 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICo3D: An Interactive Conversational 3D Virtual Human
Jan 19, 2026This work presents Interactive Conversational 3D Virtual Human (ICo3D), a method for generating an interactive, conversational, and photorealistic 3D human avatar. Based on multi-view captures of a subject, we create an animatable 3D face model and a dynamic 3D body model, both rendered by splatting Gaussian primitives. Once merged together, they represent a lifelike virtual human avatar suitable for real-time user interactions. We equip our avatar with an LLM for conversational ability. During conversation, the audio speech of the avatar is used as a driving signal to animate the face model, enabling precise synchronization. We describe improvements to our dynamic Gaussian models that enhance photorealism: SWinGS++ for body reconstruction and HeadGaS++ for face reconstruction, and provide as well a solution to merge the separate face and body models without artifacts. We also present a demo of the complete system, showcasing several use cases of real-time conversation with the 3D avatar. Our approach offers a fully integrated virtual avatar experience, supporting both oral and written form interactions in immersive environments. ICo3D is applicable to a wide range of fields, including gaming, virtual assistance, and personalized education, among others. Project page: https://ico3d.github.io/
Map2Thought: Explicit 3D Spatial Reasoning via Metric Cognitive Maps
Jan 16, 2026We propose Map2Thought, a framework that enables explicit and interpretable spatial reasoning for 3D VLMs. The framework is grounded in two key components: Metric Cognitive Map (Metric-CogMap) and Cognitive Chain-of-Thought (Cog-CoT). Metric-CogMap provides a unified spatial representation by integrating a discrete grid for relational reasoning with a continuous, metric-scale representation for precise geometric understanding. Building upon the Metric-CogMap, Cog-CoT performs explicit geometric reasoning through deterministic operations, including vector operations, bounding-box distances, and occlusion-aware appearance order cues, producing interpretable inference traces grounded in 3D structure. Experimental results show that Map2Thought enables explainable 3D understanding, achieving 59.9% accuracy using only half the supervision, closely matching the 60.9% baseline trained with the full dataset. It consistently outperforms state-of-the-art methods by 5.3%, 4.8%, and 4.0% under 10%, 25%, and 50% training subsets, respectively, on the VSI-Bench.
SA-ResGS: Self-Augmented Residual 3D Gaussian Splatting for Next Best View Selection
Jan 06, 2026We propose Self-Augmented Residual 3D Gaussian Splatting (SA-ResGS), a novel framework to stabilize uncertainty quantification and enhancing uncertainty-aware supervision in next-best-view (NBV) selection for active scene reconstruction. SA-ResGS improves both the reliability of uncertainty estimates and their effectiveness for supervision by generating Self-Augmented point clouds (SA-Points) via triangulation between a training view and a rasterized extrapolated view, enabling efficient scene coverage estimation. While improving scene coverage through physically guided view selection, SA-ResGS also addresses the challenge of under-supervised Gaussians, exacerbated by sparse and wide-baseline views, by introducing the first residual learning strategy tailored for 3D Gaussian Splatting. This targeted supervision enhances gradient flow in high-uncertainty Gaussians by combining uncertainty-driven filtering with dropout- and hard-negative-mining-inspired sampling. Our contributions are threefold: (1) a physically grounded view selection strategy that promotes efficient and uniform scene coverage; (2) an uncertainty-aware residual supervision scheme that amplifies learning signals for weakly contributing Gaussians, improving training stability and uncertainty estimation across scenes with diverse camera distributions; (3) an implicit unbiasing of uncertainty quantification as a consequence of constrained view selection and residual supervision, which together mitigate conflicting effects of wide-baseline exploration and sparse-view ambiguity in NBV planning. Experiments on active view selection demonstrate that SA-ResGS outperforms state-of-the-art baselines in both reconstruction quality and view selection robustness.
CoMapGS: Covisibility Map-based Gaussian Splatting for Sparse Novel View Synthesis
Mar 25, 2025We propose Covisibility Map-based Gaussian Splatting (CoMapGS), designed to recover underrepresented sparse regions in sparse novel view synthesis. CoMapGS addresses both high- and low-uncertainty regions by constructing covisibility maps, enhancing initial point clouds, and applying uncertainty-aware weighted supervision using a proximity classifier. Our contributions are threefold: (1) CoMapGS reframes novel view synthesis by leveraging covisibility maps as a core component to address region-specific uncertainty; (2) Enhanced initial point clouds for both low- and high-uncertainty regions compensate for sparse COLMAP-derived point clouds, improving reconstruction quality and benefiting few-shot 3DGS methods; (3) Adaptive supervision with covisibility-score-based weighting and proximity classification achieves consistent performance gains across scenes with varying sparsity scores derived from covisibility maps. Experimental results demonstrate that CoMapGS outperforms state-of-the-art methods on datasets including Mip-NeRF 360 and LLFF.
Are you Struggling? Dataset and Baselines for Struggle Determination in Assembly Videos
Feb 28, 2024Determining when people are struggling from video enables a finer-grained understanding of actions and opens opportunities for building intelligent support visual interfaces. In this paper, we present a new dataset with three assembly activities and corresponding performance baselines for the determination of struggle from video. Three real-world problem-solving activities including assembling plumbing pipes (Pipes-Struggle), pitching camping tents (Tent-Struggle) and solving the Tower of Hanoi puzzle (Tower-Struggle) are introduced. Video segments were scored w.r.t. the level of struggle as perceived by annotators using a forced choice 4-point scale. Each video segment was annotated by a single expert annotator in addition to crowd-sourced annotations. The dataset is the first struggle annotation dataset and contains 5.1 hours of video and 725,100 frames from 73 participants in total. We evaluate three decision-making tasks: struggle classification, struggle level regression, and struggle label distribution learning. We provide baseline results for each of the tasks utilising several mainstream deep neural networks, along with an ablation study and visualisation of results. Our work is motivated toward assistive systems that analyze struggle, support users during manual activities and encourage learning, as well as other video understanding competencies.
ILSH: The Imperial Light-Stage Head Dataset for Human Head View Synthesis
Oct 06, 2023



This paper introduces the Imperial Light-Stage Head (ILSH) dataset, a novel light-stage-captured human head dataset designed to support view synthesis academic challenges for human heads. The ILSH dataset is intended to facilitate diverse approaches, such as scene-specific or generic neural rendering, multiple-view geometry, 3D vision, and computer graphics, to further advance the development of photo-realistic human avatars. This paper details the setup of a light-stage specifically designed to capture high-resolution (4K) human head images and describes the process of addressing challenges (preprocessing, ethical issues) in collecting high-quality data. In addition to the data collection, we address the split of the dataset into train, validation, and test sets. Our goal is to design and support a fair view synthesis challenge task for this novel dataset, such that a similar level of performance can be maintained and expected when using the test set, as when using the validation set. The ILSH dataset consists of 52 subjects captured using 24 cameras with all 82 lighting sources turned on, resulting in a total of 1,248 close-up head images, border masks, and camera pose pairs.
Registration-free Face-SSD: Single shot analysis of smiles, facial attributes, and affect in the wild
Feb 11, 2019
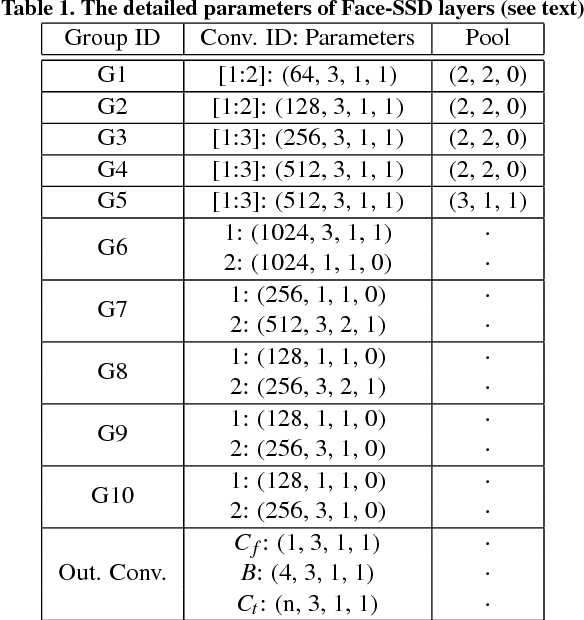
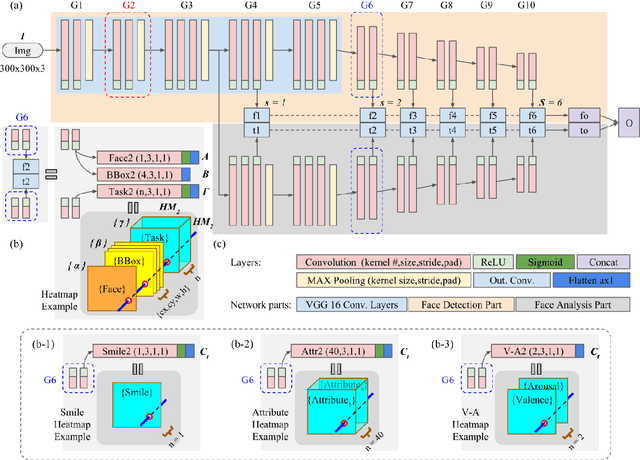

In this paper, we present a novel single shot face-related task analysis method, called Face-SSD, for detecting faces and for performing various face-related (classification/regression) tasks including smile recognition, face attribute prediction and valence-arousal estimation in the wild. Face-SSD uses a Fully Convolutional Neural Network (FCNN) to detect multiple faces of different sizes and recognise/regress one or more face-related classes. Face-SSD has two parallel branches that share the same low-level filters, one branch dealing with face detection and the other one with face analysis tasks. The outputs of both branches are spatially aligned heatmaps that are produced in parallel - therefore Face-SSD does not require that face detection, facial region extraction, size normalisation, and facial region processing are performed in subsequent steps. Our contributions are threefold: 1) Face-SSD is the first network to perform face analysis without relying on pre-processing such as face detection and registration in advance - Face-SSD is a simple and a single FCNN architecture simultaneously performing face detection and face-related task analysis - those are conventionally treated as separate consecutive tasks; 2) Face-SSD is a generalised architecture that is applicable for various face analysis tasks without modifying the network structure - this is in contrast to designing task-specific architectures; and 3) Face-SSD achieves real-time performance (21 FPS) even when detecting multiple faces and recognising multiple classes in a given image. Experimental results show that Face-SSD achieves state-of-the-art performance in various face analysis tasks by reaching a recognition accuracy of 95.76% for smile detection, 90.29% for attribute prediction, and Root Mean Square (RMS) error of 0.44 and 0.39 for valence and arousal estimation.