 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Ambiguity in Imitation Learning through Product of Experts based Negative Feedback
Mar 27, 2026Programming robots to perform complex tasks is often difficult and time consuming, requiring expert knowledge and skills in robot software and sometimes hardware. Imitation learning is a method for training robots to perform tasks by leveraging human expertise through demonstrations. Typically, the assumption is that those demonstrations are performed by a single, highly competent expert. However, in many real-world applications that use user demonstrations for tasks or incorporate both user data and pretrained data, such as home robotics including assistive robots, this is unlikely to be the case. This paper presents research towards a system which can leverage suboptimal demonstrations to solve ambiguous tasks; and particularly learn from its own failures. This is a negative-feedback system which achieves significant improvement over purely positive imitation learning for ambiguous tasks, achieving a 90% improvement in success rate against a system that does not utilise negative feedback, compared to a 50% improvement in success rate when utilised on a real robot, as well as demonstrating higher efficacy, memory efficiency and time efficiency than a comparable negative feedback scheme. The novel scheme presented in this paper is validated through simulated and real-robot experiments.
Pioneering Perceptual Video Fluency Assessment: A Novel Task with Benchmark Dataset and Baseline
Mar 27, 2026Accurately estimating humans' subjective feedback on video fluency, e.g., motion consistency and frame continuity, is crucial for various applications like streaming and gaming. Yet, it has long been overlooked, as prior arts have focused on solving it in the video quality assessment (VQA) task, merely as a sub-dimension of overall quality. In this work, we conduct pilot experiments and reveal that current VQA predictions largely underrepresent fluency, thereby limiting their applicability. To this end, we pioneer Video Fluency Assessment (VFA) as a standalone perceptual task focused on the temporal dimension. To advance VFA research, 1) we construct a fluency-oriented dataset, FluVid, comprising 4,606 in-the-wild videos with balanced fluency distribution, featuring the first-ever scoring criteria and human study for VFA. 2) We develop a large-scale benchmark of 23 methods, the most comprehensive one thus far on FluVid, gathering insights for VFA-tailored model designs. 3) We propose a baseline model called FluNet, which deploys temporal permuted self-attention (T-PSA) to enrich input fluency information and enhance long-range inter-frame interactions. Our work not only achieves state-of-the-art performance but, more importantly, offers the community a roadmap to explore solutions for VFA.
TARMAC: A Taxonomy for Robot Manipulation in Chemistry
Oct 22, 2025Chemistry laboratory automation aims to increase throughput, reproducibility, and safety, yet many existing systems still depend on frequent human intervention. Advances in robotics have reduced this dependency, but without a structured representation of the required skills, autonomy remains limited to bespoke, task-specific solutions with little capacity to transfer beyond their initial design. Current experiment abstractions typically describe protocol-level steps without specifying the robotic actions needed to execute them. This highlights the lack of a systematic account of the manipulation skills required for robots in chemistry laboratories. To address this gap, we introduce TARMAC - a Taxonomy for Robot Manipulation in Chemistry - a domain-specific framework that defines and organizes the core manipulations needed in laboratory practice. Based on annotated teaching-lab demonstrations and supported by experimental validation, TARMAC categorizes actions according to their functional role and physical execution requirements. Beyond serving as a descriptive vocabulary, TARMAC can be instantiated as robot-executable primitives and composed into higher-level macros, enabling skill reuse and supporting scalable integration into long-horizon workflows. These contributions provide a structured foundation for more flexible and autonomous laboratory automation. More information is available at https://tarmac-paper.github.io/
Bimanual Robot-Assisted Dressing: A Spherical Coordinate-Based Strategy for Tight-Fitting Garments
Aug 17, 2025Robot-assisted dressing is a popular but challenging topic in the field of robotic manipulation, offering significant potential to improve the quality of life for individuals with mobility limitations. Currently, the majority of research on robot-assisted dressing focuses on how to put on loose-fitting clothing, with little attention paid to tight garments. For the former, since the armscye is larger, a single robotic arm can usually complete the dressing task successfully. However, for the latter, dressing with a single robotic arm often fails due to the narrower armscye and the property of diminishing rigidity in the armscye, which eventually causes the armscye to get stuck. This paper proposes a bimanual dressing strategy suitable for dressing tight-fitting clothing. To facilitate the encoding of dressing trajectories that adapt to different human arm postures, a spherical coordinate system for dressing is established. We uses the azimuthal angle of the spherical coordinate system as a task-relevant feature for bimanual manipulation. Based on this new coordinate, we employ Gaussian Mixture Model (GMM) and Gaussian Mixture Regression (GMR) for imitation learning of bimanual dressing trajectories, generating dressing strategies that adapt to different human arm postures. The effectiveness of the proposed method is validated through various experiments.
Bridging Video Quality Scoring and Justification via Large Multimodal Models
Jun 26, 2025Classical video quality assessment (VQA) methods generate a numerical score to judge a video's perceived visual fidelity and clarity. Yet, a score fails to describe the video's complex quality dimensions, restricting its applicability. Benefiting from the linguistic output, adapting video large multimodal models (LMMs) to VQA via instruction tuning has the potential to address this issue. The core of the approach lies in the video quality-centric instruction data. Previous explorations mainly focus on the image domain, and their data generation processes heavily rely on human quality annotations and proprietary systems, limiting data scalability and effectiveness. To address these challenges, we propose the Score-based Instruction Generation (SIG) pipeline. Specifically, SIG first scores multiple quality dimensions of an unlabeled video and maps scores to text-defined levels. It then explicitly incorporates a hierarchical Chain-of-Thought (CoT) to model the correlation between specific dimensions and overall quality, mimicking the human visual system's reasoning process. The automated pipeline eliminates the reliance on expert-written quality descriptions and proprietary systems, ensuring data scalability and generation efficiency. To this end, the resulting Score2Instruct (S2I) dataset contains over 320K diverse instruction-response pairs, laying the basis for instruction tuning. Moreover, to advance video LMMs' quality scoring and justification abilities simultaneously, we devise a progressive tuning strategy to fully unleash the power of S2I. Built upon SIG, we further curate a benchmark termed S2I-Bench with 400 open-ended questions to better evaluate the quality justification capacity of video LMMs. Experimental results on the S2I-Bench and existing benchmarks indicate that our method consistently improves quality scoring and justification capabilities across multiple video LMMs.
QPT V2: Masked Image Modeling Advances Visual Scoring
Jul 23, 2024



Quality assessment and aesthetics assessment aim to evaluate the perceived quality and aesthetics of visual content. Current learning-based methods suffer greatly from the scarcity of labeled data and usually perform sub-optimally in terms of generalization. Although masked image modeling (MIM) has achieved noteworthy advancements across various high-level tasks (e.g., classification, detection etc.). In this work, we take on a novel perspective to investigate its capabilities in terms of quality- and aesthetics-awareness. To this end, we propose Quality- and aesthetics-aware pretraining (QPT V2), the first pretraining framework based on MIM that offers a unified solution to quality and aesthetics assessment. To perceive the high-level semantics and fine-grained details, pretraining data is curated. To comprehensively encompass quality- and aesthetics-related factors, degradation is introduced. To capture multi-scale quality and aesthetic information, model structure is modified. Extensive experimental results on 11 downstream benchmarks clearly show the superior performance of QPT V2 in comparison with current state-of-the-art approaches and other pretraining paradigms. Code and models will be released at \url{https://github.com/KeiChiTse/QPT-V2}.
LLM-BT: Performing Robotic Adaptive Tasks based on Large Language Models and Behavior Trees
Apr 08, 2024



Large Language Models (LLMs) have been widely utilized to perform complex robotic tasks. However, handling external disturbances during tasks is still an open challenge. This paper proposes a novel method to achieve robotic adaptive tasks based on LLMs and Behavior Trees (BTs). It utilizes ChatGPT to reason the descriptive steps of tasks. In order to enable ChatGPT to understand the environment, semantic maps are constructed by an object recognition algorithm. Then, we design a Parser module based on Bidirectional Encoder Representations from Transformers (BERT) to parse these steps into initial BTs. Subsequently, a BTs Update algorithm is proposed to expand the initial BTs dynamically to control robots to perform adaptive tasks. Different from other LLM-based methods for complex robotic tasks, our method outputs variable BTs that can add and execute new actions according to environmental changes, which is robust to external disturbances. Our method is validated with simulation in different practical scenarios.
DexDLO: Learning Goal-Conditioned Dexterous Policy for Dynamic Manipulation of Deformable Linear Objects
Dec 23, 2023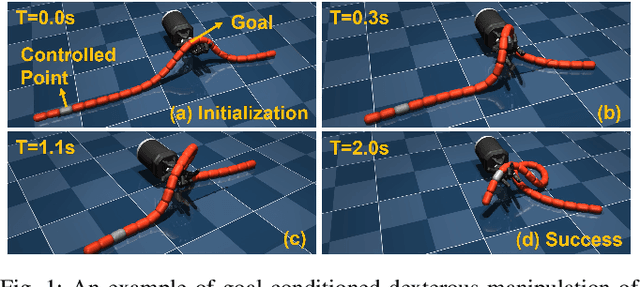



Deformable linear object (DLO) manipulation is needed in many fields. Previous research on deformable linear object (DLO) manipulation has primarily involved parallel jaw gripper manipulation with fixed grasping positions. However, the potential for dexterous manipulation of DLOs using an anthropomorphic hand is under-explored. We present DexDLO, a model-free framework that learns dexterous dynamic manipulation policies for deformable linear objects with a fixed-base dexterous hand in an end-to-end way. By abstracting several common DLO manipulation tasks into goal-conditioned tasks, our DexDLO can perform these tasks, such as DLO grabbing, DLO pulling, DLO end-tip position controlling, etc. Using the Mujoco physics simulator, we demonstrate that our framework can efficiently and effectively learn five different DLO manipulation tasks with the same framework parameters. We further provide a thorough analysis of learned policies, reward functions, and reduced observations for a comprehensive understanding of the framework.
Design and trajectory tracking control of CuRobot: A Cubic Reversible Robot
Nov 28, 2023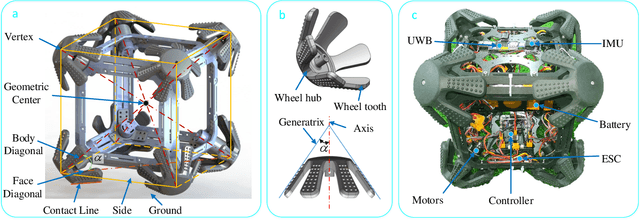
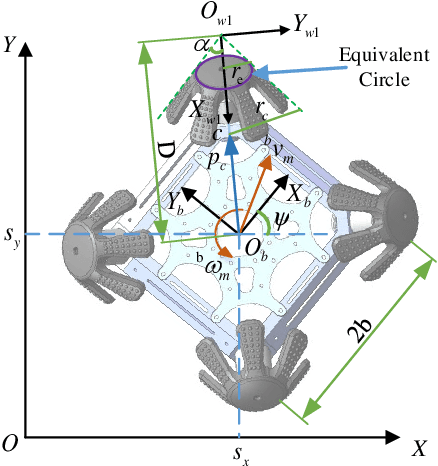
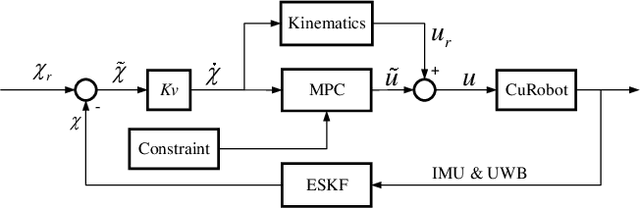
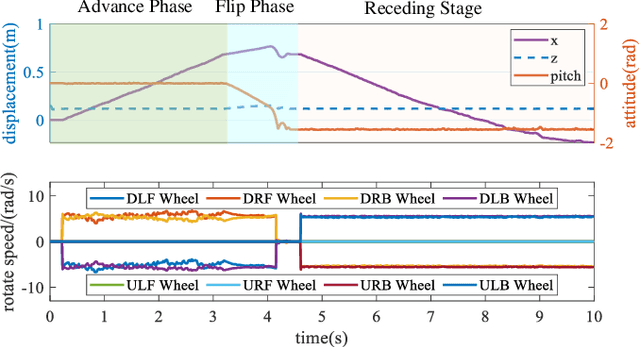
In field environments, numerous robots necessitate manual intervention for restoration of functionality post a turnover, resulting in diminished operational efficiency. This study presents an innovative design solution for a reversible omnidirectional mobile robot denoted as CuRobot, featuring a cube structure, thereby facilitating uninterrupted omnidirectional movement even in the event of flipping. The incorporation of eight conical wheels at the cube vertices ensures consistent omnidirectional motion no matter which face of the cube contacts the ground. Additionally, a kinematic model is formulated for CuRobot, accompanied by the development of a trajectory tracking controller utilizing model predictive control. Through simulation experiments, the correlation between trajectory tracking accuracy and the robot's motion direction is examined. Furthermore, the robot's proficiency in omnidirectional mobility and sustained movement post-flipping is substantiated via both simulation and prototype experiments. This design reduces the inefficiencies associated with manual intervention, thereby increasing the operational robustness of robots in field environments.
Learning to bag with a simulation-free reinforcement learning framework for robots
Oct 22, 2023Bagging is an essential skill that humans perform in their daily activities. However, deformable objects, such as bags, are complex for robots to manipulate. This paper presents an efficient learning-based framework that enables robots to learn bagging. The novelty of this framework is its ability to perform bagging without relying on simulations. The learning process is accomplished through a reinforcement learning algorithm introduced in this work, designed to find the best grasping points of the bag based on a set of compact state representations. The framework utilizes a set of primitive actions and represents the task in five states. In our experiments, the framework reaches a 60 % and 80 % of success rate after around three hours of training in the real world when starting the bagging task from folded and unfolded, respectively. Finally, we test the trained model with two more bags of different sizes to evaluate its generalizability.