 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-VLA: Spatially-Aware Flow-Matching for Vision-Language-Action Reinforcement Learning
Jan 31, 2026Vision-Language-Action (VLA) models exhibit strong generalization in robotic manipulation, yet reinforcement learning (RL) fine-tuning often degrades robustness under spatial distribution shifts. For flow-matching VLA policies, this degradation is closely associated with the erosion of spatial inductive bias during RL adaptation, as sparse rewards and spatially agnostic exploration increasingly favor short-horizon visual cues. To address this issue, we propose \textbf{SA-VLA}, a spatially-aware RL adaptation framework that preserves spatial grounding during policy optimization by aligning representation learning, reward design, and exploration with task geometry. SA-VLA fuses implicit spatial representations with visual tokens, provides dense rewards that reflect geometric progress, and employs \textbf{SCAN}, a spatially-conditioned annealed exploration strategy tailored to flow-matching dynamics. Across challenging multi-object and cluttered manipulation benchmarks, SA-VLA enables stable RL fine-tuning and improves zero-shot spatial generalization, yielding more robust and transferable behaviors. Code and project page are available at https://xupan.top/Projects/savla.
InstantViR: Real-Time Video Inverse Problem Solver with Distilled Diffusion Prior
Nov 18, 2025Video inverse problems are fundamental to streaming, telepresence, and AR/VR, where high perceptual quality must coexist with tight latency constraints. Diffusion-based priors currently deliver state-of-the-art reconstructions, but existing approaches either adapt image diffusion models with ad hoc temporal regularizers - leading to temporal artifacts - or rely on native video diffusion models whose iterative posterior sampling is far too slow for real-time use. We introduce InstantViR, an amortized inference framework for ultra-fast video reconstruction powered by a pre-trained video diffusion prior. We distill a powerful bidirectional video diffusion model (teacher) into a causal autoregressive student that maps a degraded video directly to its restored version in a single forward pass, inheriting the teacher's strong temporal modeling while completely removing iterative test-time optimization. The distillation is prior-driven: it only requires the teacher diffusion model and known degradation operators, and does not rely on externally paired clean/noisy video data. To further boost throughput, we replace the video-diffusion backbone VAE with a high-efficiency LeanVAE via an innovative teacher-space regularized distillation scheme, enabling low-latency latent-space processing. Across streaming random inpainting, Gaussian deblurring and super-resolution, InstantViR matches or surpasses the reconstruction quality of diffusion-based baselines while running at over 35 FPS on NVIDIA A100 GPUs, achieving up to 100 times speedups over iterative video diffusion solvers. These results show that diffusion-based video reconstruction is compatible with real-time, interactive, editable, streaming scenarios, turning high-quality video restoration into a practical component of modern vision systems.
Multi-Channel Differential ASR for Robust Wearer Speech Recognition on Smart Glasses
Sep 17, 2025With the growing adoption of wearable devices such as smart glasses for AI assistants, wearer speech recognition (WSR) is becoming increasingly critical to next-generation human-computer interfaces. However, in real environments, interference from side-talk speech remains a significant challenge to WSR and may cause accumulated errors for downstream tasks such as natural language processing. In this work, we introduce a novel multi-channel differential automatic speech recognition (ASR) method for robust WSR on smart glasses. The proposed system takes differential inputs from different frontends that complement each other to improve the robustness of WSR, including a beamformer, microphone selection, and a lightweight side-talk detection model. Evaluations on both simulated and real datasets demonstrate that the proposed system outperforms the traditional approach, achieving up to an 18.0% relative reduction in word error rate.
Generating Query-Relevant Document Summaries via Reinforcement Learning
Aug 11, 2025E-commerce search engines often rely solely on product titles as input for ranking models with latency constraints. However, this approach can result in suboptimal relevance predictions, as product titles often lack sufficient detail to capture query intent. While product descriptions provide richer information, their verbosity and length make them unsuitable for real-time ranking, particularly for computationally expensive architectures like cross-encoder ranking models. To address this challenge, we propose ReLSum, a novel reinforcement learning framework designed to generate concise, query-relevant summaries of product descriptions optimized for search relevance. ReLSum leverages relevance scores as rewards to align the objectives of summarization and ranking, effectively overcoming limitations of prior methods, such as misaligned learning targets. The framework employs a trainable large language model (LLM) to produce summaries, which are then used as input for a cross-encoder ranking model. Experimental results demonstrate significant improvements in offline metrics, including recall and NDCG, as well as online user engagement metrics. ReLSum provides a scalable and efficient solution for enhancing search relevance in large-scale e-commerce systems.
Bridging Video Quality Scoring and Justification via Large Multimodal Models
Jun 26, 2025Classical video quality assessment (VQA) methods generate a numerical score to judge a video's perceived visual fidelity and clarity. Yet, a score fails to describe the video's complex quality dimensions, restricting its applicability. Benefiting from the linguistic output, adapting video large multimodal models (LMMs) to VQA via instruction tuning has the potential to address this issue. The core of the approach lies in the video quality-centric instruction data. Previous explorations mainly focus on the image domain, and their data generation processes heavily rely on human quality annotations and proprietary systems, limiting data scalability and effectiveness. To address these challenges, we propose the Score-based Instruction Generation (SIG) pipeline. Specifically, SIG first scores multiple quality dimensions of an unlabeled video and maps scores to text-defined levels. It then explicitly incorporates a hierarchical Chain-of-Thought (CoT) to model the correlation between specific dimensions and overall quality, mimicking the human visual system's reasoning process. The automated pipeline eliminates the reliance on expert-written quality descriptions and proprietary systems, ensuring data scalability and generation efficiency. To this end, the resulting Score2Instruct (S2I) dataset contains over 320K diverse instruction-response pairs, laying the basis for instruction tuning. Moreover, to advance video LMMs' quality scoring and justification abilities simultaneously, we devise a progressive tuning strategy to fully unleash the power of S2I. Built upon SIG, we further curate a benchmark termed S2I-Bench with 400 open-ended questions to better evaluate the quality justification capacity of video LMMs. Experimental results on the S2I-Bench and existing benchmarks indicate that our method consistently improves quality scoring and justification capabilities across multiple video LMMs.
Thinking in Directivity: Speech Large Language Model for Multi-Talker Directional Speech Recognition
Jun 17, 2025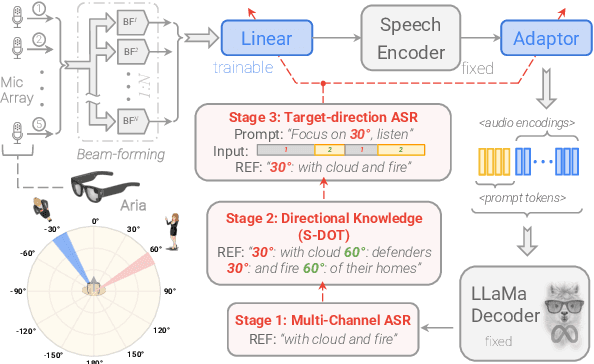
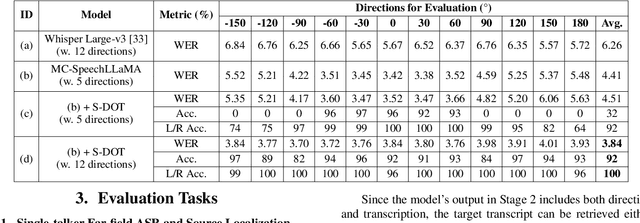
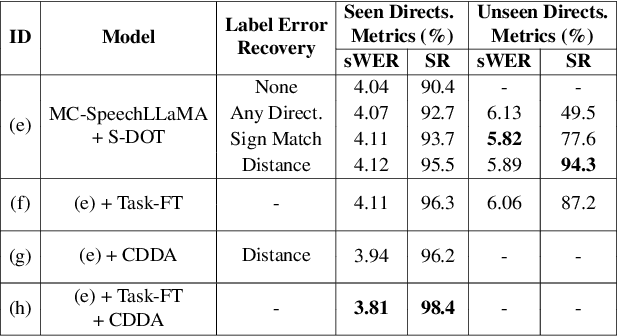
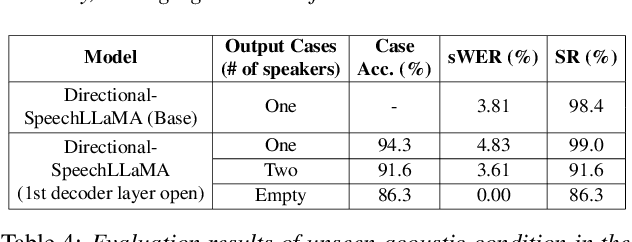
Recent studies have demonstrated that prompting large language models (LLM) with audio encodings enables effective speech recognition capabilities. However, the ability of Speech LLMs to comprehend and process multi-channel audio with spatial cues remains a relatively uninvestigated area of research. In this work, we present directional-SpeechLlama, a novel approach that leverages the microphone array of smart glasses to achieve directional speech recognition, source localization, and bystander cross-talk suppression. To enhance the model's ability to understand directivity, we propose two key techniques: serialized directional output training (S-DOT) and contrastive direction data augmentation (CDDA). Experimental results show that our proposed directional-SpeechLlama effectively captures the relationship between textual cues and spatial audio, yielding strong performance in both speech recognition and source localization tasks.
Accelerating Diffusion-based Super-Resolution with Dynamic Time-Spatial Sampling
May 17, 2025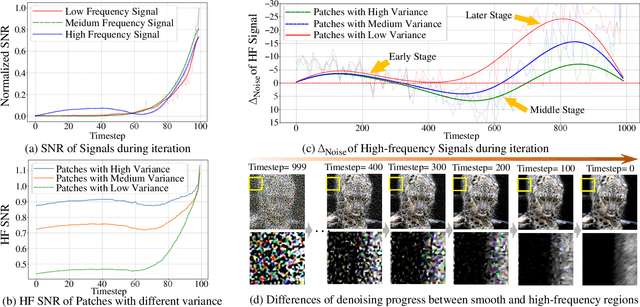
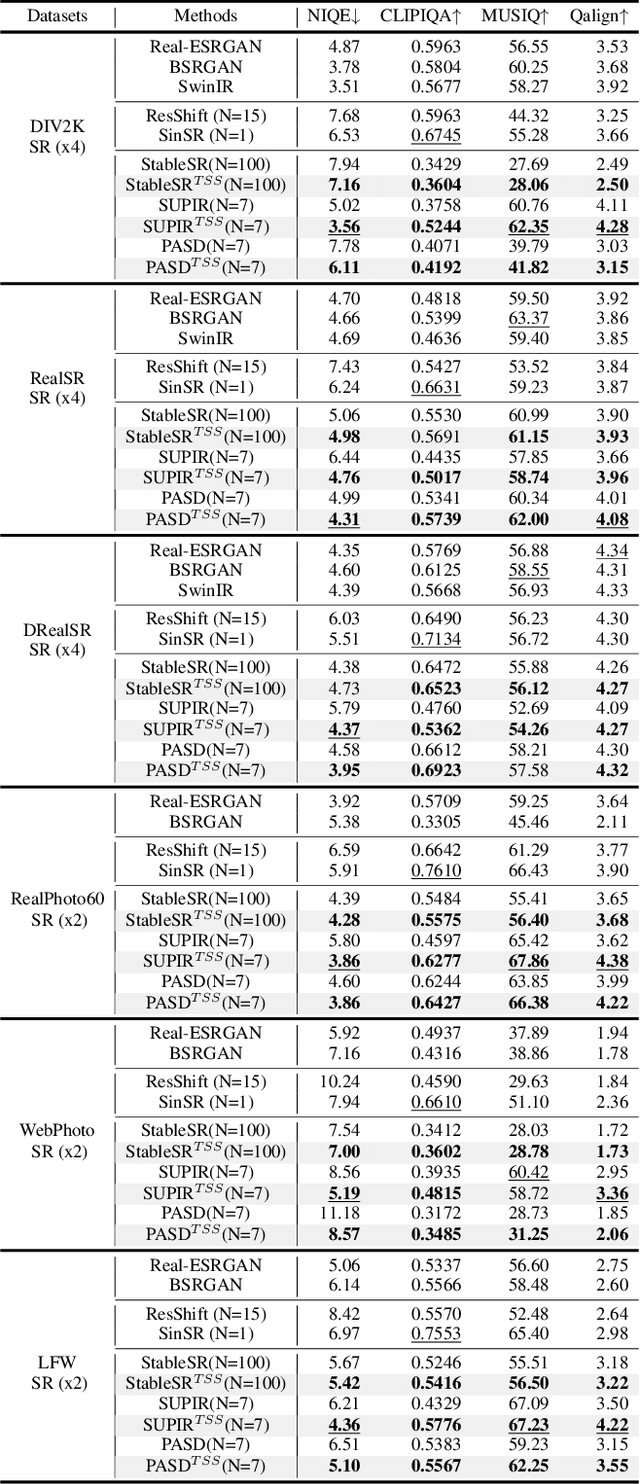
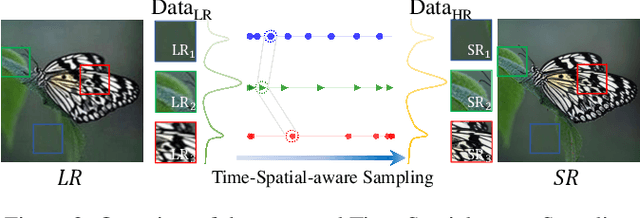
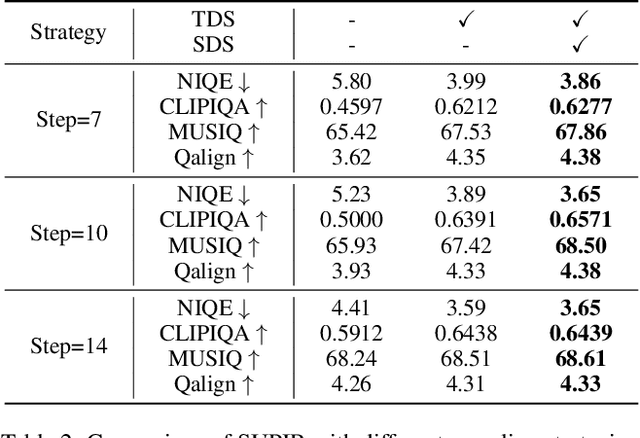
Diffusion models have gained attention for their success in modeling complex distributions, achieving impressive perceptual quality in SR tasks. However, existing diffusion-based SR methods often suffer from high computational costs, requiring numerous iterative steps for training and inference. Existing acceleration techniques, such as distillation and solver optimization, are generally task-agnostic and do not fully leverage the specific characteristics of low-level tasks like super-resolution (SR). In this study, we analyze the frequency- and spatial-domain properties of diffusion-based SR methods, revealing key insights into the temporal and spatial dependencies of high-frequency signal recovery. Specifically, high-frequency details benefit from concentrated optimization during early and late diffusion iterations, while spatially textured regions demand adaptive denoising strategies. Building on these observations, we propose the Time-Spatial-aware Sampling strategy (TSS) for the acceleration of Diffusion SR without any extra training cost. TSS combines Time Dynamic Sampling (TDS), which allocates more iterations to refining textures, and Spatial Dynamic Sampling (SDS), which dynamically adjusts strategies based on image content. Extensive evaluations across multiple benchmarks demonstrate that TSS achieves state-of-the-art (SOTA) performance with significantly fewer iterations, improving MUSIQ scores by 0.2 - 3.0 and outperforming the current acceleration methods with only half the number of steps.
NTIRE 2025 Challenge on Short-form UGC Video Quality Assessment and Enhancement: KwaiSR Dataset and Study
Apr 21, 2025In this work, we build the first benchmark dataset for short-form UGC Image Super-resolution in the wild, termed KwaiSR, intending to advance the research on developing image super-resolution algorithms for short-form UGC platforms. This dataset is collected from the Kwai Platform, which is composed of two parts, i.e., synthetic and wild parts. Among them, the synthetic dataset, including 1,900 image pairs, is produced by simulating the degradation following the distribution of real-world low-quality short-form UGC images, aiming to provide the ground truth for training and objective comparison in the validation/testing. The wild dataset contains low-quality images collected directly from the Kwai Platform, which are filtered using the quality assessment method KVQ from the Kwai Platform. As a result, the KwaiSR dataset contains 1800 synthetic image pairs and 1900 wild images, which are divided into training, validation, and testing parts with a ratio of 8:1:1. Based on the KwaiSR dataset, we organize the NTIRE 2025 challenge on a second short-form UGC Video quality assessment and enhancement, which attracts lots of researchers to develop the algorithm for it. The results of this competition have revealed that our KwaiSR dataset is pretty challenging for existing Image SR methods, which is expected to lead to a new direction in the image super-resolution field. The dataset can be found from https://lixinustc.github.io/NTIRE2025-KVQE-KwaSR-KVQ.github.io/.
KVQ: Boosting Video Quality Assessment via Saliency-guided Local Perception
Mar 13, 2025Video Quality Assessment (VQA), which intends to predict the perceptual quality of videos, has attracted increasing attention. Due to factors like motion blur or specific distortions, the quality of different regions in a video varies. Recognizing the region-wise local quality within a video is beneficial for assessing global quality and can guide us in adopting fine-grained enhancement or transcoding strategies. Due to the heavy cost of annotating region-wise quality, the lack of ground truth constraints from relevant datasets further complicates the utilization of local perception. Inspired by the Human Visual System (HVS) that links global quality to the local texture of different regions and their visual saliency, we propose a Kaleidoscope Video Quality Assessment (KVQ) framework, which aims to effectively assess both saliency and local texture, thereby facilitating the assessment of global quality. Our framework extracts visual saliency and allocates attention using Fusion-Window Attention (FWA) while incorporating a Local Perception Constraint (LPC) to mitigate the reliance of regional texture perception on neighboring areas. KVQ obtains significant improvements across multiple scenarios on five VQA benchmarks compared to SOTA methods. Furthermore, to assess local perception, we establish a new Local Perception Visual Quality (LPVQ) dataset with region-wise annotations. Experimental results demonstrate the capability of KVQ in perceiving local distortions. KVQ models and the LPVQ dataset will be available at https://github.com/qyp2000/KVQ.
Visual Autoregressive Modeling for Image Super-Resolution
Jan 31, 2025



Image Super-Resolution (ISR) has seen significant progress with the introduction of remarkable generative models. However, challenges such as the trade-off issues between fidelity and realism, as well as computational complexity, have also posed limitations on their application. Building upon the tremendous success of autoregressive models in the language domain, we propose \textbf{VARSR}, a novel visual autoregressive modeling for ISR framework with the form of next-scale prediction. To effectively integrate and preserve semantic information in low-resolution images, we propose using prefix tokens to incorporate the condition. Scale-aligned Rotary Positional Encodings are introduced to capture spatial structures and the diffusion refiner is utilized for modeling quantization residual loss to achieve pixel-level fidelity. Image-based Classifier-free Guidance is proposed to guide the generation of more realistic images. Furthermore, we collect large-scale data and design a training process to obtain robust generative priors. Quantitative and qualitative results show that VARSR is capable of generating high-fidelity and high-realism images with more efficiency than diffusion-based methods. Our codes will be released at https://github.com/qyp2000/VARSR.