 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling and Causalizing CoT: A Causal Pespective
Feb 25, 2025Although Chain-of-Thought (CoT) has achieved remarkable success in enhancing the reasoning ability of large language models (LLMs), the mechanism of CoT remains a ``black box''. Even if the correct answers can frequently be obtained, existing CoTs struggle to make the reasoning understandable to human. In this paper, we unveil and causalize CoT from a causal perspective to ensure both correctness and understandability of all reasoning steps (to the best of our knowledge, the first such). We model causality of CoT via structural causal models (SCM) to unveil the reasoning mechanism of CoT. To measure the causality of CoT, we define the CoT Average Causal Effect (CACE) to test the causal relations between steps. For those steps without causality (wrong or unintelligible steps), we design a role-playing causal query algorithm to causalize these steps, resulting a causalized CoT with all steps correct and understandable. Experimental results on both open-source and closed-source LLMs demonstrate that the causal errors commonly in steps are effectively corrected and the reasoning ability of LLMs is significantly improved.
Testing for Causal Fairness
Feb 18, 2025Causality is widely used in fairness analysis to prevent discrimination on sensitive attributes, such as genders in career recruitment and races in crime prediction. However, the current data-based Potential Outcomes Framework (POF) often leads to untrustworthy fairness analysis results when handling high-dimensional data. To address this, we introduce a distribution-based POF that transform fairness analysis into Distributional Closeness Testing (DCT) by intervening on sensitive attributes. We define counterfactual closeness fairness as the null hypothesis of DCT, where a sensitive attribute is considered fair if its factual and counterfactual potential outcome distributions are sufficiently close. We introduce the Norm-Adaptive Maximum Mean Discrepancy Treatment Effect (N-TE) as a statistic for measuring distributional closeness and apply DCT using the empirical estimator of NTE, referred to Counterfactual Fairness-CLOseness Testing ($\textrm{CF-CLOT}$). To ensure the trustworthiness of testing results, we establish the testing consistency of N-TE through rigorous theoretical analysis. $\textrm{CF-CLOT}$ demonstrates sensitivity in fairness analysis through the flexibility of the closeness parameter $\epsilon$. Unfair sensitive attributes have been successfully tested by $\textrm{CF-CLOT}$ in extensive experiments across various real-world scenarios, which validate the consistency of the testing.
How phonemes contribute to deep speaker models?
Feb 05, 2024Which phonemes convey more speaker traits is a long-standing question, and various perception experiments were conducted with human subjects. For speaker recognition, studies were conducted with the conventional statistical models and the drawn conclusions are more or less consistent with the perception results. However, which phonemes are more important with modern deep neural models is still unexplored, due to the opaqueness of the decision process. This paper conducts a novel study for the attribution of phonemes with two types of deep speaker models that are based on TDNN and CNN respectively, from the perspective of model explanation. Specifically, we conducted the study by two post-explanation methods: LayerCAM and Time Align Occlusion (TAO). Experimental results showed that: (1) At the population level, vowels are more important than consonants, confirming the human perception studies. However, fricatives are among the most unimportant phonemes, which contrasts with previous studies. (2) At the speaker level, a large between-speaker variation is observed regarding phoneme importance, indicating that whether a phoneme is important or not is largely speaker-dependent.
Visualizing data augmentation in deep speaker recognition
May 25, 2023Visualization is of great value in understanding the internal mechanisms of neural networks. Previous work found that LayerCAM is a reliable visualization tool for deep speaker models. In this paper, we use LayerCAM to analyze the widely-adopted data augmentation (DA) approach, to understand how it leads to model robustness. We conduct experiments on the VoxCeleb1 dataset for speaker identification, which shows that both vanilla and activation-based (Act) DA approaches enhance robustness against interference, with Act DA being consistently superior. Visualization with LayerCAM suggests DA helps models learn to delete temporal-frequency (TF) bins that are corrupted by interference. The `learn to delete' behavior explained why DA models are more robust than clean models, and why the Act DA is superior over the vanilla DA when the interference is nontarget speech. However, LayerCAM still cannot clearly explain the superiority of Act DA in other situations, suggesting further research.
Reliable Visualization for Deep Speaker Recognition
Apr 12, 2022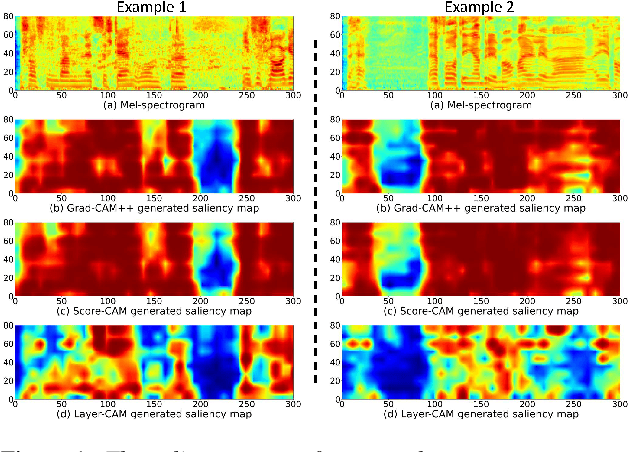
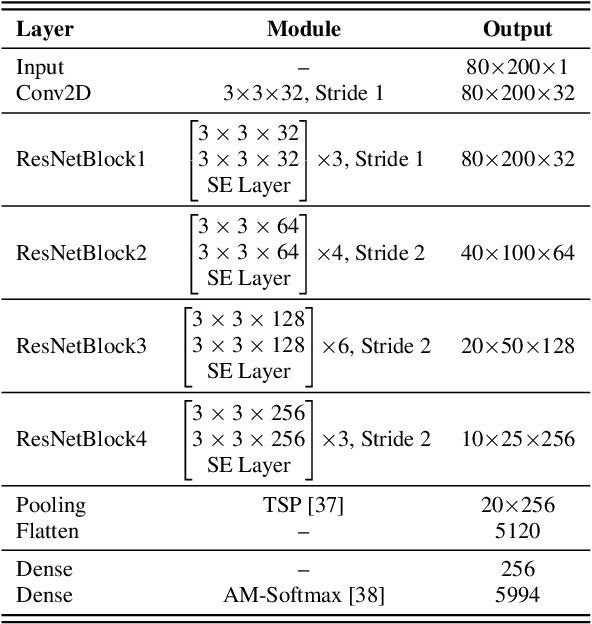
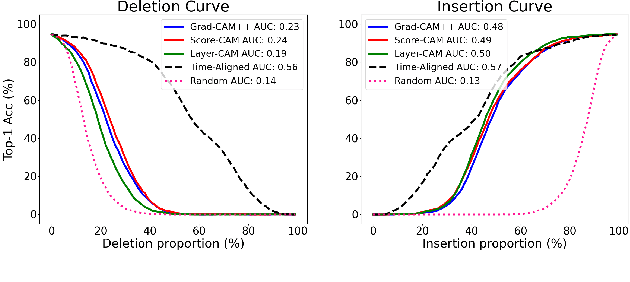
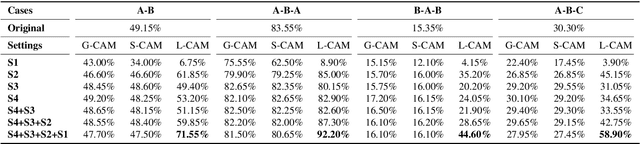
In spite of the impressive success of convolutional neural networks (CNNs) in speaker recognition, our understanding to CNNs' internal functions is still limited. A major obstacle is that some popular visualization tools are difficult to apply, for example those producing saliency maps. The reason is that speaker information does not show clear spatial patterns in the temporal-frequency space, which makes it hard to interpret the visualization results, and hence hard to confirm the reliability of a visualization tool. In this paper, we conduct an extensive analysis on three popular visualization methods based on CAM: Grad-CAM, Score-CAM and Layer-CAM, to investigate their reliability for speaker recognition tasks. Experiments conducted on a state-of-the-art ResNet34SE model show that the Layer-CAM algorithm can produce reliable visualization, and thus can be used as a promising tool to explain CNN-based speaker models. The source code and examples are available in our project page: http://project.cslt.org/.