 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Actor-Critic Approach to Boosting Text-to-SQL Large Language Model
Oct 28, 2024Text-To-SQL (T2S) conversion based on large language models (LLMs) has found a wide range of applications, by leveraging the capabilities of LLMs in interpreting the query intent expressed in natural language. Existing research focuses on suitable representations for data schema and/or questions, task-specific instructions and representative examples, and complicated inference pipelines. All these methods are empirical and task specific, without a theoretical bound on performance. In this paper, we propose a simple, general, and performance guaranteed T2S enhancement approach called Actor-Critic (AC). Specifically, we design two roles using the same LLM: an Actor to produce SQL queries and a Critic to evaluate the produced SQL. If the Critic believes the produced SQL is wrong, it notifies the Actor to reproduce the SQL and perform evaluation again. By this simple iterative process, expected performance can be derived in theory. We conducted extensive experiments on the Spider and related datasets with eleven LLMs, and demonstrated that the Actor-Critic method consistently improves the performance of T2S, thus serving as a general enhancement approach for T2S conversion.
How phonemes contribute to deep speaker models?
Feb 05, 2024Which phonemes convey more speaker traits is a long-standing question, and various perception experiments were conducted with human subjects. For speaker recognition, studies were conducted with the conventional statistical models and the drawn conclusions are more or less consistent with the perception results. However, which phonemes are more important with modern deep neural models is still unexplored, due to the opaqueness of the decision process. This paper conducts a novel study for the attribution of phonemes with two types of deep speaker models that are based on TDNN and CNN respectively, from the perspective of model explanation. Specifically, we conducted the study by two post-explanation methods: LayerCAM and Time Align Occlusion (TAO). Experimental results showed that: (1) At the population level, vowels are more important than consonants, confirming the human perception studies. However, fricatives are among the most unimportant phonemes, which contrasts with previous studies. (2) At the speaker level, a large between-speaker variation is observed regarding phoneme importance, indicating that whether a phoneme is important or not is largely speaker-dependent.
Visualizing data augmentation in deep speaker recognition
May 25, 2023Visualization is of great value in understanding the internal mechanisms of neural networks. Previous work found that LayerCAM is a reliable visualization tool for deep speaker models. In this paper, we use LayerCAM to analyze the widely-adopted data augmentation (DA) approach, to understand how it leads to model robustness. We conduct experiments on the VoxCeleb1 dataset for speaker identification, which shows that both vanilla and activation-based (Act) DA approaches enhance robustness against interference, with Act DA being consistently superior. Visualization with LayerCAM suggests DA helps models learn to delete temporal-frequency (TF) bins that are corrupted by interference. The `learn to delete' behavior explained why DA models are more robust than clean models, and why the Act DA is superior over the vanilla DA when the interference is nontarget speech. However, LayerCAM still cannot clearly explain the superiority of Act DA in other situations, suggesting further research.
DASTSiam: Spatio-Temporal Fusion and Discriminative Augmentation for Improved Siamese Tracking
Jan 22, 2023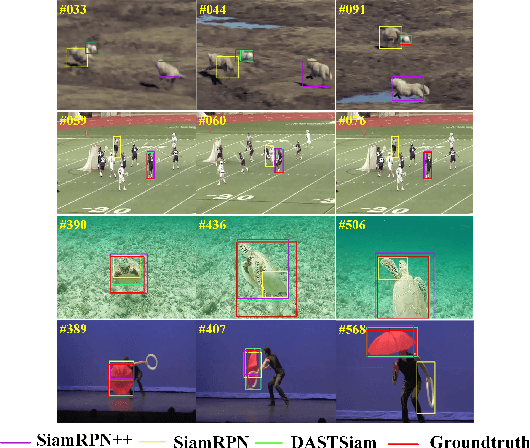

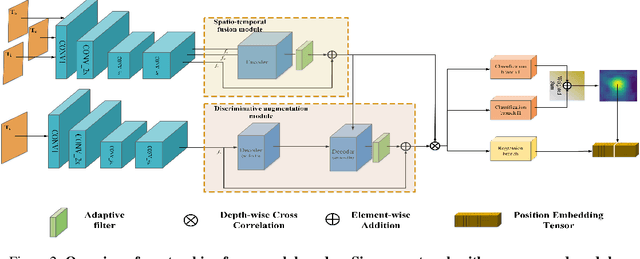
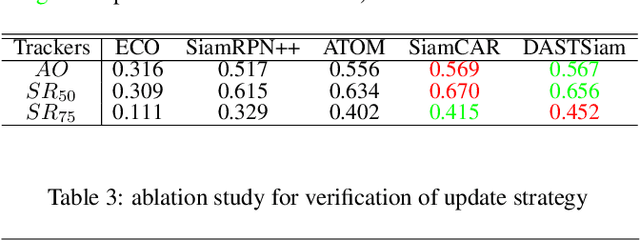
Tracking tasks based on deep neural networks have greatly improved with the emergence of Siamese trackers. However, the appearance of targets often changes during tracking, which can reduce the robustness of the tracker when facing challenges such as aspect ratio change, occlusion, and scale variation. In addition, cluttered backgrounds can lead to multiple high response points in the response map, leading to incorrect target positioning. In this paper, we introduce two transformer-based modules to improve Siamese tracking called DASTSiam: the spatio-temporal (ST) fusion module and the Discriminative Augmentation (DA) module. The ST module uses cross-attention based accumulation of historical cues to improve robustness against object appearance changes, while the DA module associates semantic information between the template and search region to improve target discrimination. Moreover, Modifying the label assignment of anchors also improves the reliability of the object location. Our modules can be used with all Siamese trackers and show improved performance on several public datasets through comparative and ablation experiments.
Reliable Visualization for Deep Speaker Recognition
Apr 12, 2022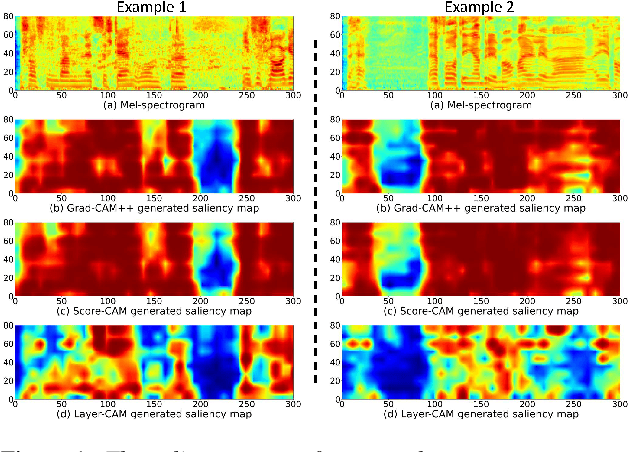
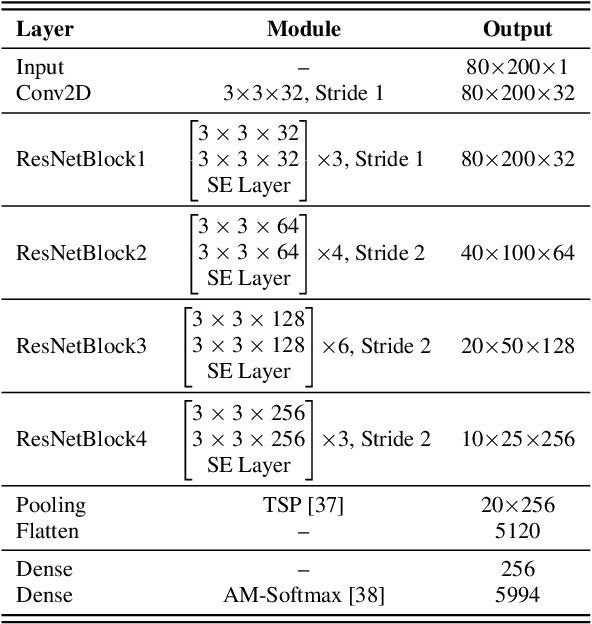
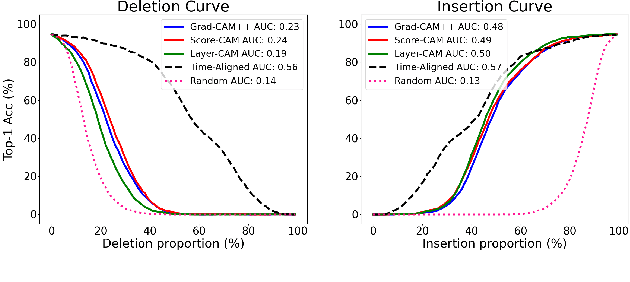
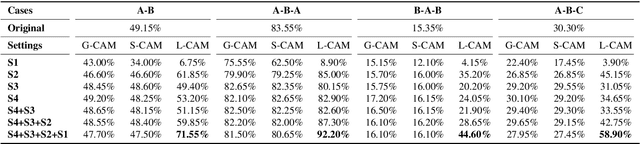
In spite of the impressive success of convolutional neural networks (CNNs) in speaker recognition, our understanding to CNNs' internal functions is still limited. A major obstacle is that some popular visualization tools are difficult to apply, for example those producing saliency maps. The reason is that speaker information does not show clear spatial patterns in the temporal-frequency space, which makes it hard to interpret the visualization results, and hence hard to confirm the reliability of a visualization tool. In this paper, we conduct an extensive analysis on three popular visualization methods based on CAM: Grad-CAM, Score-CAM and Layer-CAM, to investigate their reliability for speaker recognition tasks. Experiments conducted on a state-of-the-art ResNet34SE model show that the Layer-CAM algorithm can produce reliable visualization, and thus can be used as a promising tool to explain CNN-based speaker models. The source code and examples are available in our project page: http://project.cslt.org/.
Memory-augmented Chinese-Uyghur Neural Machine Translation
Jun 27, 2017

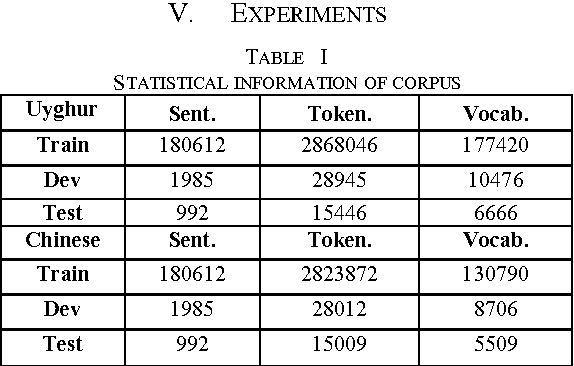

Neural machine translation (NMT) has achieved notable performance recently. However, this approach has not been widely applied to the translation task between Chinese and Uyghur, partly due to the limited parallel data resource and the large proportion of rare words caused by the agglutinative nature of Uyghur. In this paper, we collect ~200,000 sentence pairs and show that with this middle-scale database, an attention-based NMT can perform very well on Chinese-Uyghur/Uyghur-Chinese translation. To tackle rare words, we propose a novel memory structure to assist the NMT inference. Our experiments demonstrated that the memory-augmented NMT (M-NMT) outperforms both the vanilla NMT and the phrase-based statistical machine translation (SMT). Interestingly, the memory structure provides an elegant way for dealing with words that are out of vocabulary.