 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVSearch: Empowering Multimodal LLMs with Cognitive Visual Search for High-Resolution Image Perception
May 22, 2026High-resolution (HR) image perception presents a key bottleneck for multimodal large language models (MLLMs). While visual search offers a promising solution, existing methods struggle with the trade-off between coverage and efficiency. Visual expert-assisted search is efficient but prone to blind spots when proposals fail, whereas scan-based search guarantees coverage at the cost of computational redundancy and semantic fragmentation. To address this dilemma, we introduce CVSearch, a training-free adaptive framework that dynamically schedules search strategies via an Assess-then-Search workflow. Specifically, CVSearch first invokes expert-assisted search when global information is insufficient, and only triggers a novel semantic-aware scanning mechanism upon failure. Distinct from rigid grid partitioning, this efficient scanning paradigm incorporates Semantic Guided Adaptive Patching to decompose images into semantically consistent regions, effectively mitigating object fragmentation. Furthermore, we devise a Dynamic Bottom-Up Search strategy driven by a Visual Complexity prior to enable efficient and precise iterative exploration of local details. Extensive experiments on HR benchmarks demonstrate that CVSearch achieves state-of-the-art accuracy while substantially improving search efficiency. Code is released at https://github.com/liliupeng28/ICML26-CVSearch.
SegCompass: Exploring Interpretable Alignment with Sparse Autoencoders for Enhanced Reasoning Segmentation
May 21, 2026While large language models provide strong compositional reasoning, existing reasoning segmentation pipelines fail to transparently connect this reasoning to visual perception. Current methods, such as latent query alignment, are end-to-end yet opaque "black boxes". Conversely, textual localization readout is merely readable, not truly interpretable, often functioning as an unconstrained post-hoc step. To bridge this interpretability gap, we propose SegCompass, an end-to-end model that leverages a Sparse Autoencoder (SAE) to forge an explicit, interpretable, and differentiable alignment pathway. Given an image-instruction pair, SegCompass first generates a chain-of-thought (CoT) trace. The core of our method is an SAE that maps both the CoT and visual tokens into a shared, high-dimensional sparse concept space. A query codebook selects salient concepts from this space, which are then spatially grounded by a slot mapper into a multi-slot heatmap that guides the final mask decoder. The entire model is trained jointly, unifying reinforcement learning for the reasoning path with standard segmentation supervision. This SAE-driven interface provides a "white-box" connection that is significantly more traceable than latent queries and more coherent than textual readouts. Extensive experiments on five challenging benchmarks demonstrate that SegCompass matches or surpasses state-of-the-art performance. Crucially, our visual and quantitative analyses show a strong correlation between the quality of the learned sparse concepts and final mask accuracy, confirming that SegCompass achieves superior results through its enhanced and inspectable alignment. Code is available at https://github.com/ZhenyuLU-Heliodore/SegCompass.
Data-Free Class Incremental Gesture Recognition via Synthetic Feature Sampling
Aug 21, 2024Data-Free Class Incremental Learning (DFCIL) aims to enable models to continuously learn new classes while retraining knowledge of old classes, even when the training data for old classes is unavailable. Although explored primarily with image datasets by researchers, this study focuses on investigating DFCIL for skeleton-based gesture classification due to its significant real-world implications, particularly considering the growing prevalence of VR/AR headsets where gestures serve as the primary means of control and interaction. In this work, we made an intriguing observation: skeleton models trained with base classes(even very limited) demonstrate strong generalization capabilities to unseen classes without requiring additional training. Building on this insight, we developed Synthetic Feature Replay (SFR) that can sample synthetic features from class prototypes to replay for old classes and augment for new classes (under a few-shot setting). Our proposed method showcases significant advancements over the state-of-the-art, achieving up to 15% enhancements in mean accuracy across all steps and largely mitigating the accuracy imbalance between base classes and new classes.
BrewCLIP: A Bifurcated Representation Learning Framework for Audio-Visual Retrieval
Aug 19, 2024Previous methods for audio-image matching generally fall into one of two categories: pipeline models or End-to-End models. Pipeline models first transcribe speech and then encode the resulting text; End-to-End models encode speech directly. Generally, pipeline models outperform end-to-end models, but the intermediate transcription necessarily discards some potentially useful non-textual information. In addition to textual information, speech can convey details such as accent, mood, and and emphasis, which should be effectively captured in the encoded representation. In this paper, we investigate whether non-textual information, which is overlooked by pipeline-based models, can be leveraged to improve speech-image matching performance. We thoroughly analyze and compare End-to-End models, pipeline models, and our proposed dual-channel model for robust audio-image retrieval on a variety of datasets. Our approach achieves a substantial performance gain over the previous state-of-the-art by leveraging strong pretrained models, a prompting mechanism and a bifurcated design.
TacShade A New 3D-printed Soft Optical Tactile Sensor Based on Light, Shadow and Greyscale for Shape Reconstruction
Jun 01, 2024



In this paper, we present the TacShade a newly designed 3D-printed soft optical tactile sensor. The sensor is developed for shape reconstruction under the inspiration of sketch drawing that uses the density of sketch lines to draw light and shadow, resulting in the creation of a 3D-view effect. TacShade, building upon the strengths of the TacTip, a single-camera tactile sensor of large in-depth deformation and being sensitive to edge and surface following, improves the structure in that the markers are distributed within the gap of papillae pins. Variations in light, dark, and grey effects can be generated inside the sensor through external contact interactions. The contours of the contacting objects are outlined by white markers, while the contact depth characteristics can be indirectly obtained from the distribution of black pins and white markers, creating a 2.5D visualization. Based on the imaging effect, we improve the Shape from Shading (SFS) algorithm to process tactile images, enabling a coarse but fast reconstruction for the contact objects. Two experiments are performed. The first verifies TacShade s ability to reconstruct the shape of the contact objects through one image for object distinction. The second experiment shows the shape reconstruction capability of TacShade for a large panel with ridged patterns based on the location of robots and image splicing technology.
SC-ML: Self-supervised Counterfactual Metric Learning for Debiased Visual Question Answering
Apr 04, 2023



Visual question answering (VQA) is a critical multimodal task in which an agent must answer questions according to the visual cue. Unfortunately, language bias is a common problem in VQA, which refers to the model generating answers only by associating with the questions while ignoring the visual content, resulting in biased results. We tackle the language bias problem by proposing a self-supervised counterfactual metric learning (SC-ML) method to focus the image features better. SC-ML can adaptively select the question-relevant visual features to answer the question, reducing the negative influence of question-irrelevant visual features on inferring answers. In addition, question-irrelevant visual features can be seamlessly incorporated into counterfactual training schemes to further boost robustness. Extensive experiments have proved the effectiveness of our method with improved results on the VQA-CP dataset. Our code will be made publicly available.
AdaTriplet-RA: Domain Matching via Adaptive Triplet and Reinforced Attention for Unsupervised Domain Adaptation
Nov 16, 2022Unsupervised domain adaption (UDA) is a transfer learning task where the data and annotations of the source domain are available but only have access to the unlabeled target data during training. Most previous methods try to minimise the domain gap by performing distribution alignment between the source and target domains, which has a notable limitation, i.e., operating at the domain level, but neglecting the sample-level differences. To mitigate this weakness, we propose to improve the unsupervised domain adaptation task with an inter-domain sample matching scheme. We apply the widely-used and robust Triplet loss to match the inter-domain samples. To reduce the catastrophic effect of the inaccurate pseudo-labels generated during training, we propose a novel uncertainty measurement method to select reliable pseudo-labels automatically and progressively refine them. We apply the advanced discrete relaxation Gumbel Softmax technique to realise an adaptive Topk scheme to fulfil the functionality. In addition, to enable the global ranking optimisation within one batch for the domain matching, the whole model is optimised via a novel reinforced attention mechanism with supervision from the policy gradient algorithm, using the Average Precision (AP) as the reward. Our model (termed \textbf{\textit{AdaTriplet-RA}}) achieves State-of-the-art results on several public benchmark datasets, and its effectiveness is validated via comprehensive ablation studies. Our method improves the accuracy of the baseline by 9.7\% (ResNet-101) and 6.2\% (ResNet-50) on the VisDa dataset and 4.22\% (ResNet-50) on the Domainnet dataset. {The source code is publicly available at \textit{https://github.com/shuxy0120/AdaTriplet-RA}}.
Causal Effect Estimation using Variational Information Bottleneck
Oct 26, 2021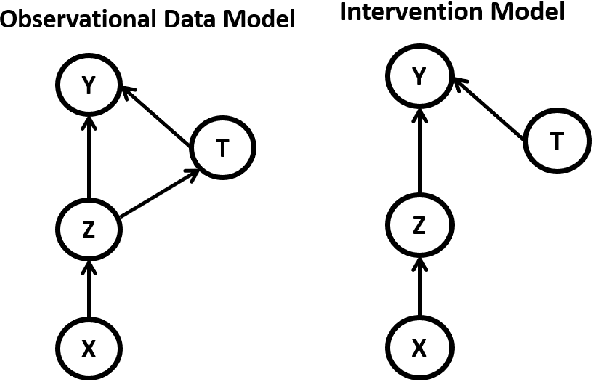
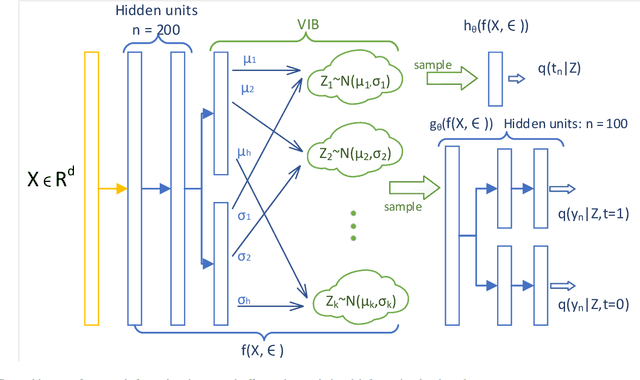
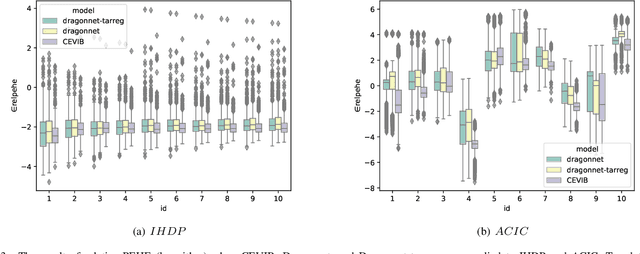
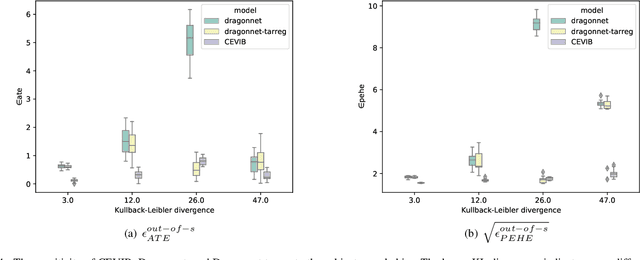
Causal inference is to estimate the causal effect in a causal relationship when intervention is applied. Precisely, in a causal model with binary interventions, i.e., control and treatment, the causal effect is simply the difference between the factual and counterfactual. The difficulty is that the counterfactual may never been obtained which has to be estimated and so the causal effect could only be an estimate. The key challenge for estimating the counterfactual is to identify confounders which effect both outcomes and treatments. A typical approach is to formulate causal inference as a supervised learning problem and so counterfactual could be predicted. Including linear regression and deep learning models, recent machine learning methods have been adapted to causal inference. In this paper, we propose a method to estimate Causal Effect by using Variational Information Bottleneck (CEVIB). The promising point is that VIB is able to naturally distill confounding variables from the data, which enables estimating causal effect by using observational data. We have compared CEVIB to other methods by applying them to three data sets showing that our approach achieved the best performance. We also experimentally showed the robustness of our method.