 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTacGen: Robotic Pushing with Vision-to-Touch Generation
Oct 15, 2025Robotic pushing is a fundamental manipulation task that requires tactile feedback to capture subtle contact forces and dynamics between the end-effector and the object. However, real tactile sensors often face hardware limitations such as high costs and fragility, and deployment challenges involving calibration and variations between different sensors, while vision-only policies struggle with satisfactory performance. Inspired by humans' ability to infer tactile states from vision, we propose ViTacGen, a novel robot manipulation framework designed for visual robotic pushing with vision-to-touch generation in reinforcement learning to eliminate the reliance on high-resolution real tactile sensors, enabling effective zero-shot deployment on visual-only robotic systems. Specifically, ViTacGen consists of an encoder-decoder vision-to-touch generation network that generates contact depth images, a standardized tactile representation, directly from visual image sequence, followed by a reinforcement learning policy that fuses visual-tactile data with contrastive learning based on visual and generated tactile observations. We validate the effectiveness of our approach in both simulation and real world experiments, demonstrating its superior performance and achieving a success rate of up to 86\%.
General Force Sensation for Tactile Robot
Mar 02, 2025



Robotic tactile sensors, including vision-based and taxel-based sensors, enable agile manipulation and safe human-robot interaction through force sensation. However, variations in structural configurations, measured signals, and material properties create domain gaps that limit the transferability of learned force sensation across different tactile sensors. Here, we introduce GenForce, a general framework for achieving transferable force sensation across both homogeneous and heterogeneous tactile sensors in robotic systems. By unifying tactile signals into marker-based binary tactile images, GenForce enables the transfer of existing force labels to arbitrary target sensors using a marker-to-marker translation technique with a few paired data. This process equips uncalibrated tactile sensors with force prediction capabilities through spatiotemporal force prediction models trained on the transferred data. Extensive experimental results validate GenForce's generalizability, accuracy, and robustness across sensors with diverse marker patterns, structural designs, material properties, and sensing principles. The framework significantly reduces the need for costly and labor-intensive labeled data collection, enabling the rapid deployment of multiple tactile sensors on robotic hands requiring force sensing capabilities.
ManiSkill-ViTac 2025: Challenge on Manipulation Skill Learning With Vision and Tactile Sensing
Nov 19, 2024This article introduces the ManiSkill-ViTac Challenge 2025, which focuses on learning contact-rich manipulation skills using both tactile and visual sensing. Expanding upon the 2024 challenge, ManiSkill-ViTac 2025 includes 3 independent tracks: tactile manipulation, tactile-vision fusion manipulation, and tactile sensor structure design. The challenge aims to push the boundaries of robotic manipulation skills, emphasizing the integration of tactile and visual data to enhance performance in complex, real-world tasks. Participants will be evaluated using standardized metrics across both simulated and real-world environments, spurring innovations in sensor design and significantly advancing the field of vision-tactile fusion in robotics.
TacShade A New 3D-printed Soft Optical Tactile Sensor Based on Light, Shadow and Greyscale for Shape Reconstruction
Jun 01, 2024



In this paper, we present the TacShade a newly designed 3D-printed soft optical tactile sensor. The sensor is developed for shape reconstruction under the inspiration of sketch drawing that uses the density of sketch lines to draw light and shadow, resulting in the creation of a 3D-view effect. TacShade, building upon the strengths of the TacTip, a single-camera tactile sensor of large in-depth deformation and being sensitive to edge and surface following, improves the structure in that the markers are distributed within the gap of papillae pins. Variations in light, dark, and grey effects can be generated inside the sensor through external contact interactions. The contours of the contacting objects are outlined by white markers, while the contact depth characteristics can be indirectly obtained from the distribution of black pins and white markers, creating a 2.5D visualization. Based on the imaging effect, we improve the Shape from Shading (SFS) algorithm to process tactile images, enabling a coarse but fast reconstruction for the contact objects. Two experiments are performed. The first verifies TacShade s ability to reconstruct the shape of the contact objects through one image for object distinction. The second experiment shows the shape reconstruction capability of TacShade for a large panel with ridged patterns based on the location of robots and image splicing technology.
BrainSLAM: SLAM on Neural Population Activity Data
Feb 01, 2024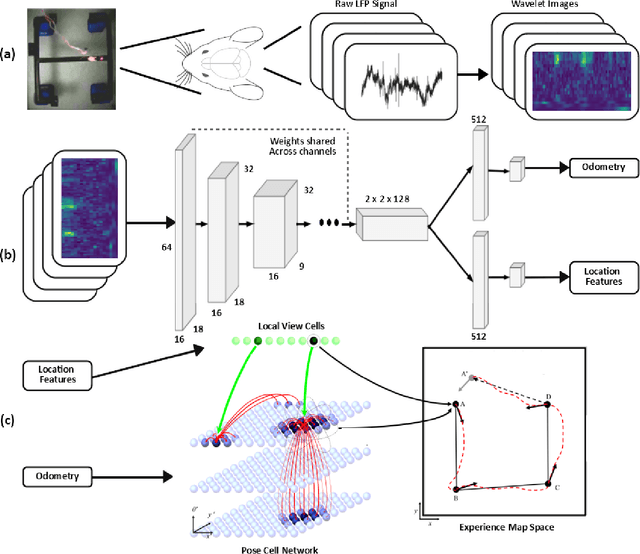

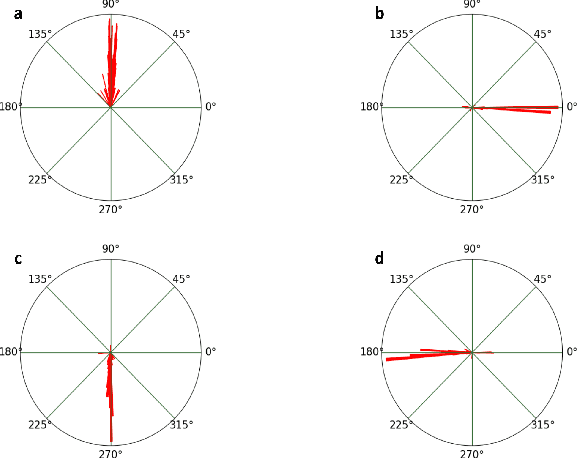
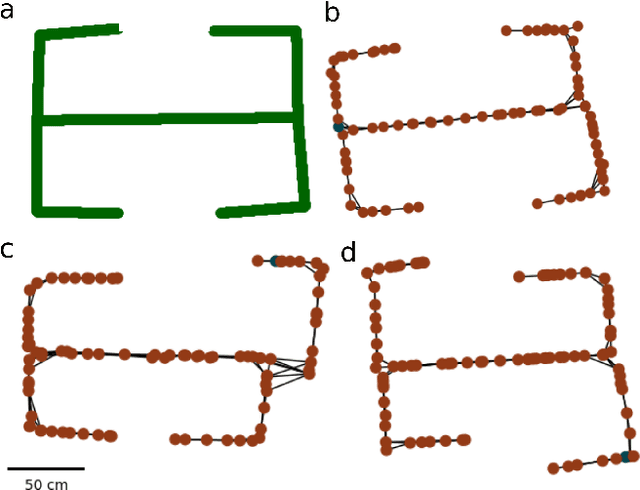
Simultaneous localisation and mapping (SLAM) algorithms are commonly used in robotic systems for learning maps of novel environments. Brains also appear to learn maps, but the mechanisms are not known and it is unclear how to infer these maps from neural activity data. We present BrainSLAM; a method for performing SLAM using only population activity (local field potential, LFP) data simultaneously recorded from three brain regions in rats: hippocampus, prefrontal cortex, and parietal cortex. This system uses a convolutional neural network (CNN) to decode velocity and familiarity information from wavelet scalograms of neural local field potential data recorded from rats as they navigate a 2D maze. The CNN's output drives a RatSLAM-inspired architecture, powering an attractor network which performs path integration plus a separate system which performs `loop closure' (detecting previously visited locations and correcting map aliasing errors). Together, these three components can construct faithful representations of the environment while simultaneously tracking the animal's location. This is the first demonstration of inference of a spatial map from brain recordings. Our findings expand SLAM to a new modality, enabling a new method of mapping environments and facilitating a better understanding of the role of cognitive maps in navigation and decision making.
ViTacTip: Design and Verification of a Novel Biomimetic Physical Vision-Tactile Fusion Sensor
Jan 31, 2024Tactile sensing is significant for robotics since it can obtain physical contact information during manipulation. To capture multimodal contact information within a compact framework, we designed a novel sensor called ViTacTip, which seamlessly integrates both tactile and visual perception capabilities into a single, integrated sensor unit. ViTacTip features a transparent skin to capture fine features of objects during contact, which can be known as the see-through-skin mechanism. In the meantime, the biomimetic tips embedded in ViTacTip can amplify touch motions during tactile perception. For comparative analysis, we also fabricated a ViTac sensor devoid of biomimetic tips, as well as a TacTip sensor with opaque skin. Furthermore, we develop a Generative Adversarial Network (GAN)-based approach for modality switching between different perception modes, effectively alternating the emphasis between vision and tactile perception modes. We conducted a performance evaluation of the proposed sensor across three distinct tasks: i) grating identification, ii) pose regression, and iii) contact localization and force estimation. In the grating identification task, ViTacTip demonstrated an accuracy of 99.72%, surpassing TacTip, which achieved 94.60%. It also exhibited superior performance in both pose and force estimation tasks with the minimum error of 0.08mm and 0.03N, respectively, in contrast to ViTac's 0.12mm and 0.15N. Results indicate that ViTacTip outperforms single-modality sensors.
A pose and shear-based tactile robotic system for object tracking, surface following and object pushing
Jun 26, 2023Tactile perception is a crucial sensing modality in robotics, particularly in scenarios that require precise manipulation and safe interaction with other objects. Previous research in this area has focused extensively on tactile perception of contact poses as this is an important capability needed for tasks such as traversing an object's surface or edge, manipulating an object, or pushing an object along a predetermined path. Another important capability needed for tasks such as object tracking and manipulation is estimation of post-contact shear but this has received much less attention. Indeed, post-contact shear has often been considered a "nuisance variable" and is removed if possible because it can have an adverse effect on other types of tactile perception such as contact pose estimation. This paper proposes a tactile robotic system that can simultaneously estimate both the contact pose and post-contact shear, and use this information to control its interaction with other objects. Moreover, our new system is capable of interacting with other objects in a smooth and continuous manner, unlike the stepwise, position-controlled systems we have used in the past. We demonstrate the capabilities of our new system using several different controller configurations, on tasks including object tracking, surface following, single-arm object pushing, and dual-arm object pushing.
What deep reinforcement learning tells us about human motor learning and vice-versa
Aug 26, 2022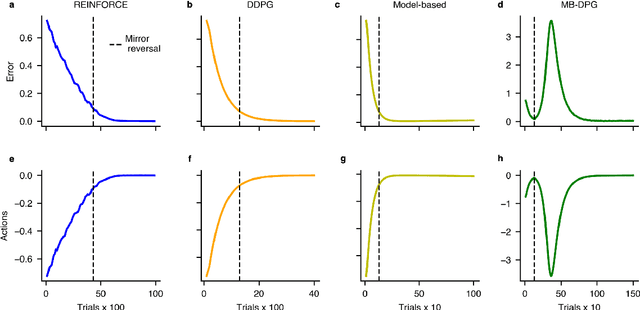
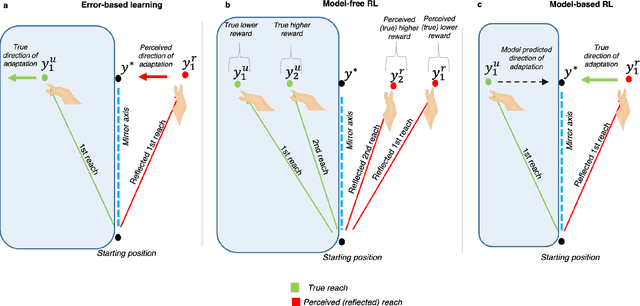
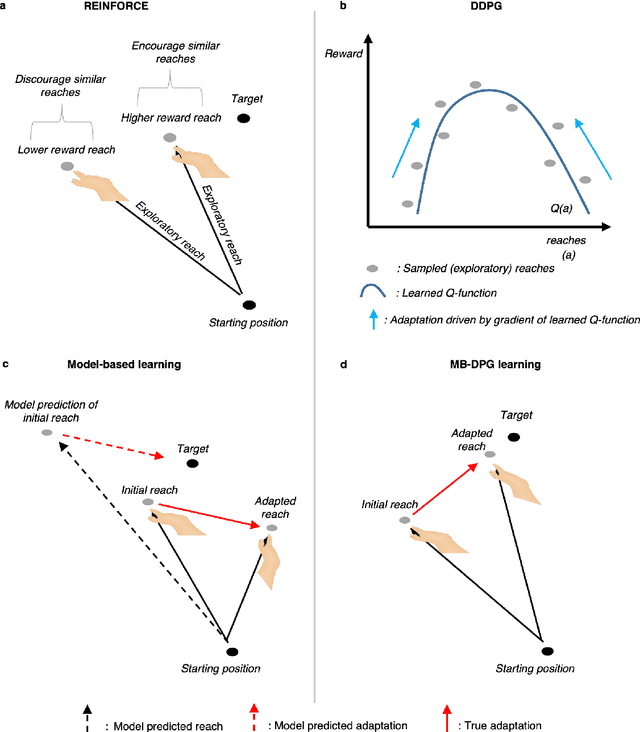
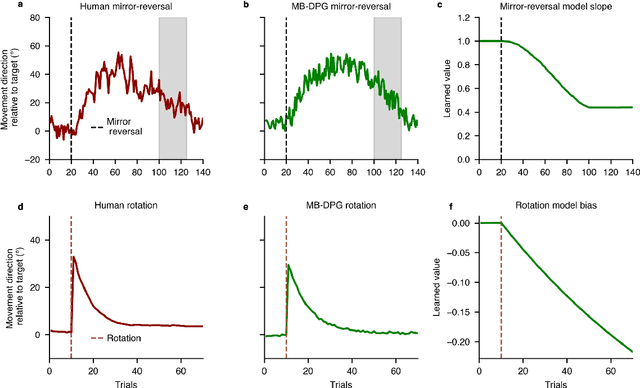
Machine learning and specifically reinforcement learning (RL) has been extremely successful in helping us to understand neural decision making processes. However, RL's role in understanding other neural processes especially motor learning is much less well explored. To explore this connection, we investigated how recent deep RL methods correspond to the dominant motor learning framework in neuroscience, error-based learning. Error-based learning can be probed using a mirror reversal adaptation paradigm, where it produces distinctive qualitative predictions that are observed in humans. We therefore tested three major families of modern deep RL algorithm on a mirror reversal perturbation. Surprisingly, all of the algorithms failed to mimic human behaviour and indeed displayed qualitatively different behaviour from that predicted by error-based learning. To fill this gap, we introduce a novel deep RL algorithm: model-based deterministic policy gradients (MB-DPG). MB-DPG draws inspiration from error-based learning by explicitly relying on the observed outcome of actions. We show MB-DPG captures (human) error-based learning under mirror-reversal and rotational perturbation. Next, we demonstrate error-based learning in the form of MB-DPG learns faster than canonical model-free algorithms on complex arm-based reaching tasks, while being more robust to (forward) model misspecification than model-based RL. These findings highlight the gap between current deep RL methods and human motor adaptation and offer a route to closing this gap, facilitating future beneficial interaction between between the two fields.
One-Shot Domain-Adaptive Imitation Learning via Progressive Learning
Apr 24, 2022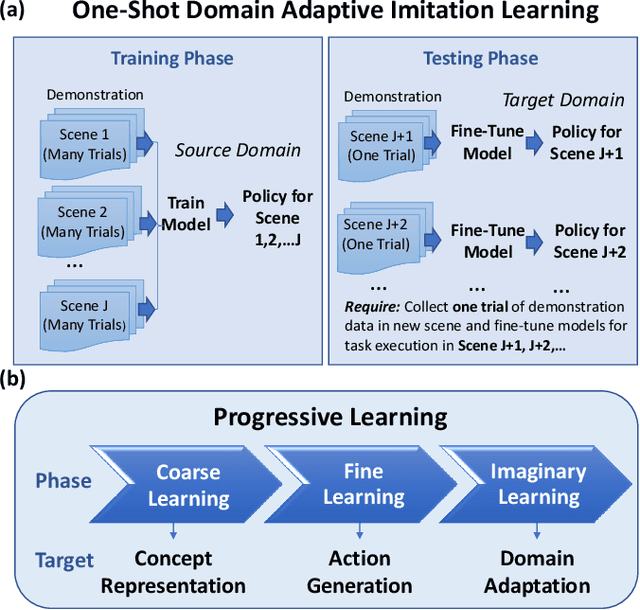
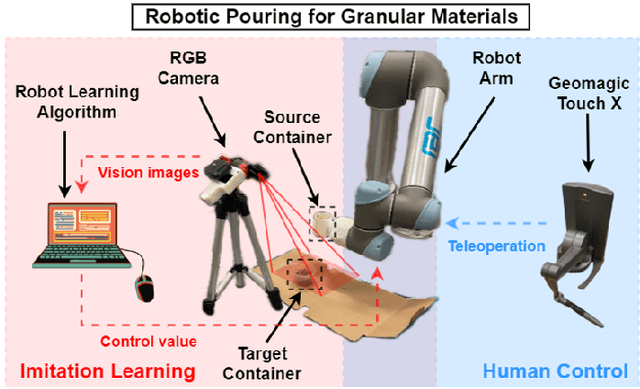


Traditional deep learning-based visual imitation learning techniques require a large amount of demonstration data for model training, and the pre-trained models are difficult to adapt to new scenarios. To address these limitations, we propose a unified framework using a novel progressive learning approach comprised of three phases: i) a coarse learning phase for concept representation, ii) a fine learning phase for action generation, and iii) an imaginary learning phase for domain adaptation. Overall, this approach leads to a one-shot domain-adaptive imitation learning framework. We use robotic pouring task as an example to evaluate its effectiveness. Our results show that the method has several advantages over contemporary end-to-end imitation learning approaches, including an improved success rate for task execution and more efficient training for deep imitation learning. In addition, the generalizability to new domains is improved, as demonstrated here with novel background, target container and granule combinations. We believe that the proposed method can be broadly applicable to different industrial or domestic applications that involve deep imitation learning for robotic manipulation, where the target scenarios have high diversity while the human demonstration data is limited.
Learning offline: memory replay in biological and artificial reinforcement learning
Sep 21, 2021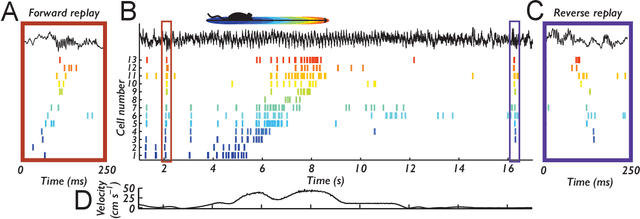
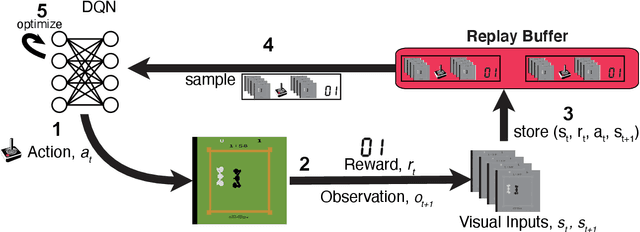
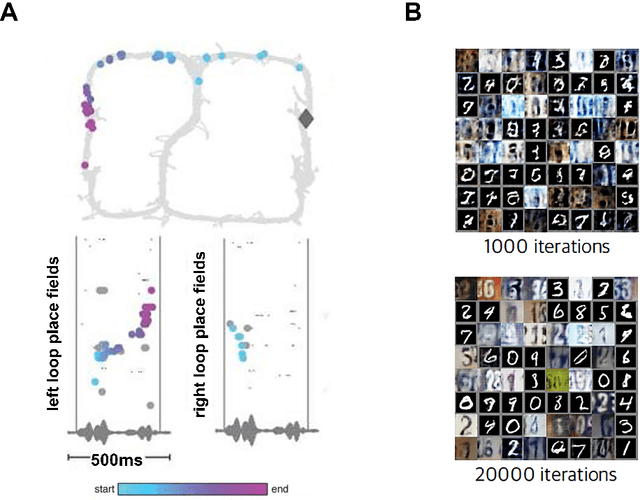
Learning to act in an environment to maximise rewards is among the brain's key functions. This process has often been conceptualised within the framework of reinforcement learning, which has also gained prominence in machine learning and artificial intelligence (AI) as a way to optimise decision-making. A common aspect of both biological and machine reinforcement learning is the reactivation of previously experienced episodes, referred to as replay. Replay is important for memory consolidation in biological neural networks, and is key to stabilising learning in deep neural networks. Here, we review recent developments concerning the functional roles of replay in the fields of neuroscience and AI. Complementary progress suggests how replay might support learning processes, including generalisation and continual learning, affording opportunities to transfer knowledge across the two fields to advance the understanding of biological and artificial learning and memory.