 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting for Causal Fairness
Feb 18, 2025Causality is widely used in fairness analysis to prevent discrimination on sensitive attributes, such as genders in career recruitment and races in crime prediction. However, the current data-based Potential Outcomes Framework (POF) often leads to untrustworthy fairness analysis results when handling high-dimensional data. To address this, we introduce a distribution-based POF that transform fairness analysis into Distributional Closeness Testing (DCT) by intervening on sensitive attributes. We define counterfactual closeness fairness as the null hypothesis of DCT, where a sensitive attribute is considered fair if its factual and counterfactual potential outcome distributions are sufficiently close. We introduce the Norm-Adaptive Maximum Mean Discrepancy Treatment Effect (N-TE) as a statistic for measuring distributional closeness and apply DCT using the empirical estimator of NTE, referred to Counterfactual Fairness-CLOseness Testing ($\textrm{CF-CLOT}$). To ensure the trustworthiness of testing results, we establish the testing consistency of N-TE through rigorous theoretical analysis. $\textrm{CF-CLOT}$ demonstrates sensitivity in fairness analysis through the flexibility of the closeness parameter $\epsilon$. Unfair sensitive attributes have been successfully tested by $\textrm{CF-CLOT}$ in extensive experiments across various real-world scenarios, which validate the consistency of the testing.
SUPS: A Simulated Underground Parking Scenario Dataset for Autonomous Driving
Feb 25, 2023
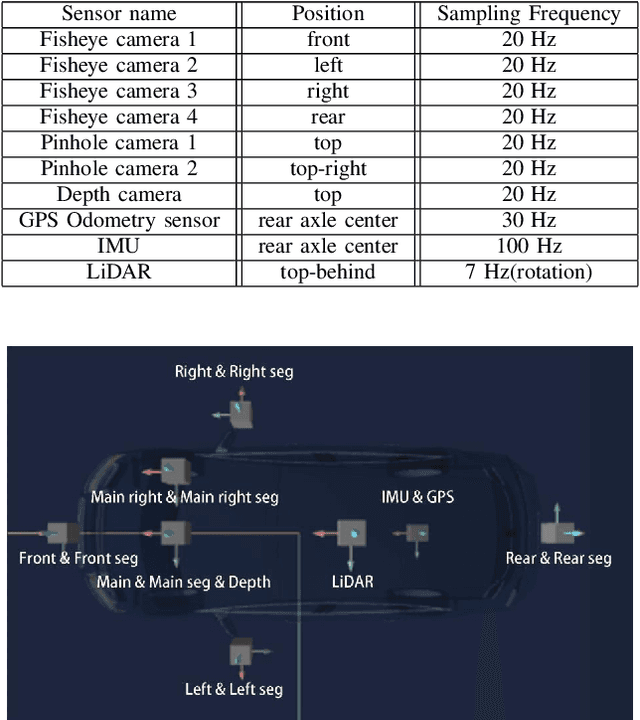

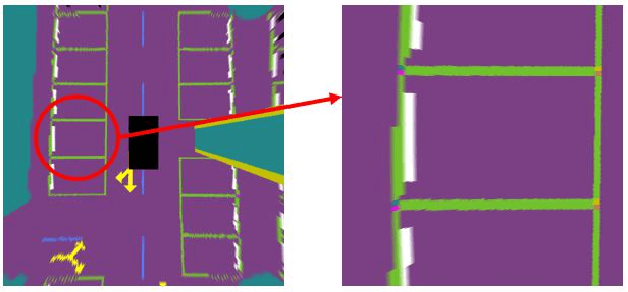
Automatic underground parking has attracted considerable attention as the scope of autonomous driving expands. The auto-vehicle is supposed to obtain the environmental information, track its location, and build a reliable map of the scenario. Mainstream solutions consist of well-trained neural networks and simultaneous localization and mapping (SLAM) methods, which need numerous carefully labeled images and multiple sensor estimations. However, there is a lack of underground parking scenario datasets with multiple sensors and well-labeled images that support both SLAM tasks and perception tasks, such as semantic segmentation and parking slot detection. In this paper, we present SUPS, a simulated dataset for underground automatic parking, which supports multiple tasks with multiple sensors and multiple semantic labels aligned with successive images according to timestamps. We intend to cover the defect of existing datasets with the variability of environments and the diversity and accessibility of sensors in the virtual scene. Specifically, the dataset records frames from four surrounding fisheye cameras, two forward pinhole cameras, a depth camera, and data from LiDAR, inertial measurement unit (IMU), GNSS. Pixel-level semantic labels are provided for objects, especially ground signs such as arrows, parking lines, lanes, and speed bumps. Perception, 3D reconstruction, depth estimation, and SLAM, and other relative tasks are supported by our dataset. We also evaluate the state-of-the-art SLAM algorithms and perception models on our dataset. Finally, we open source our virtual 3D scene built based on Unity Engine and release our dataset at https://github.com/jarvishou829/SUPS.
Causal Effect Estimation using Variational Information Bottleneck
Oct 26, 2021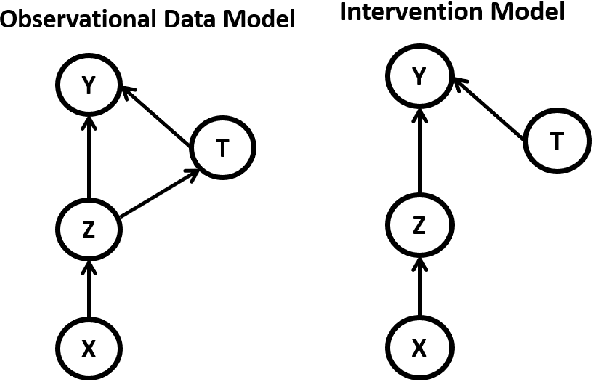
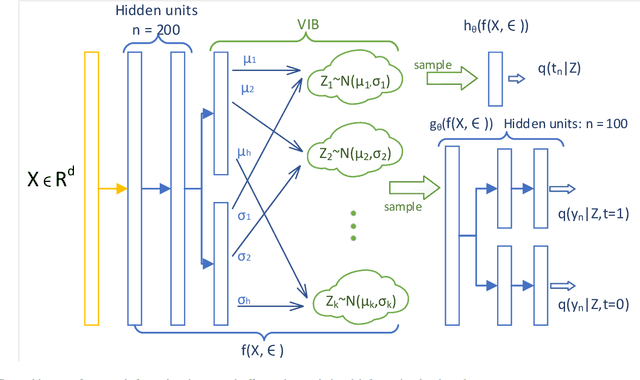
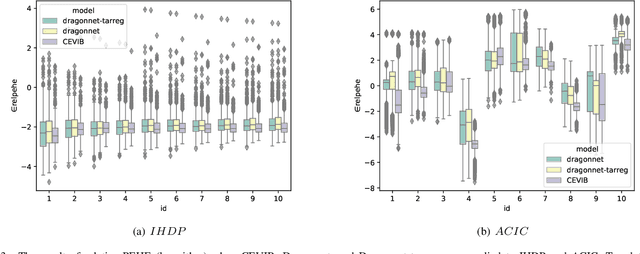
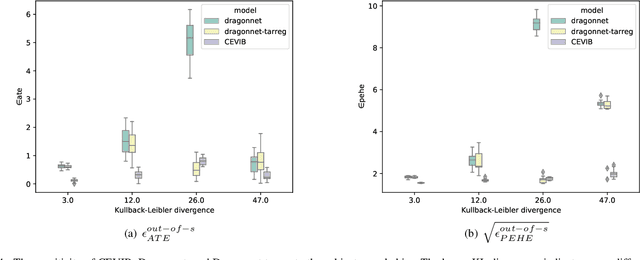
Causal inference is to estimate the causal effect in a causal relationship when intervention is applied. Precisely, in a causal model with binary interventions, i.e., control and treatment, the causal effect is simply the difference between the factual and counterfactual. The difficulty is that the counterfactual may never been obtained which has to be estimated and so the causal effect could only be an estimate. The key challenge for estimating the counterfactual is to identify confounders which effect both outcomes and treatments. A typical approach is to formulate causal inference as a supervised learning problem and so counterfactual could be predicted. Including linear regression and deep learning models, recent machine learning methods have been adapted to causal inference. In this paper, we propose a method to estimate Causal Effect by using Variational Information Bottleneck (CEVIB). The promising point is that VIB is able to naturally distill confounding variables from the data, which enables estimating causal effect by using observational data. We have compared CEVIB to other methods by applying them to three data sets showing that our approach achieved the best performance. We also experimentally showed the robustness of our method.