 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTS-Net: Dual-Enhanced Positional Multi-Head Self-Attention for 3D CT Diagnosis of May-Thurner Syndrome
Jun 07, 2024May-Thurner Syndrome (MTS), also known as iliac vein compression syndrome or Cockett's syndrome, is a condition potentially impacting over 20 percent of the population, leading to an increased risk of iliofemoral deep venous thrombosis. In this paper, we present a 3D-based deep learning approach called MTS-Net for diagnosing May-Thurner Syndrome using CT scans. To effectively capture the spatial-temporal relationship among CT scans and emulate the clinical process of diagnosing MTS, we propose a novel attention module called the dual-enhanced positional multi-head self-attention (DEP-MHSA). The proposed DEP-MHSA reconsiders the role of positional embedding and incorporates a dual-enhanced positional embedding in both attention weights and residual connections. Further, we establish a new dataset, termed MTS-CT, consisting of 747 subjects. Experimental results demonstrate that our proposed approach achieves state-of-the-art MTS diagnosis results, and our self-attention design facilitates the spatial-temporal modeling. We believe that our DEP-MHSA is more suitable to handle CT image sequence modeling and the proposed dataset enables future research on MTS diagnosis. We make our code and dataset publicly available at: https://github.com/Nutingnon/MTS_dep_mhsa.
ECM-OPCC: Efficient Context Model for Octree-based Point Cloud Compression
Nov 22, 2022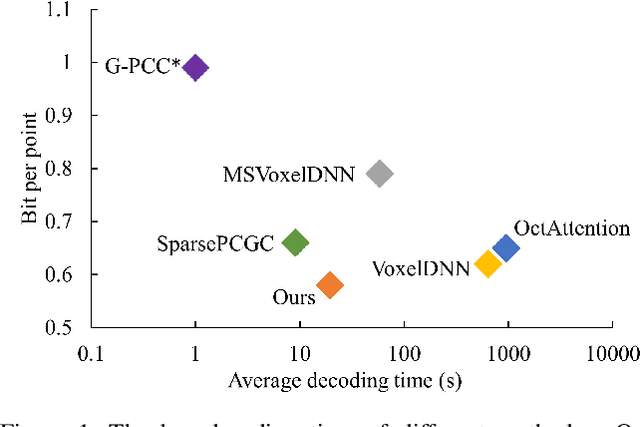
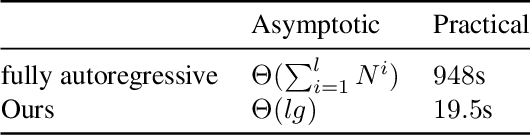
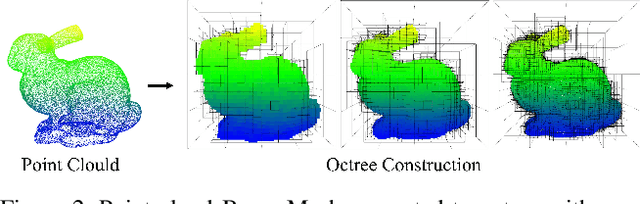
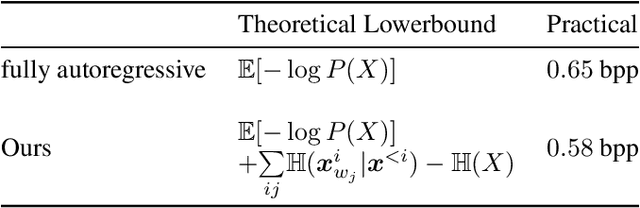
Recently, deep learning methods have shown promising results in point cloud compression. For octree-based point cloud compression, previous works show that the information of ancestor nodes and sibling nodes are equally important for predicting current node. However, those works either adopt insufficient context or bring intolerable decoding complexity (e.g. >600s). To address this problem, we propose a sufficient yet efficient context model and design an efficient deep learning codec for point clouds. Specifically, we first propose a window-constrained multi-group coding strategy to exploit the autoregressive context while maintaining decoding efficiency. Then, we propose a dual transformer architecture to utilize the dependency of current node on its ancestors and siblings. We also propose a random-masking pre-train method to enhance our model. Experimental results show that our approach achieves state-of-the-art performance for both lossy and lossless point cloud compression. Moreover, our multi-group coding strategy saves 98% decoding time compared with previous octree-based compression method.