 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand-line Risk Classification using Transformer-based Neural Architectures
Dec 02, 2024


To protect large-scale computing environments necessary to meet increasing computing demand, cloud providers have implemented security measures to monitor Operations and Maintenance (O&M) activities and therefore prevent data loss and service interruption. Command interception systems are used to intercept, assess, and block dangerous Command-line Interface (CLI) commands before they can cause damage. Traditional solutions for command risk assessment include rule-based systems, which require expert knowledge and constant human revision to account for unseen commands. To overcome these limitations, several end-to-end learning systems have been proposed to classify CLI commands. These systems, however, have several other limitations, including the adoption of general-purpose text classifiers, which may not adapt to the language characteristics of scripting languages such as Bash or PowerShell, and may not recognize dangerous commands in the presence of an unbalanced class distribution. In this paper, we propose a transformer-based command risk classification system, which leverages the generalization power of Large Language Models (LLM) to provide accurate classification and the ability to identify rare dangerous commands effectively, by exploiting the power of transfer learning. We verify the effectiveness of our approach on a realistic dataset of production commands and show how to apply our model for other security-related tasks, such as dangerous command interception and auditing of existing rule-based systems.
Apodotiko: Enabling Efficient Serverless Federated Learning in Heterogeneous Environments
Apr 22, 2024Federated Learning (FL) is an emerging machine learning paradigm that enables the collaborative training of a shared global model across distributed clients while keeping the data decentralized. Recent works on designing systems for efficient FL have shown that utilizing serverless computing technologies, particularly Function-as-a-Service (FaaS) for FL, can enhance resource efficiency, reduce training costs, and alleviate the complex infrastructure management burden on data holders. However, current serverless FL systems still suffer from the presence of stragglers, i.e., slow clients that impede the collaborative training process. While strategies aimed at mitigating stragglers in these systems have been proposed, they overlook the diverse hardware resource configurations among FL clients. To this end, we present Apodotiko, a novel asynchronous training strategy designed for serverless FL. Our strategy incorporates a scoring mechanism that evaluates each client's hardware capacity and dataset size to intelligently prioritize and select clients for each training round, thereby minimizing the effects of stragglers on system performance. We comprehensively evaluate Apodotiko across diverse datasets, considering a mix of CPU and GPU clients, and compare its performance against five other FL training strategies. Results from our experiments demonstrate that Apodotiko outperforms other FL training strategies, achieving an average speedup of 2.75x and a maximum speedup of 7.03x. Furthermore, our strategy significantly reduces cold starts by a factor of four on average, demonstrating suitability in serverless environments.
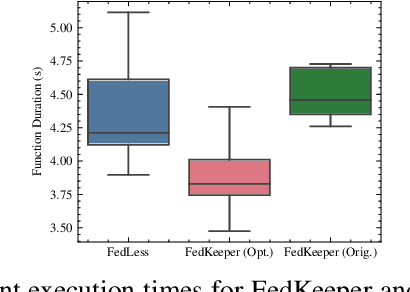
Training Heterogeneous Client Models using Knowledge Distillation in Serverless Federated Learning
Feb 11, 2024
Federated Learning (FL) is an emerging machine learning paradigm that enables the collaborative training of a shared global model across distributed clients while keeping the data decentralized. Recent works on designing systems for efficient FL have shown that utilizing serverless computing technologies, particularly Function-as-a-Service (FaaS) for FL, can enhance resource efficiency, reduce training costs, and alleviate the complex infrastructure management burden on data holders. However, existing serverless FL systems implicitly assume a uniform global model architecture across all participating clients during training. This assumption fails to address fundamental challenges in practical FL due to the resource and statistical data heterogeneity among FL clients. To address these challenges and enable heterogeneous client models in serverless FL, we utilize Knowledge Distillation (KD) in this paper. Towards this, we propose novel optimized serverless workflows for two popular conventional federated KD techniques, i.e., FedMD and FedDF. We implement these workflows by introducing several extensions to an open-source serverless FL system called FedLess. Moreover, we comprehensively evaluate the two strategies on multiple datasets across varying levels of client data heterogeneity using heterogeneous client models with respect to accuracy, fine-grained training times, and costs. Results from our experiments demonstrate that serverless FedDF is more robust to extreme non-IID data distributions, is faster, and leads to lower costs than serverless FedMD. In addition, compared to the original implementation, our optimizations for particular steps in FedMD and FedDF lead to an average speedup of 3.5x and 1.76x across all datasets.
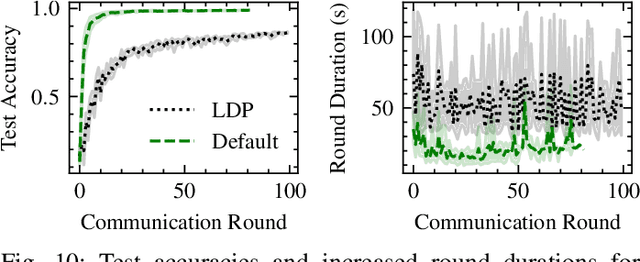
FedLesScan: Mitigating Stragglers in Serverless Federated Learning
Nov 10, 2022Federated Learning (FL) is a machine learning paradigm that enables the training of a shared global model across distributed clients while keeping the training data local. While most prior work on designing systems for FL has focused on using stateful always running components, recent work has shown that components in an FL system can greatly benefit from the usage of serverless computing and Function-as-a-Service technologies. To this end, distributed training of models with severless FL systems can be more resource-efficient and cheaper than conventional FL systems. However, serverless FL systems still suffer from the presence of stragglers, i.e., slow clients due to their resource and statistical heterogeneity. While several strategies have been proposed for mitigating stragglers in FL, most methodologies do not account for the particular characteristics of serverless environments, i.e., cold-starts, performance variations, and the ephemeral stateless nature of the function instances. Towards this, we propose FedLesScan, a novel clustering-based semi-asynchronous training strategy, specifically tailored for serverless FL. FedLesScan dynamically adapts to the behaviour of clients and minimizes the effect of stragglers on the overall system. We implement our strategy by extending an open-source serverless FL system called FedLess. Moreover, we comprehensively evaluate our strategy using the 2nd generation Google Cloud Functions with four datasets and varying percentages of stragglers. Results from our experiments show that compared to other approaches FedLesScan reduces training time and cost by an average of 8% and 20% respectively while utilizing clients better with an average increase in the effective update ratio of 17.75%.
IAD: Indirect Anomalous VMMs Detection in the Cloud-based Environment
Nov 22, 2021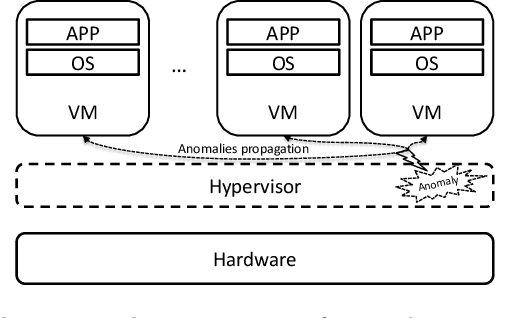

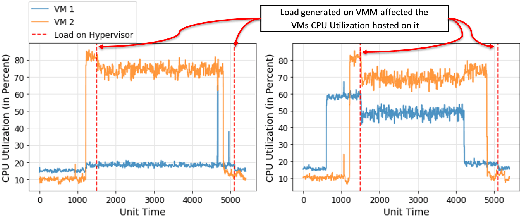
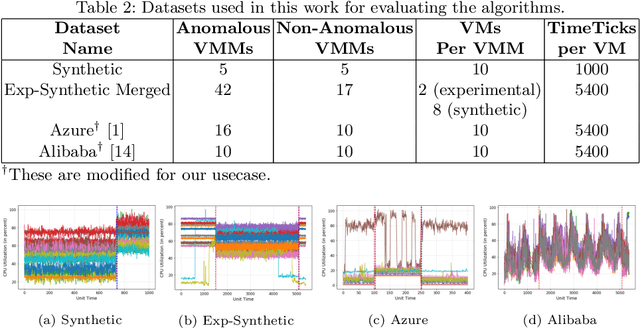
Server virtualization in the form of virtual machines (VMs) with the use of a hypervisor or a Virtual Machine Monitor (VMM) is an essential part of cloud computing technology to provide infrastructure-as-a-service (IaaS). A fault or an anomaly in the VMM can propagate to the VMs hosted on it and ultimately affect the availability and reliability of the applications running on those VMs. Therefore, identifying and eventually resolving it quickly is highly important. However, anomalous VMM detection is a challenge in the cloud environment since the user does not have access to the VMM. This paper addresses this challenge of anomalous VMM detection in the cloud-based environment without having any knowledge or data from VMM by introducing a novel machine learning-based algorithm called IAD: Indirect Anomalous VMMs Detection. This algorithm solely uses the VM's resources utilization data hosted on those VMMs for the anomalous VMMs detection. The developed algorithm's accuracy was tested on four datasets comprising the synthetic and real and compared against four other popular algorithms, which can also be used to the described problem. It was found that the proposed IAD algorithm has an average F1-score of 83.7% averaged across four datasets, and also outperforms other algorithms by an average F1-score of 11\%.
FedLess: Secure and Scalable Federated Learning Using Serverless Computing
Nov 05, 2021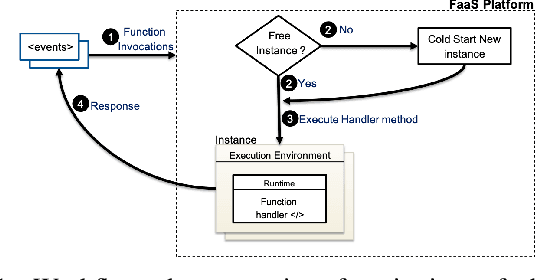
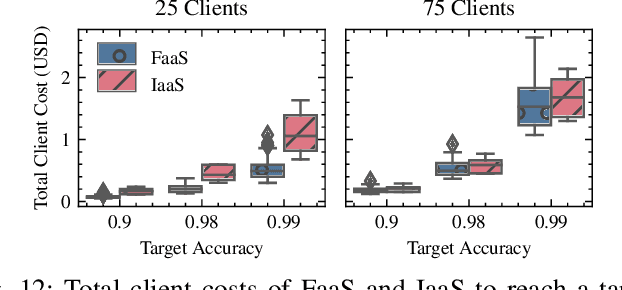
The traditional cloud-centric approach for Deep Learning (DL) requires training data to be collected and processed at a central server which is often challenging in privacy-sensitive domains like healthcare. Towards this, a new learning paradigm called Federated Learning (FL) has been proposed that brings the potential of DL to these domains while addressing privacy and data ownership issues. FL enables remote clients to learn a shared ML model while keeping the data local. However, conventional FL systems face several challenges such as scalability, complex infrastructure management, and wasted compute and incurred costs due to idle clients. These challenges of FL systems closely align with the core problems that serverless computing and Function-as-a-Service (FaaS) platforms aim to solve. These include rapid scalability, no infrastructure management, automatic scaling to zero for idle clients, and a pay-per-use billing model. To this end, we present a novel system and framework for serverless FL, called FedLess. Our system supports multiple commercial and self-hosted FaaS providers and can be deployed in the cloud, on-premise in institutional data centers, and on edge devices. To the best of our knowledge, we are the first to enable FL across a large fabric of heterogeneous FaaS providers while providing important features like security and Differential Privacy. We demonstrate with comprehensive experiments that the successful training of DNNs for different tasks across up to 200 client functions and more is easily possible using our system. Furthermore, we demonstrate the practical viability of our methodology by comparing it against a traditional FL system and show that it can be cheaper and more resource-efficient.
DeepEdgeBench: Benchmarking Deep Neural Networks on Edge Devices
Aug 21, 2021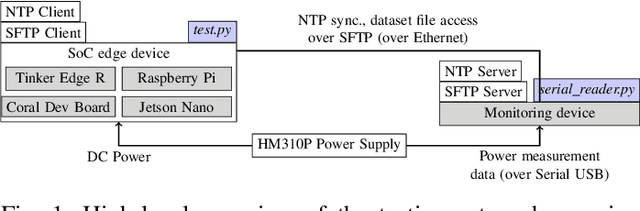
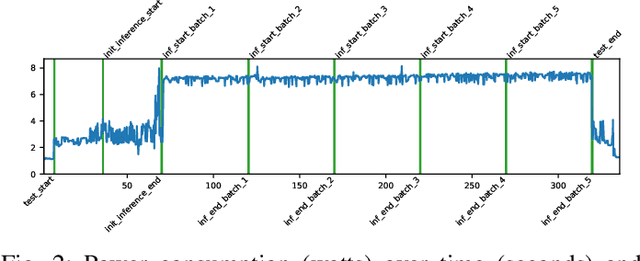

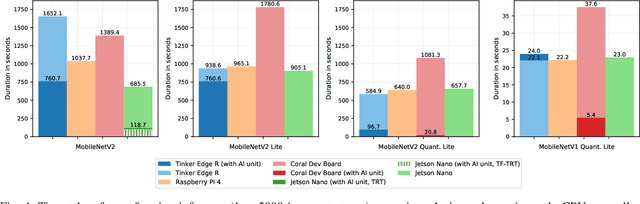
EdgeAI (Edge computing based Artificial Intelligence) has been most actively researched for the last few years to handle variety of massively distributed AI applications to meet up the strict latency requirements. Meanwhile, many companies have released edge devices with smaller form factors (low power consumption and limited resources) like the popular Raspberry Pi and Nvidia's Jetson Nano for acting as compute nodes at the edge computing environments. Although the edge devices are limited in terms of computing power and hardware resources, they are powered by accelerators to enhance their performance behavior. Therefore, it is interesting to see how AI-based Deep Neural Networks perform on such devices with limited resources. In this work, we present and compare the performance in terms of inference time and power consumption of the four Systems on a Chip (SoCs): Asus Tinker Edge R, Raspberry Pi 4, Google Coral Dev Board, Nvidia Jetson Nano, and one microcontroller: Arduino Nano 33 BLE, on different deep learning models and frameworks. We also provide a method for measuring power consumption, inference time and accuracy for the devices, which can be easily extended to other devices. Our results showcase that, for Tensorflow based quantized model, the Google Coral Dev Board delivers the best performance, both for inference time and power consumption. For a low fraction of inference computation time, i.e. less than 29.3% of the time for MobileNetV2, the Jetson Nano performs faster than the other devices.
Online Memory Leak Detection in the Cloud-based Infrastructures
Jan 24, 2021
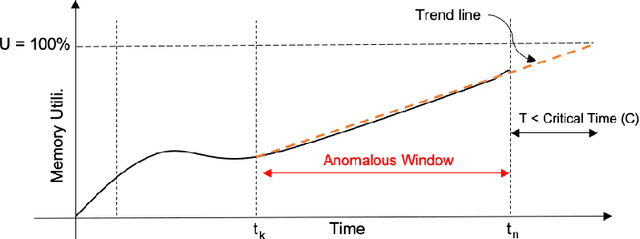
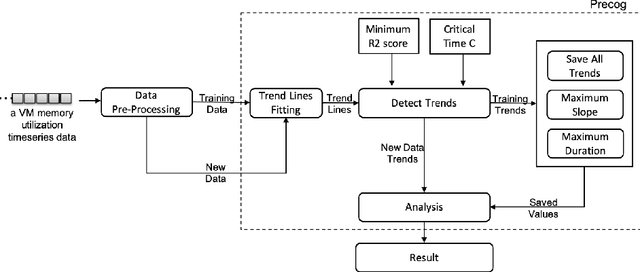
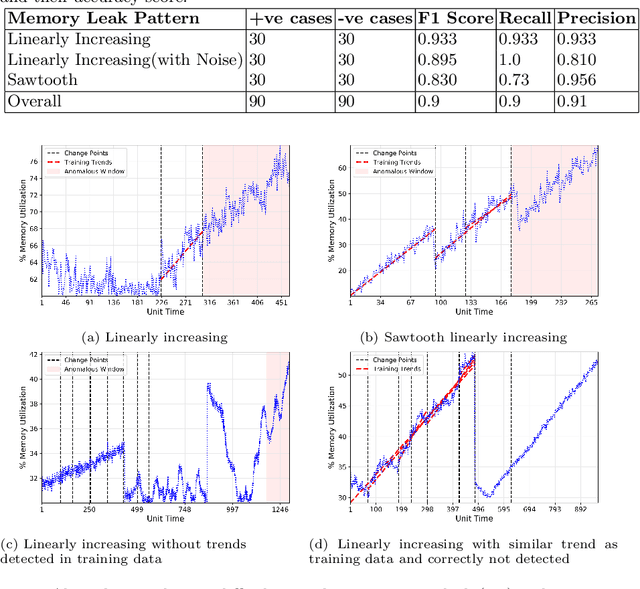
A memory leak in an application deployed on the cloud can affect the availability and reliability of the application. Therefore, to identify and ultimately resolve it quickly is highly important. However, in the production environment running on the cloud, memory leak detection is a challenge without the knowledge of the application or its internal object allocation details. This paper addresses this challenge of online detection of memory leaks in cloud-based infrastructure without having any internal application knowledge by introducing a novel machine learning based algorithm Precog. This algorithm solely uses one metric i.e the system's memory utilization on which the application is deployed for the detection of a memory leak. The developed algorithm's accuracy was tested on 60 virtual machines manually labeled memory utilization data provided by our industry partner Huawei Munich Research Center and it was found that the proposed algorithm achieves the accuracy score of 85\% with less than half a second prediction time per virtual machine.
* 12 pages
A Systematic Mapping Study in AIOps
Dec 15, 2020
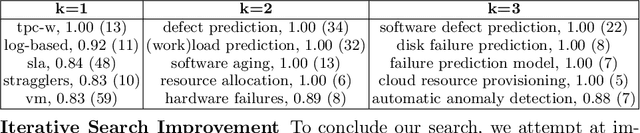
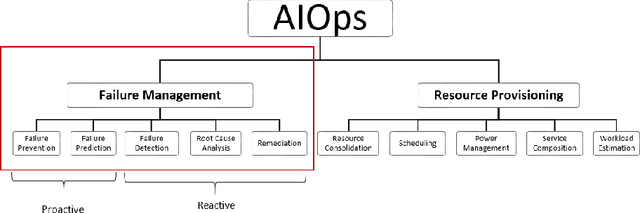
IT systems of today are becoming larger and more complex, rendering their human supervision more difficult. Artificial Intelligence for IT Operations (AIOps) has been proposed to tackle modern IT administration challenges thanks to AI and Big Data. However, past AIOps contributions are scattered, unorganized and missing a common terminology convention, which renders their discovery and comparison impractical. In this work, we conduct an in-depth mapping study to collect and organize the numerous scattered contributions to AIOps in a unique reference index. We create an AIOps taxonomy to build a foundation for future contributions and allow an efficient comparison of AIOps papers treating similar problems. We investigate temporal trends and classify AIOps contributions based on the choice of algorithms, data sources and the target components. Our results show a recent and growing interest towards AIOps, specifically to those contributions treating failure-related tasks (62%), such as anomaly detection and root cause analysis.