 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaylor TD-learning
Feb 27, 2023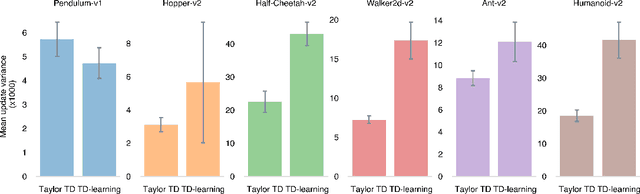
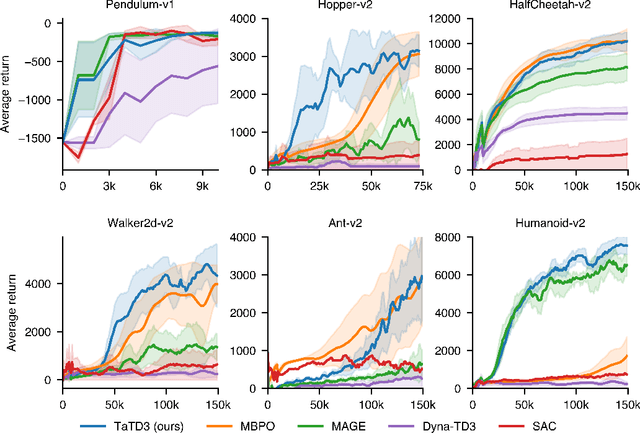
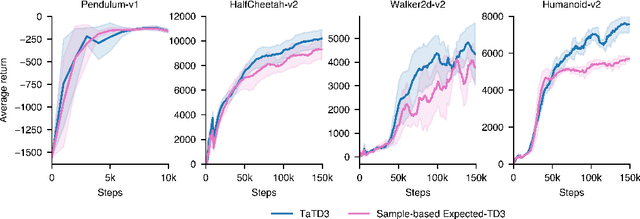
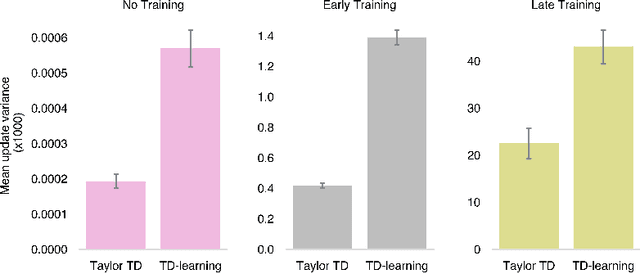
Many reinforcement learning approaches rely on temporal-difference (TD) learning to learn a critic. However, TD-learning updates can be high variance due to their sole reliance on Monte Carlo estimates of the updates. Here, we introduce a model-based RL framework, Taylor TD, which reduces this variance. Taylor TD uses a first-order Taylor series expansion of TD updates. This expansion allows to analytically integrate over stochasticity in the action-choice, and some stochasticity in the state distribution for the initial state and action of each TD update. We include theoretical and empirical evidence of Taylor TD updates being lower variance than (standard) TD updates. Additionally, we show that Taylor TD has the same stable learning guarantees as (standard) TD-learning under linear function approximation. Next, we combine Taylor TD with the TD3 algorithm (Fujimoto et al., 2018), into TaTD3. We show TaTD3 performs as well, if not better, than several state-of-the art model-free and model-based baseline algorithms on a set of standard benchmark tasks. Finally, we include further analysis of the settings in which Taylor TD may be most beneficial to performance relative to standard TD-learning.
What deep reinforcement learning tells us about human motor learning and vice-versa
Aug 26, 2022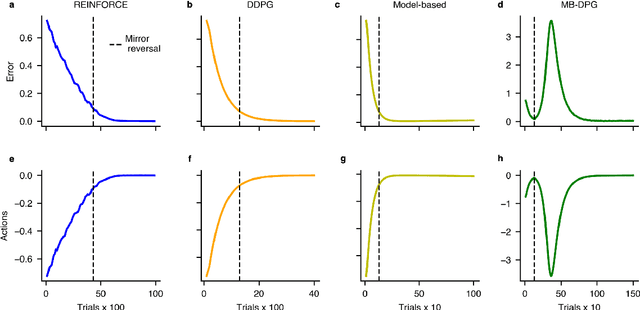
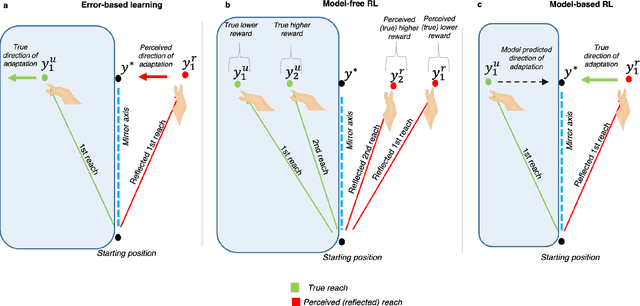
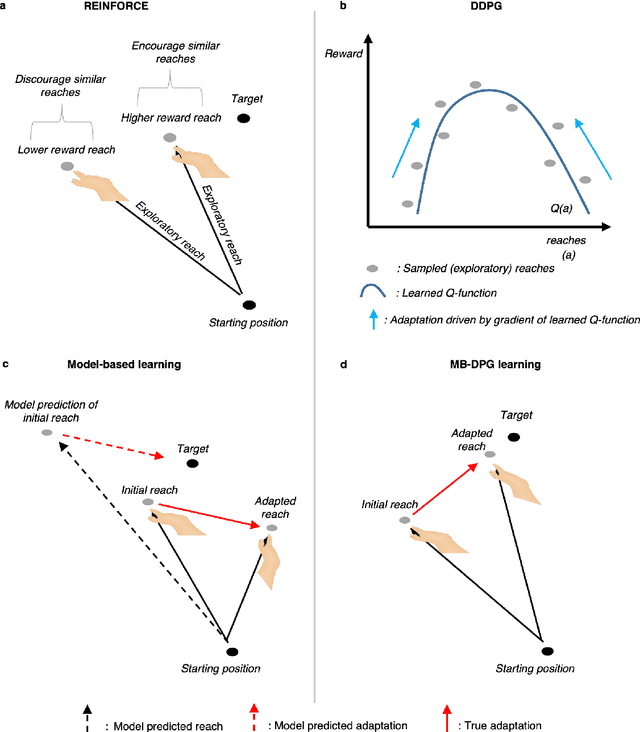
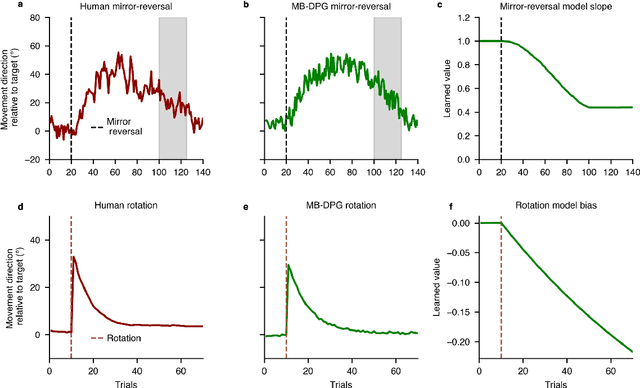
Machine learning and specifically reinforcement learning (RL) has been extremely successful in helping us to understand neural decision making processes. However, RL's role in understanding other neural processes especially motor learning is much less well explored. To explore this connection, we investigated how recent deep RL methods correspond to the dominant motor learning framework in neuroscience, error-based learning. Error-based learning can be probed using a mirror reversal adaptation paradigm, where it produces distinctive qualitative predictions that are observed in humans. We therefore tested three major families of modern deep RL algorithm on a mirror reversal perturbation. Surprisingly, all of the algorithms failed to mimic human behaviour and indeed displayed qualitatively different behaviour from that predicted by error-based learning. To fill this gap, we introduce a novel deep RL algorithm: model-based deterministic policy gradients (MB-DPG). MB-DPG draws inspiration from error-based learning by explicitly relying on the observed outcome of actions. We show MB-DPG captures (human) error-based learning under mirror-reversal and rotational perturbation. Next, we demonstrate error-based learning in the form of MB-DPG learns faster than canonical model-free algorithms on complex arm-based reaching tasks, while being more robust to (forward) model misspecification than model-based RL. These findings highlight the gap between current deep RL methods and human motor adaptation and offer a route to closing this gap, facilitating future beneficial interaction between between the two fields.