 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTS-Net: Dual-Enhanced Positional Multi-Head Self-Attention for 3D CT Diagnosis of May-Thurner Syndrome
Jun 07, 2024May-Thurner Syndrome (MTS), also known as iliac vein compression syndrome or Cockett's syndrome, is a condition potentially impacting over 20 percent of the population, leading to an increased risk of iliofemoral deep venous thrombosis. In this paper, we present a 3D-based deep learning approach called MTS-Net for diagnosing May-Thurner Syndrome using CT scans. To effectively capture the spatial-temporal relationship among CT scans and emulate the clinical process of diagnosing MTS, we propose a novel attention module called the dual-enhanced positional multi-head self-attention (DEP-MHSA). The proposed DEP-MHSA reconsiders the role of positional embedding and incorporates a dual-enhanced positional embedding in both attention weights and residual connections. Further, we establish a new dataset, termed MTS-CT, consisting of 747 subjects. Experimental results demonstrate that our proposed approach achieves state-of-the-art MTS diagnosis results, and our self-attention design facilitates the spatial-temporal modeling. We believe that our DEP-MHSA is more suitable to handle CT image sequence modeling and the proposed dataset enables future research on MTS diagnosis. We make our code and dataset publicly available at: https://github.com/Nutingnon/MTS_dep_mhsa.
Apodotiko: Enabling Efficient Serverless Federated Learning in Heterogeneous Environments
Apr 22, 2024Federated Learning (FL) is an emerging machine learning paradigm that enables the collaborative training of a shared global model across distributed clients while keeping the data decentralized. Recent works on designing systems for efficient FL have shown that utilizing serverless computing technologies, particularly Function-as-a-Service (FaaS) for FL, can enhance resource efficiency, reduce training costs, and alleviate the complex infrastructure management burden on data holders. However, current serverless FL systems still suffer from the presence of stragglers, i.e., slow clients that impede the collaborative training process. While strategies aimed at mitigating stragglers in these systems have been proposed, they overlook the diverse hardware resource configurations among FL clients. To this end, we present Apodotiko, a novel asynchronous training strategy designed for serverless FL. Our strategy incorporates a scoring mechanism that evaluates each client's hardware capacity and dataset size to intelligently prioritize and select clients for each training round, thereby minimizing the effects of stragglers on system performance. We comprehensively evaluate Apodotiko across diverse datasets, considering a mix of CPU and GPU clients, and compare its performance against five other FL training strategies. Results from our experiments demonstrate that Apodotiko outperforms other FL training strategies, achieving an average speedup of 2.75x and a maximum speedup of 7.03x. Furthermore, our strategy significantly reduces cold starts by a factor of four on average, demonstrating suitability in serverless environments.
Training Heterogeneous Client Models using Knowledge Distillation in Serverless Federated Learning
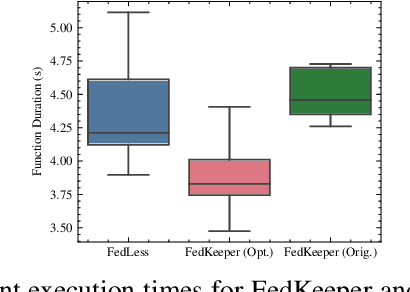
Feb 11, 2024Federated Learning (FL) is an emerging machine learning paradigm that enables the collaborative training of a shared global model across distributed clients while keeping the data decentralized. Recent works on designing systems for efficient FL have shown that utilizing serverless computing technologies, particularly Function-as-a-Service (FaaS) for FL, can enhance resource efficiency, reduce training costs, and alleviate the complex infrastructure management burden on data holders. However, existing serverless FL systems implicitly assume a uniform global model architecture across all participating clients during training. This assumption fails to address fundamental challenges in practical FL due to the resource and statistical data heterogeneity among FL clients. To address these challenges and enable heterogeneous client models in serverless FL, we utilize Knowledge Distillation (KD) in this paper. Towards this, we propose novel optimized serverless workflows for two popular conventional federated KD techniques, i.e., FedMD and FedDF. We implement these workflows by introducing several extensions to an open-source serverless FL system called FedLess. Moreover, we comprehensively evaluate the two strategies on multiple datasets across varying levels of client data heterogeneity using heterogeneous client models with respect to accuracy, fine-grained training times, and costs. Results from our experiments demonstrate that serverless FedDF is more robust to extreme non-IID data distributions, is faster, and leads to lower costs than serverless FedMD. In addition, compared to the original implementation, our optimizations for particular steps in FedMD and FedDF lead to an average speedup of 3.5x and 1.76x across all datasets.
FedLesScan: Mitigating Stragglers in Serverless Federated Learning
Nov 10, 2022Federated Learning (FL) is a machine learning paradigm that enables the training of a shared global model across distributed clients while keeping the training data local. While most prior work on designing systems for FL has focused on using stateful always running components, recent work has shown that components in an FL system can greatly benefit from the usage of serverless computing and Function-as-a-Service technologies. To this end, distributed training of models with severless FL systems can be more resource-efficient and cheaper than conventional FL systems. However, serverless FL systems still suffer from the presence of stragglers, i.e., slow clients due to their resource and statistical heterogeneity. While several strategies have been proposed for mitigating stragglers in FL, most methodologies do not account for the particular characteristics of serverless environments, i.e., cold-starts, performance variations, and the ephemeral stateless nature of the function instances. Towards this, we propose FedLesScan, a novel clustering-based semi-asynchronous training strategy, specifically tailored for serverless FL. FedLesScan dynamically adapts to the behaviour of clients and minimizes the effect of stragglers on the overall system. We implement our strategy by extending an open-source serverless FL system called FedLess. Moreover, we comprehensively evaluate our strategy using the 2nd generation Google Cloud Functions with four datasets and varying percentages of stragglers. Results from our experiments show that compared to other approaches FedLesScan reduces training time and cost by an average of 8% and 20% respectively while utilizing clients better with an average increase in the effective update ratio of 17.75%.
FedLess: Secure and Scalable Federated Learning Using Serverless Computing
Nov 05, 2021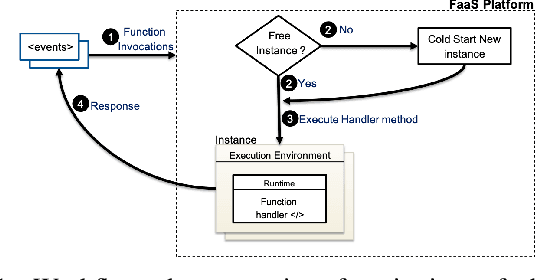
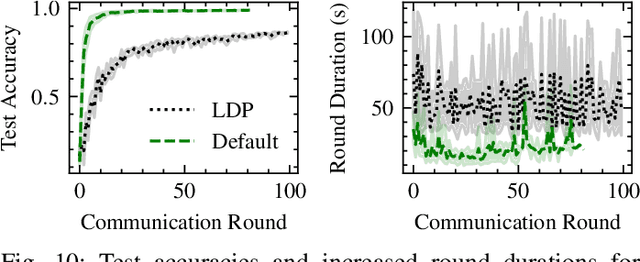
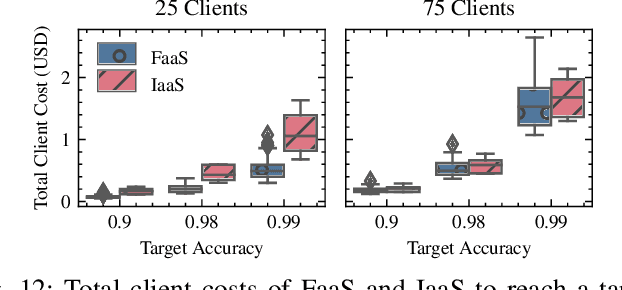
The traditional cloud-centric approach for Deep Learning (DL) requires training data to be collected and processed at a central server which is often challenging in privacy-sensitive domains like healthcare. Towards this, a new learning paradigm called Federated Learning (FL) has been proposed that brings the potential of DL to these domains while addressing privacy and data ownership issues. FL enables remote clients to learn a shared ML model while keeping the data local. However, conventional FL systems face several challenges such as scalability, complex infrastructure management, and wasted compute and incurred costs due to idle clients. These challenges of FL systems closely align with the core problems that serverless computing and Function-as-a-Service (FaaS) platforms aim to solve. These include rapid scalability, no infrastructure management, automatic scaling to zero for idle clients, and a pay-per-use billing model. To this end, we present a novel system and framework for serverless FL, called FedLess. Our system supports multiple commercial and self-hosted FaaS providers and can be deployed in the cloud, on-premise in institutional data centers, and on edge devices. To the best of our knowledge, we are the first to enable FL across a large fabric of heterogeneous FaaS providers while providing important features like security and Differential Privacy. We demonstrate with comprehensive experiments that the successful training of DNNs for different tasks across up to 200 client functions and more is easily possible using our system. Furthermore, we demonstrate the practical viability of our methodology by comparing it against a traditional FL system and show that it can be cheaper and more resource-efficient.