 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Detection to Anticipation: Online Understanding of Struggles across Various Tasks and Activities
Dec 10, 2025


Understanding human skill performance is essential for intelligent assistive systems, with struggle recognition offering a natural cue for identifying user difficulties. While prior work focuses on offline struggle classification and localization, real-time applications require models capable of detecting and anticipating struggle online. We reformulate struggle localization as an online detection task and further extend it to anticipation, predicting struggle moments before they occur. We adapt two off-the-shelf models as baselines for online struggle detection and anticipation. Online struggle detection achieves 70-80% per-frame mAP, while struggle anticipation up to 2 seconds ahead yields comparable performance with slight drops. We further examine generalization across tasks and activities and analyse the impact of skill evolution. Despite larger domain gaps in activity-level generalization, models still outperform random baselines by 4-20%. Our feature-based models run at up to 143 FPS, and the whole pipeline, including feature extraction, operates at around 20 FPS, sufficient for real-time assistive applications.
EvoStruggle: A Dataset Capturing the Evolution of Struggle across Activities and Skill Levels
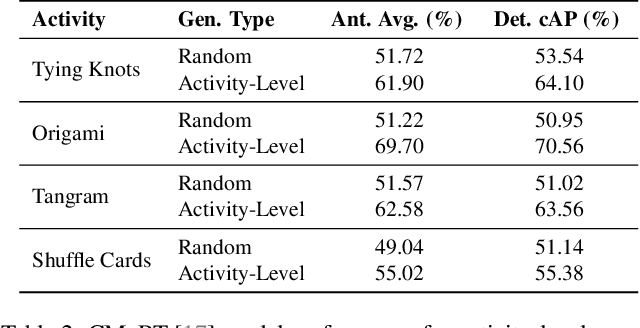
Oct 01, 2025The ability to determine when a person struggles during skill acquisition is crucial for both optimizing human learning and enabling the development of effective assistive systems. As skills develop, the type and frequency of struggles tend to change, and understanding this evolution is key to determining the user's current stage of learning. However, existing manipulation datasets have not focused on how struggle evolves over time. In this work, we collect a dataset for struggle determination, featuring 61.68 hours of video recordings, 2,793 videos, and 5,385 annotated temporal struggle segments collected from 76 participants. The dataset includes 18 tasks grouped into four diverse activities -- tying knots, origami, tangram puzzles, and shuffling cards, representing different task variations. In addition, participants repeated the same task five times to capture their evolution of skill. We define the struggle determination problem as a temporal action localization task, focusing on identifying and precisely localizing struggle segments with start and end times. Experimental results show that Temporal Action Localization models can successfully learn to detect struggle cues, even when evaluated on unseen tasks or activities. The models attain an overall average mAP of 34.56% when generalizing across tasks and 19.24% across activities, indicating that struggle is a transferable concept across various skill-based tasks while still posing challenges for further improvement in struggle detection. Our dataset is available at https://github.com/FELIXFENG2019/EvoStruggle.
X-LeBench: A Benchmark for Extremely Long Egocentric Video Understanding
Jan 12, 2025Long-form egocentric video understanding provides rich contextual information and unique insights into long-term human behaviors, holding significant potential for applications in embodied intelligence, long-term activity analysis, and personalized assistive technologies. However, existing benchmark datasets primarily focus on single, short-duration videos or moderately long videos up to dozens of minutes, leaving a substantial gap in evaluating extensive, ultra-long egocentric video recordings. To address this, we introduce X-LeBench, a novel benchmark dataset specifically crafted for evaluating tasks on extremely long egocentric video recordings. Leveraging the advanced text processing capabilities of large language models (LLMs), X-LeBench develops a life-logging simulation pipeline that produces realistic, coherent daily plans aligned with real-world video data. This approach enables the flexible integration of synthetic daily plans with real-world footage from Ego4D-a massive-scale egocentric video dataset covers a wide range of daily life scenarios-resulting in 432 simulated video life logs that mirror realistic daily activities in contextually rich scenarios. The video life-log durations span from 23 minutes to 16.4 hours. The evaluation of several baseline systems and multimodal large language models (MLLMs) reveals their poor performance across the board, highlighting the inherent challenges of long-form egocentric video understanding and underscoring the need for more advanced models.
Re-localization acceleration with Medoid Silhouette Clustering
Jul 30, 2024Two crucial performance criteria for the deployment of visual localization are speed and accuracy. Current research on visual localization with neural networks is limited to examining methods for enhancing the accuracy of networks across various datasets. How to expedite the re-localization process within deep neural network architectures still needs further investigation. In this paper, we present a novel approach for accelerating visual re-localization in practice. A tree-like search strategy, built on the keyframes extracted by a visual clustering algorithm, is designed for matching acceleration. Our method has been validated on two tasks across three public datasets, allowing for 50 up to 90 percent time saving over the baseline while not reducing location accuracy.
Are you Struggling? Dataset and Baselines for Struggle Determination in Assembly Videos
Feb 28, 2024Determining when people are struggling from video enables a finer-grained understanding of actions and opens opportunities for building intelligent support visual interfaces. In this paper, we present a new dataset with three assembly activities and corresponding performance baselines for the determination of struggle from video. Three real-world problem-solving activities including assembling plumbing pipes (Pipes-Struggle), pitching camping tents (Tent-Struggle) and solving the Tower of Hanoi puzzle (Tower-Struggle) are introduced. Video segments were scored w.r.t. the level of struggle as perceived by annotators using a forced choice 4-point scale. Each video segment was annotated by a single expert annotator in addition to crowd-sourced annotations. The dataset is the first struggle annotation dataset and contains 5.1 hours of video and 725,100 frames from 73 participants in total. We evaluate three decision-making tasks: struggle classification, struggle level regression, and struggle label distribution learning. We provide baseline results for each of the tasks utilising several mainstream deep neural networks, along with an ablation study and visualisation of results. Our work is motivated toward assistive systems that analyze struggle, support users during manual activities and encourage learning, as well as other video understanding competencies.
SuperTran: Reference Based Video Transformer for Enhancing Low Bitrate Streams in Real Time
Nov 22, 2022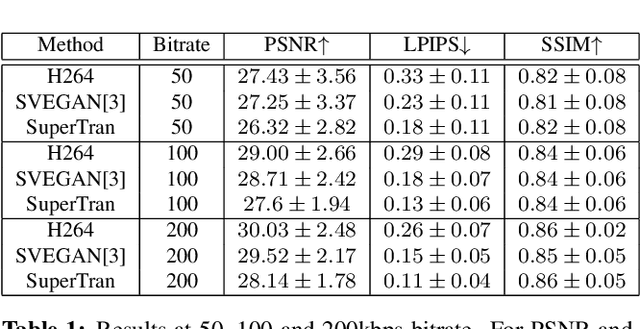


This work focuses on low bitrate video streaming scenarios (e.g. 50 - 200Kbps) where the video quality is severely compromised. We present a family of novel deep generative models for enhancing perceptual video quality of such streams by performing super-resolution while also removing compression artifacts. Our model, which we call SuperTran, consumes as input a single high-quality, high-resolution reference images in addition to the low-quality, low-resolution video stream. The model thus learns how to borrow or copy visual elements like textures from the reference image and fill in the remaining details from the low resolution stream in order to produce perceptually enhanced output video. The reference frame can be sent once at the start of the video session or be retrieved from a gallery. Importantly, the resulting output has substantially better detail than what has been otherwise possible with methods that only use a low resolution input such as the SuperVEGAN method. SuperTran works in real-time (up to 30 frames/sec) on the cloud alongside standard pipelines.
On-Sensor Binarized Fully Convolutional Neural Network with A Pixel Processor Array
Feb 02, 2022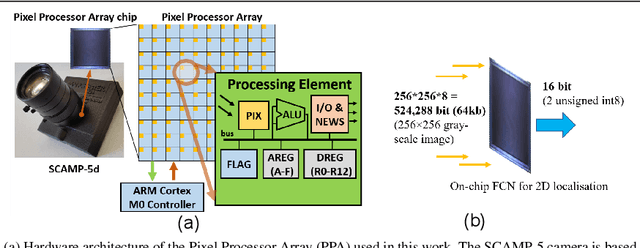
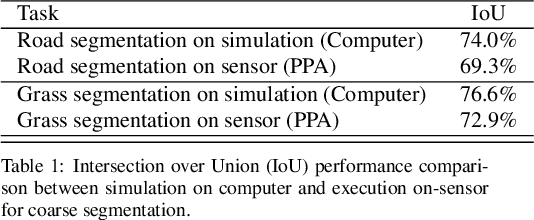


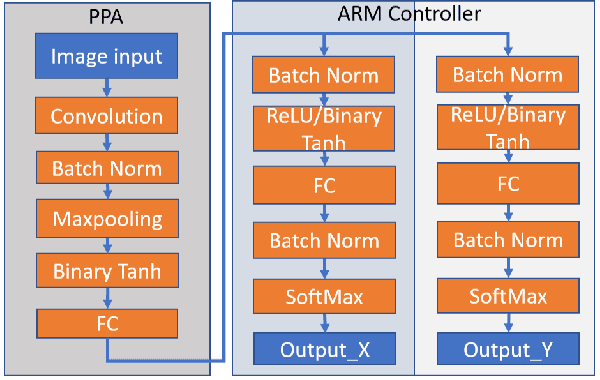
This work presents a method to implement fully convolutional neural networks (FCNs) on Pixel Processor Array (PPA) sensors, and demonstrates coarse segmentation and object localisation tasks. We design and train binarized FCN for both binary weights and activations using batchnorm, group convolution, and learnable threshold for binarization, producing networks small enough to be embedded on the focal plane of the PPA, with limited local memory resources, and using parallel elementary add/subtract, shifting, and bit operations only. We demonstrate the first implementation of an FCN on a PPA device, performing three convolution layers entirely in the pixel-level processors. We use this architecture to demonstrate inference generating heat maps for object segmentation and localisation at over 280 FPS using the SCAMP-5 PPA vision chip.
Bringing A Robot Simulator to the SCAMP Vision System
May 21, 2021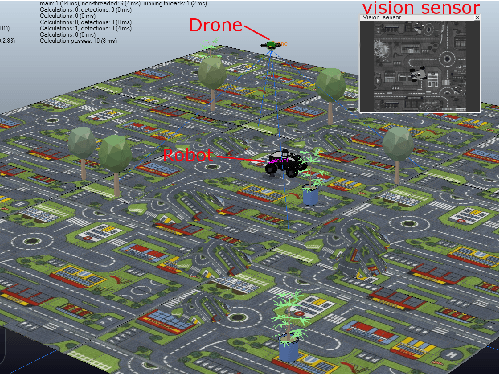
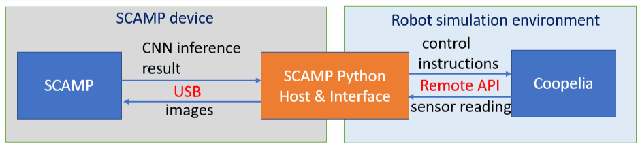

This work develops and demonstrates the integration of the SCAMP-5d vision system into the CoppeliaSim robot simulator, creating a semi-simulated environment. By configuring a camera in the simulator and setting up communication with the SCAMP python host through remote API, sensor images from the simulator can be transferred to the SCAMP vision sensor, where on-sensor image processing such as CNN inference can be performed. SCAMP output is then fed back into CoppeliaSim. This proposed platform integration enables rapid prototyping validations of SCAMP algorithms for robotic systems. We demonstrate a car localisation and tracking task using this proposed semi-simulated platform, with a CNN inference on SCAMP to command the motion of a robot. We made this platform available online.
Filter Distribution Templates in Convolutional Networks for Image Classification Tasks
Apr 28, 2021
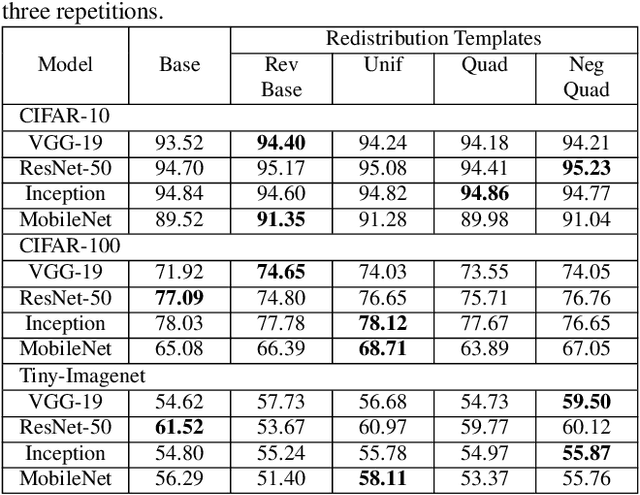
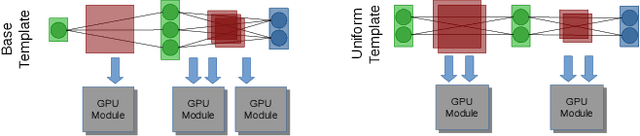
Neural network designers have reached progressive accuracy by increasing models depth, introducing new layer types and discovering new combinations of layers. A common element in many architectures is the distribution of the number of filters in each layer. Neural network models keep a pattern design of increasing filters in deeper layers such as those in LeNet, VGG, ResNet, MobileNet and even in automatic discovered architectures such as NASNet. It remains unknown if this pyramidal distribution of filters is the best for different tasks and constrains. In this work we present a series of modifications in the distribution of filters in four popular neural network models and their effects in accuracy and resource consumption. Results show that by applying this approach, some models improve up to 8.9% in accuracy showing reductions in parameters up to 54%.
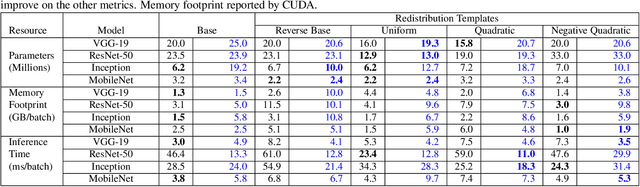
Towards Efficient Convolutional Network Models with Filter Distribution Templates
Apr 17, 2021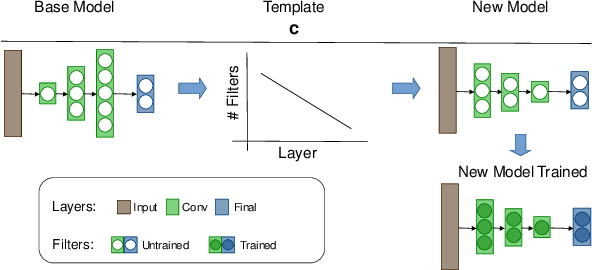
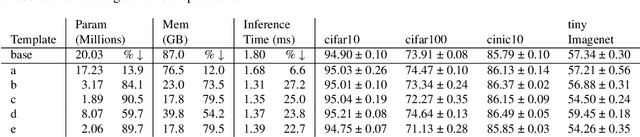
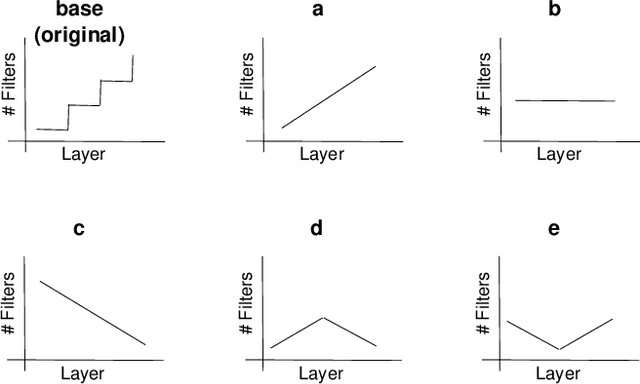

Increasing number of filters in deeper layers when feature maps are decreased is a widely adopted pattern in convolutional network design. It can be found in classical CNN architectures and in automatic discovered models. Even CNS methods commonly explore a selection of multipliers derived from this pyramidal pattern. We defy this practice by introducing a small set of templates consisting of easy to implement, intuitive and aggressive variations of the original pyramidal distribution of filters in VGG and ResNet architectures. Experiments on CIFAR, CINIC10 and TinyImagenet datasets show that models produced by our templates, are more efficient in terms of fewer parameters and memory needs.