 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre you Struggling? Dataset and Baselines for Struggle Determination in Assembly Videos
Feb 28, 2024Determining when people are struggling from video enables a finer-grained understanding of actions and opens opportunities for building intelligent support visual interfaces. In this paper, we present a new dataset with three assembly activities and corresponding performance baselines for the determination of struggle from video. Three real-world problem-solving activities including assembling plumbing pipes (Pipes-Struggle), pitching camping tents (Tent-Struggle) and solving the Tower of Hanoi puzzle (Tower-Struggle) are introduced. Video segments were scored w.r.t. the level of struggle as perceived by annotators using a forced choice 4-point scale. Each video segment was annotated by a single expert annotator in addition to crowd-sourced annotations. The dataset is the first struggle annotation dataset and contains 5.1 hours of video and 725,100 frames from 73 participants in total. We evaluate three decision-making tasks: struggle classification, struggle level regression, and struggle label distribution learning. We provide baseline results for each of the tasks utilising several mainstream deep neural networks, along with an ablation study and visualisation of results. Our work is motivated toward assistive systems that analyze struggle, support users during manual activities and encourage learning, as well as other video understanding competencies.
What deep reinforcement learning tells us about human motor learning and vice-versa
Aug 26, 2022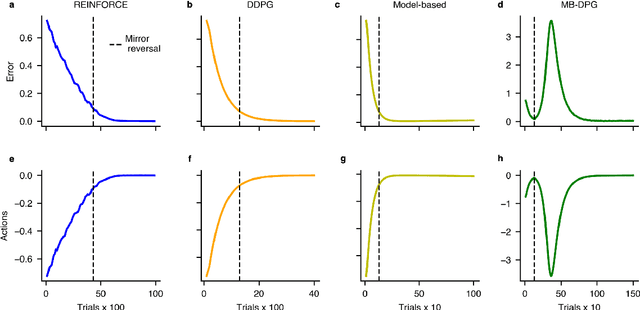
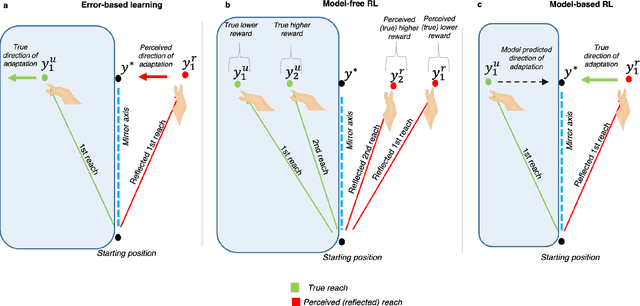
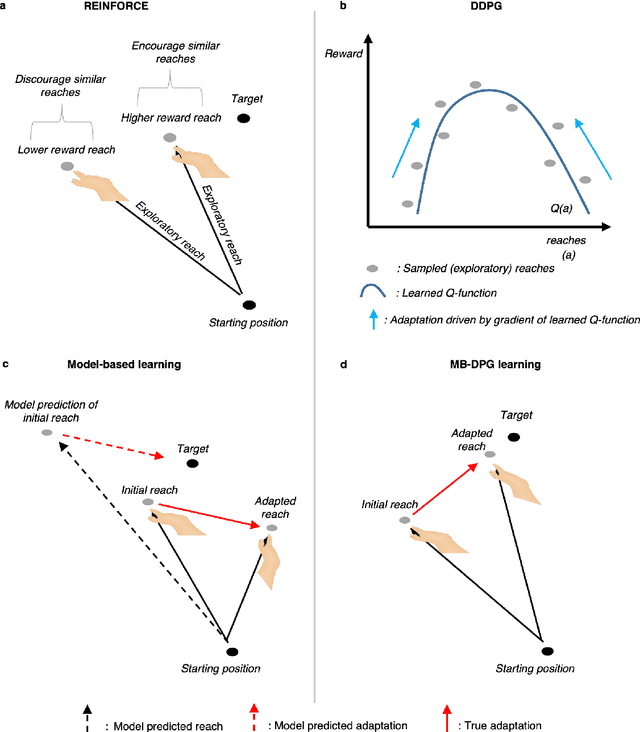
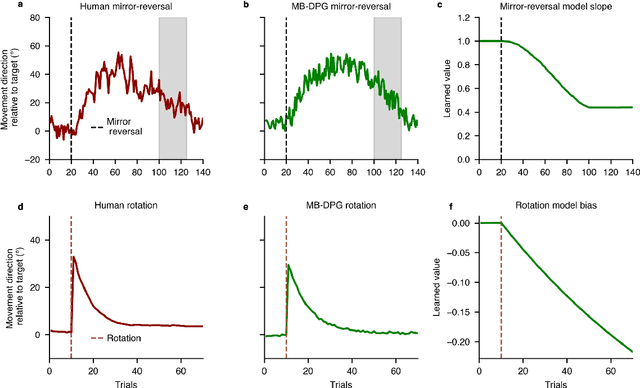
Machine learning and specifically reinforcement learning (RL) has been extremely successful in helping us to understand neural decision making processes. However, RL's role in understanding other neural processes especially motor learning is much less well explored. To explore this connection, we investigated how recent deep RL methods correspond to the dominant motor learning framework in neuroscience, error-based learning. Error-based learning can be probed using a mirror reversal adaptation paradigm, where it produces distinctive qualitative predictions that are observed in humans. We therefore tested three major families of modern deep RL algorithm on a mirror reversal perturbation. Surprisingly, all of the algorithms failed to mimic human behaviour and indeed displayed qualitatively different behaviour from that predicted by error-based learning. To fill this gap, we introduce a novel deep RL algorithm: model-based deterministic policy gradients (MB-DPG). MB-DPG draws inspiration from error-based learning by explicitly relying on the observed outcome of actions. We show MB-DPG captures (human) error-based learning under mirror-reversal and rotational perturbation. Next, we demonstrate error-based learning in the form of MB-DPG learns faster than canonical model-free algorithms on complex arm-based reaching tasks, while being more robust to (forward) model misspecification than model-based RL. These findings highlight the gap between current deep RL methods and human motor adaptation and offer a route to closing this gap, facilitating future beneficial interaction between between the two fields.