 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-augmented Chinese-Uyghur Neural Machine Translation
Jun 27, 2017

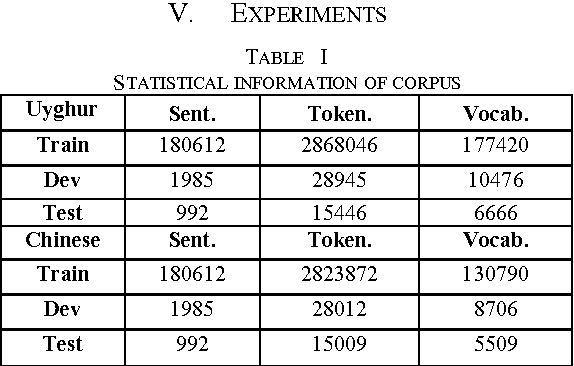

Neural machine translation (NMT) has achieved notable performance recently. However, this approach has not been widely applied to the translation task between Chinese and Uyghur, partly due to the limited parallel data resource and the large proportion of rare words caused by the agglutinative nature of Uyghur. In this paper, we collect ~200,000 sentence pairs and show that with this middle-scale database, an attention-based NMT can perform very well on Chinese-Uyghur/Uyghur-Chinese translation. To tackle rare words, we propose a novel memory structure to assist the NMT inference. Our experiments demonstrated that the memory-augmented NMT (M-NMT) outperforms both the vanilla NMT and the phrase-based statistical machine translation (SMT). Interestingly, the memory structure provides an elegant way for dealing with words that are out of vocabulary.