 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Enhancing VLM for Compressed Image Understanding
Dec 24, 2025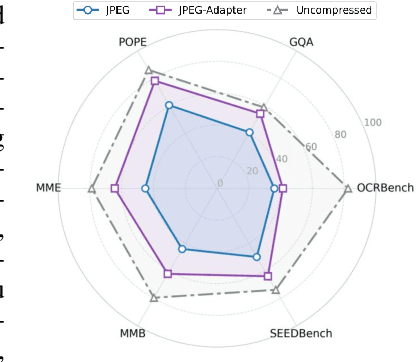


With the rapid development of Vision-Language Models (VLMs) and the growing demand for their applications, efficient compression of the image inputs has become increasingly important. Existing VLMs predominantly digest and understand high-bitrate compressed images, while their ability to interpret low-bitrate compressed images has yet to be explored by far. In this paper, we introduce the first comprehensive benchmark to evaluate the ability of VLM against compressed images, varying existing widely used image codecs and diverse set of tasks, encompassing over one million compressed images in our benchmark. Next, we analyse the source of performance gap, by categorising the gap from a) the information loss during compression and b) generalisation failure of VLM. We visualize these gaps with concrete examples and identify that for compressed images, only the generalization gap can be mitigated. Finally, we propose a universal VLM adaptor to enhance model performance on images compressed by existing codecs. Consequently, we demonstrate that a single adaptor can improve VLM performance across images with varying codecs and bitrates by 10%-30%. We believe that our benchmark and enhancement method provide valuable insights and contribute toward bridging the gap between VLMs and compressed images.
GaussianImage++: Boosted Image Representation and Compression with 2D Gaussian Splatting
Dec 22, 2025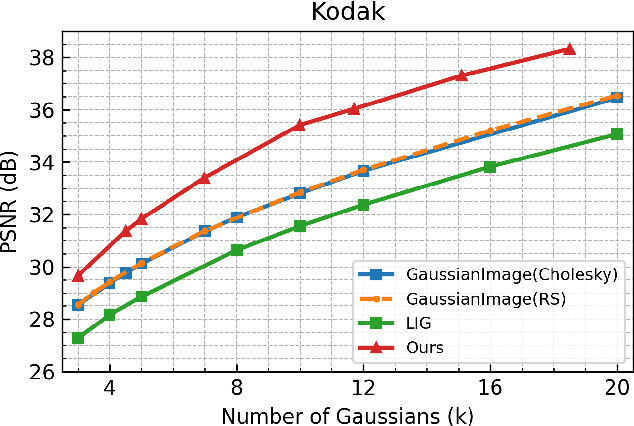
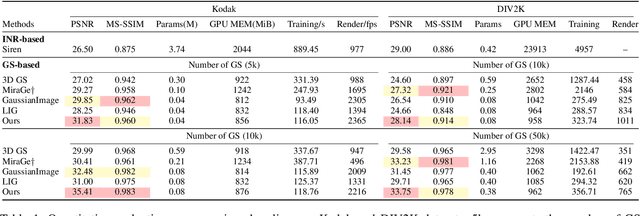
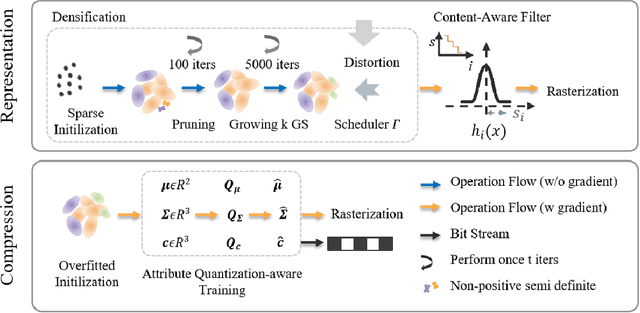

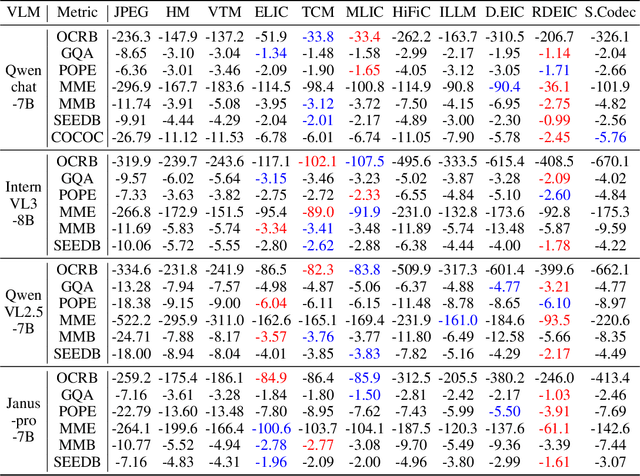
Implicit neural representations (INRs) have achieved remarkable success in image representation and compression, but they require substantial training time and memory. Meanwhile, recent 2D Gaussian Splatting (GS) methods (\textit{e.g.}, GaussianImage) offer promising alternatives through efficient primitive-based rendering. However, these methods require excessive Gaussian primitives to maintain high visual fidelity. To exploit the potential of GS-based approaches, we present GaussianImage++, which utilizes limited Gaussian primitives to achieve impressive representation and compression performance. Firstly, we introduce a distortion-driven densification mechanism. It progressively allocates Gaussian primitives according to signal intensity. Secondly, we employ context-aware Gaussian filters for each primitive, which assist in the densification to optimize Gaussian primitives based on varying image content. Thirdly, we integrate attribute-separated learnable scalar quantizers and quantization-aware training, enabling efficient compression of primitive attributes. Experimental results demonstrate the effectiveness of our method. In particular, GaussianImage++ outperforms GaussianImage and INRs-based COIN in representation and compression performance while maintaining real-time decoding and low memory usage.
Optimizing Input of Denoising Score Matching is Biased Towards Higher Score Norm
Nov 13, 2025Many recent works utilize denoising score matching to optimize the conditional input of diffusion models. In this workshop paper, we demonstrate that such optimization breaks the equivalence between denoising score matching and exact score matching. Furthermore, we show that this bias leads to higher score norm. Additionally, we observe a similar bias when optimizing the data distribution using a pre-trained diffusion model. Finally, we discuss the wide range of works across different domains that are affected by this bias, including MAR for auto-regressive generation, PerCo for image compression, and DreamFusion for text to 3D generation.
Generative AI Meets 6G and Beyond: Diffusion Models for Semantic Communications
Nov 11, 2025Semantic communications mark a paradigm shift from bit-accurate transmission toward meaning-centric communication, essential as wireless systems approach theoretical capacity limits. The emergence of generative AI has catalyzed generative semantic communications, where receivers reconstruct content from minimal semantic cues by leveraging learned priors. Among generative approaches, diffusion models stand out for their superior generation quality, stable training dynamics, and rigorous theoretical foundations. However, the field currently lacks systematic guidance connecting diffusion techniques to communication system design, forcing researchers to navigate disparate literatures. This article provides the first comprehensive tutorial on diffusion models for generative semantic communications. We present score-based diffusion foundations and systematically review three technical pillars: conditional diffusion for controllable generation, efficient diffusion for accelerated inference, and generalized diffusion for cross-domain adaptation. In addition, we introduce an inverse problem perspective that reformulates semantic decoding as posterior inference, bridging semantic communications with computational imaging. Through analysis of human-centric, machine-centric, and agent-centric scenarios, we illustrate how diffusion models enable extreme compression while maintaining semantic fidelity and robustness. By bridging generative AI innovations with communication system design, this article aims to establish diffusion models as foundational components of next-generation wireless networks and beyond.
V-Shuffle: Zero-Shot Style Transfer via Value Shuffle
Nov 09, 2025



Attention injection-based style transfer has achieved remarkable progress in recent years. However, existing methods often suffer from content leakage, where the undesired semantic content of the style image mistakenly appears in the stylized output. In this paper, we propose V-Shuffle, a zero-shot style transfer method that leverages multiple style images from the same style domain to effectively navigate the trade-off between content preservation and style fidelity. V-Shuffle implicitly disrupts the semantic content of the style images by shuffling the value features within the self-attention layers of the diffusion model, thereby preserving low-level style representations. We further introduce a Hybrid Style Regularization that complements these low-level representations with high-level style textures to enhance style fidelity. Empirical results demonstrate that V-Shuffle achieves excellent performance when utilizing multiple style images. Moreover, when applied to a single style image, V-Shuffle outperforms previous state-of-the-art methods.
PICD: Versatile Perceptual Image Compression with Diffusion Rendering
May 09, 2025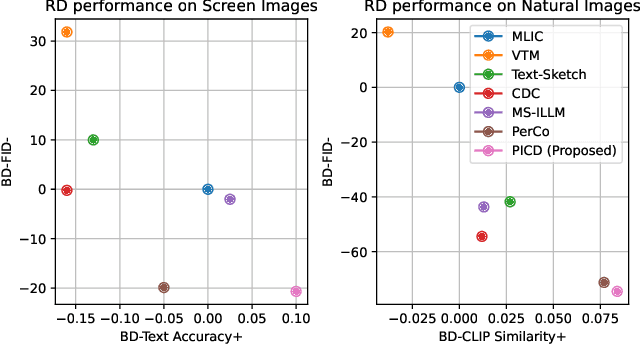
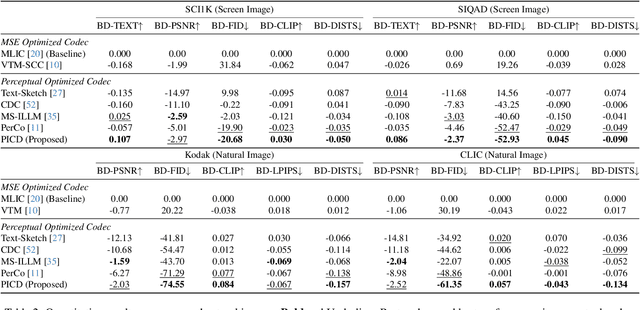
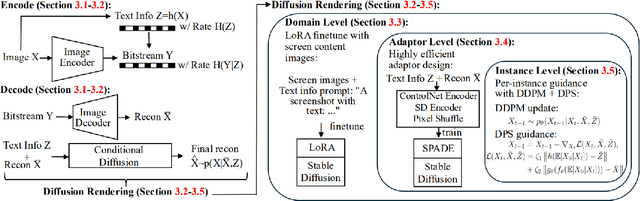
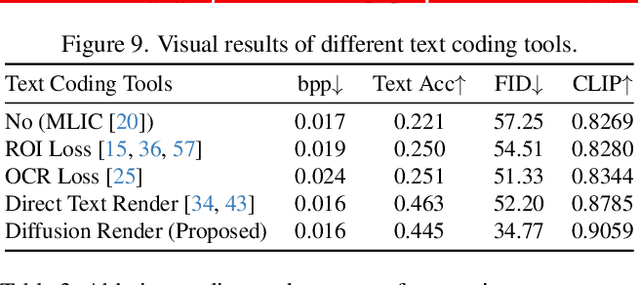
Recently, perceptual image compression has achieved significant advancements, delivering high visual quality at low bitrates for natural images. However, for screen content, existing methods often produce noticeable artifacts when compressing text. To tackle this challenge, we propose versatile perceptual screen image compression with diffusion rendering (PICD), a codec that works well for both screen and natural images. More specifically, we propose a compression framework that encodes the text and image separately, and renders them into one image using diffusion model. For this diffusion rendering, we integrate conditional information into diffusion models at three distinct levels: 1). Domain level: We fine-tune the base diffusion model using text content prompts with screen content. 2). Adaptor level: We develop an efficient adaptor to control the diffusion model using compressed image and text as input. 3). Instance level: We apply instance-wise guidance to further enhance the decoding process. Empirically, our PICD surpasses existing perceptual codecs in terms of both text accuracy and perceptual quality. Additionally, without text conditions, our approach serves effectively as a perceptual codec for natural images.
CoopDETR: A Unified Cooperative Perception Framework for 3D Detection via Object Query
Feb 26, 2025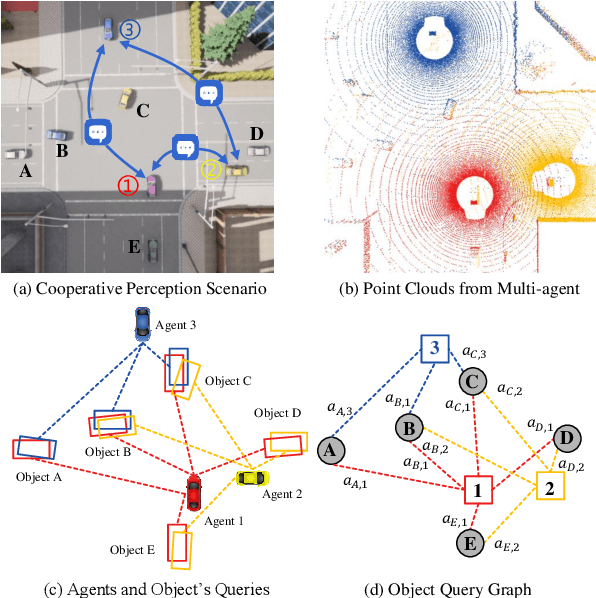
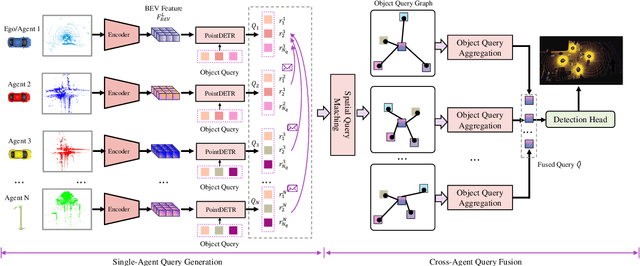
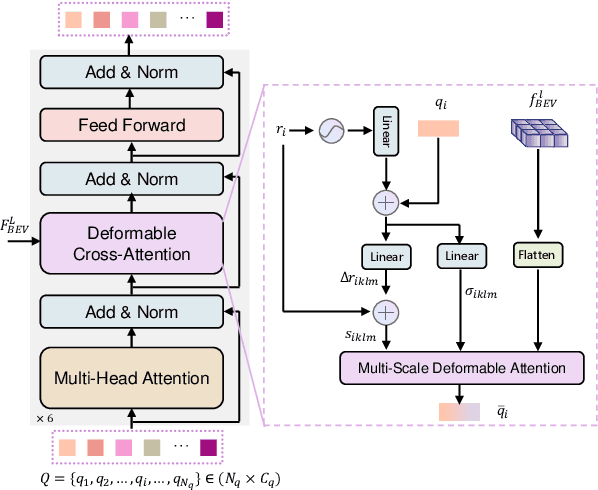
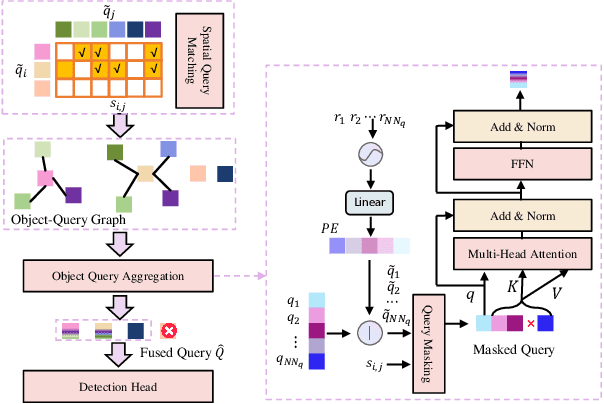
Cooperative perception enhances the individual perception capabilities of autonomous vehicles (AVs) by providing a comprehensive view of the environment. However, balancing perception performance and transmission costs remains a significant challenge. Current approaches that transmit region-level features across agents are limited in interpretability and demand substantial bandwidth, making them unsuitable for practical applications. In this work, we propose CoopDETR, a novel cooperative perception framework that introduces object-level feature cooperation via object query. Our framework consists of two key modules: single-agent query generation, which efficiently encodes raw sensor data into object queries, reducing transmission cost while preserving essential information for detection; and cross-agent query fusion, which includes Spatial Query Matching (SQM) and Object Query Aggregation (OQA) to enable effective interaction between queries. Our experiments on the OPV2V and V2XSet datasets demonstrate that CoopDETR achieves state-of-the-art performance and significantly reduces transmission costs to 1/782 of previous methods.
Rethinking Diffusion Posterior Sampling: From Conditional Score Estimator to Maximizing a Posterior
Jan 31, 2025Recent advancements in diffusion models have been leveraged to address inverse problems without additional training, and Diffusion Posterior Sampling (DPS) (Chung et al., 2022a) is among the most popular approaches. Previous analyses suggest that DPS accomplishes posterior sampling by approximating the conditional score. While in this paper, we demonstrate that the conditional score approximation employed by DPS is not as effective as previously assumed, but rather aligns more closely with the principle of maximizing a posterior (MAP). This assertion is substantiated through an examination of DPS on 512x512 ImageNet images, revealing that: 1) DPS's conditional score estimation significantly diverges from the score of a well-trained conditional diffusion model and is even inferior to the unconditional score; 2) The mean of DPS's conditional score estimation deviates significantly from zero, rendering it an invalid score estimation; 3) DPS generates high-quality samples with significantly lower diversity. In light of the above findings, we posit that DPS more closely resembles MAP than a conditional score estimator, and accordingly propose the following enhancements to DPS: 1) we explicitly maximize the posterior through multi-step gradient ascent and projection; 2) we utilize a light-weighted conditional score estimator trained with only 100 images and 8 GPU hours. Extensive experimental results indicate that these proposed improvements significantly enhance DPS's performance. The source code for these improvements is provided in https://github.com/tongdaxu/Rethinking-Diffusion-Posterior-Sampling-From-Conditional-Score-Estimator-to-Maximizing-a-Posterior.
MEGA: Memory-Efficient 4D Gaussian Splatting for Dynamic Scenes
Oct 17, 20244D Gaussian Splatting (4DGS) has recently emerged as a promising technique for capturing complex dynamic 3D scenes with high fidelity. It utilizes a 4D Gaussian representation and a GPU-friendly rasterizer, enabling rapid rendering speeds. Despite its advantages, 4DGS faces significant challenges, notably the requirement of millions of 4D Gaussians, each with extensive associated attributes, leading to substantial memory and storage cost. This paper introduces a memory-efficient framework for 4DGS. We streamline the color attribute by decomposing it into a per-Gaussian direct color component with only 3 parameters and a shared lightweight alternating current color predictor. This approach eliminates the need for spherical harmonics coefficients, which typically involve up to 144 parameters in classic 4DGS, thereby creating a memory-efficient 4D Gaussian representation. Furthermore, we introduce an entropy-constrained Gaussian deformation technique that uses a deformation field to expand the action range of each Gaussian and integrates an opacity-based entropy loss to limit the number of Gaussians, thus forcing our model to use as few Gaussians as possible to fit a dynamic scene well. With simple half-precision storage and zip compression, our framework achieves a storage reduction by approximately 190$\times$ and 125$\times$ on the Technicolor and Neural 3D Video datasets, respectively, compared to the original 4DGS. Meanwhile, it maintains comparable rendering speeds and scene representation quality, setting a new standard in the field.
Task-Aware Encoder Control for Deep Video Compression
Apr 07, 2024



Prior research on deep video compression (DVC) for machine tasks typically necessitates training a unique codec for each specific task, mandating a dedicated decoder per task. In contrast, traditional video codecs employ a flexible encoder controller, enabling the adaptation of a single codec to different tasks through mechanisms like mode prediction. Drawing inspiration from this, we introduce an innovative encoder controller for deep video compression for machines. This controller features a mode prediction and a Group of Pictures (GoP) selection module. Our approach centralizes control at the encoding stage, allowing for adaptable encoder adjustments across different tasks, such as detection and tracking, while maintaining compatibility with a standard pre-trained DVC decoder. Empirical evidence demonstrates that our method is applicable across multiple tasks with various existing pre-trained DVCs. Moreover, extensive experiments demonstrate that our method outperforms previous DVC by about 25% bitrate for different tasks, with only one pre-trained decoder.