsequent tasks. In this paper, we propose a novel Resource-Efficient High-Resolution Segmentation framework (REHRSeg) to address the above-mentioned challenges in real-world applications, which can achieve HR segmentation while only employing the LR images as input. REHRSeg is designed to leverage self-supervised super-resolution (self-SR) to provide pseudo supervision, therefore the relatively easier-to-acquire LR annotated images generated by 2D scanning protocols can be directly used for model training. The main contribution to ensure the effectiveness in self-SR for enhancing segmentation is three-fold: (1) We mitigate the data scarcity problem in the medical field by using pseudo-data for training the segmentation model. (2) We design an uncertainty-aware super-resolution (UASR) head in self-SR to raise the awareness of segmentation uncertainty as commonly appeared on the ROI boundaries. (3) We align the spatial features for self-SR and segmentation through structural knowledge distillation to enable a better capture of region correlations. Experimental results demonstrate that REHRSeg achieves high-quality HR segmentation without intensive supervision, while also significantly improving the baseline performance for LR segmentation.
A Grey-box Attack against Latent Diffusion Model-based Image Editing by Posterior Collapse
Aug 20, 2024
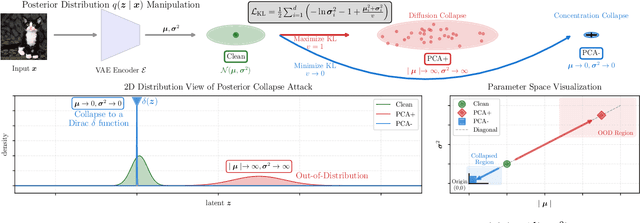


Recent advancements in generative AI, particularly Latent Diffusion Models (LDMs), have revolutionized image synthesis and manipulation. However, these generative techniques raises concerns about data misappropriation and intellectual property infringement. Adversarial attacks on machine learning models have been extensively studied, and a well-established body of research has extended these techniques as a benign metric to prevent the underlying misuse of generative AI. Current approaches to safeguarding images from manipulation by LDMs are limited by their reliance on model-specific knowledge and their inability to significantly degrade semantic quality of generated images. In response to these shortcomings, we propose the Posterior Collapse Attack (PCA) based on the observation that VAEs suffer from posterior collapse during training. Our method minimizes dependence on the white-box information of target models to get rid of the implicit reliance on model-specific knowledge. By accessing merely a small amount of LDM parameters, in specific merely the VAE encoder of LDMs, our method causes a substantial semantic collapse in generation quality, particularly in perceptual consistency, and demonstrates strong transferability across various model architectures. Experimental results show that PCA achieves superior perturbation effects on image generation of LDMs with lower runtime and VRAM. Our method outperforms existing techniques, offering a more robust and generalizable solution that is helpful in alleviating the socio-technical challenges posed by the rapidly evolving landscape of generative AI.