 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARCaster: Spatio-Temporal AutoRegressive Video Diffusion for Identity- and View-Aware Talking Portraits
Dec 15, 2025


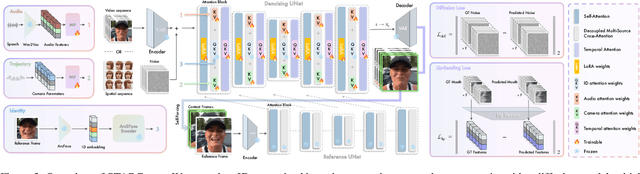
This paper presents STARCaster, an identity-aware spatio-temporal video diffusion model that addresses both speech-driven portrait animation and free-viewpoint talking portrait synthesis, given an identity embedding or reference image, within a unified framework. Existing 2D speech-to-video diffusion models depend heavily on reference guidance, leading to limited motion diversity. At the same time, 3D-aware animation typically relies on inversion through pre-trained tri-plane generators, which often leads to imperfect reconstructions and identity drift. We rethink reference- and geometry-based paradigms in two ways. First, we deviate from strict reference conditioning at pre-training by introducing softer identity constraints. Second, we address 3D awareness implicitly within the 2D video domain by leveraging the inherent multi-view nature of video data. STARCaster adopts a compositional approach progressing from ID-aware motion modeling, to audio-visual synchronization via lip reading-based supervision, and finally to novel view animation through temporal-to-spatial adaptation. To overcome the scarcity of 4D audio-visual data, we propose a decoupled learning approach in which view consistency and temporal coherence are trained independently. A self-forcing training scheme enables the model to learn from longer temporal contexts than those generated at inference, mitigating the overly static animations common in existing autoregressive approaches. Comprehensive evaluations demonstrate that STARCaster generalizes effectively across tasks and identities, consistently surpassing prior approaches in different benchmarks.
ID-Consistent, Precise Expression Generation with Blendshape-Guided Diffusion
Oct 06, 2025
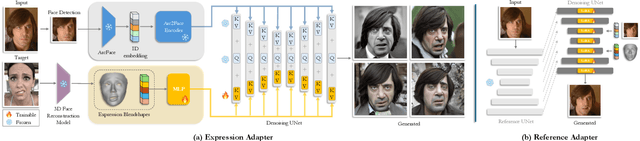
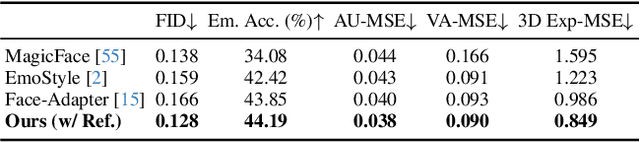

Human-centric generative models designed for AI-driven storytelling must bring together two core capabilities: identity consistency and precise control over human performance. While recent diffusion-based approaches have made significant progress in maintaining facial identity, achieving fine-grained expression control without compromising identity remains challenging. In this work, we present a diffusion-based framework that faithfully reimagines any subject under any particular facial expression. Building on an ID-consistent face foundation model, we adopt a compositional design featuring an expression cross-attention module guided by FLAME blendshape parameters for explicit control. Trained on a diverse mixture of image and video data rich in expressive variation, our adapter generalizes beyond basic emotions to subtle micro-expressions and expressive transitions, overlooked by prior works. In addition, a pluggable Reference Adapter enables expression editing in real images by transferring the appearance from a reference frame during synthesis. Extensive quantitative and qualitative evaluations show that our model outperforms existing methods in tailored and identity-consistent expression generation. Code and models can be found at https://github.com/foivospar/Arc2Face.
Arc2Avatar: Generating Expressive 3D Avatars from a Single Image via ID Guidance
Jan 09, 2025Inspired by the effectiveness of 3D Gaussian Splatting (3DGS) in reconstructing detailed 3D scenes within multi-view setups and the emergence of large 2D human foundation models, we introduce Arc2Avatar, the first SDS-based method utilizing a human face foundation model as guidance with just a single image as input. To achieve that, we extend such a model for diverse-view human head generation by fine-tuning on synthetic data and modifying its conditioning. Our avatars maintain a dense correspondence with a human face mesh template, allowing blendshape-based expression generation. This is achieved through a modified 3DGS approach, connectivity regularizers, and a strategic initialization tailored for our task. Additionally, we propose an optional efficient SDS-based correction step to refine the blendshape expressions, enhancing realism and diversity. Experiments demonstrate that Arc2Avatar achieves state-of-the-art realism and identity preservation, effectively addressing color issues by allowing the use of very low guidance, enabled by our strong identity prior and initialization strategy, without compromising detail.
AnimateMe: 4D Facial Expressions via Diffusion Models
Mar 25, 2024



The field of photorealistic 3D avatar reconstruction and generation has garnered significant attention in recent years; however, animating such avatars remains challenging. Recent advances in diffusion models have notably enhanced the capabilities of generative models in 2D animation. In this work, we directly utilize these models within the 3D domain to achieve controllable and high-fidelity 4D facial animation. By integrating the strengths of diffusion processes and geometric deep learning, we employ Graph Neural Networks (GNNs) as denoising diffusion models in a novel approach, formulating the diffusion process directly on the mesh space and enabling the generation of 3D facial expressions. This facilitates the generation of facial deformations through a mesh-diffusion-based model. Additionally, to ensure temporal coherence in our animations, we propose a consistent noise sampling method. Under a series of both quantitative and qualitative experiments, we showcase that the proposed method outperforms prior work in 4D expression synthesis by generating high-fidelity extreme expressions. Furthermore, we applied our method to textured 4D facial expression generation, implementing a straightforward extension that involves training on a large-scale textured 4D facial expression database.
Arc2Face: A Foundation Model of Human Faces
Mar 18, 2024This paper presents Arc2Face, an identity-conditioned face foundation model, which, given the ArcFace embedding of a person, can generate diverse photo-realistic images with an unparalleled degree of face similarity than existing models. Despite previous attempts to decode face recognition features into detailed images, we find that common high-resolution datasets (e.g. FFHQ) lack sufficient identities to reconstruct any subject. To that end, we meticulously upsample a significant portion of the WebFace42M database, the largest public dataset for face recognition (FR). Arc2Face builds upon a pretrained Stable Diffusion model, yet adapts it to the task of ID-to-face generation, conditioned solely on ID vectors. Deviating from recent works that combine ID with text embeddings for zero-shot personalization of text-to-image models, we emphasize on the compactness of FR features, which can fully capture the essence of the human face, as opposed to hand-crafted prompts. Crucially, text-augmented models struggle to decouple identity and text, usually necessitating some description of the given face to achieve satisfactory similarity. Arc2Face, however, only needs the discriminative features of ArcFace to guide the generation, offering a robust prior for a plethora of tasks where ID consistency is of paramount importance. As an example, we train a FR model on synthetic images from our model and achieve superior performance to existing synthetic datasets.
ILSH: The Imperial Light-Stage Head Dataset for Human Head View Synthesis
Oct 06, 2023



This paper introduces the Imperial Light-Stage Head (ILSH) dataset, a novel light-stage-captured human head dataset designed to support view synthesis academic challenges for human heads. The ILSH dataset is intended to facilitate diverse approaches, such as scene-specific or generic neural rendering, multiple-view geometry, 3D vision, and computer graphics, to further advance the development of photo-realistic human avatars. This paper details the setup of a light-stage specifically designed to capture high-resolution (4K) human head images and describes the process of addressing challenges (preprocessing, ethical issues) in collecting high-quality data. In addition to the data collection, we address the split of the dataset into train, validation, and test sets. Our goal is to design and support a fair view synthesis challenge task for this novel dataset, such that a similar level of performance can be maintained and expected when using the test set, as when using the validation set. The ILSH dataset consists of 52 subjects captured using 24 cameras with all 82 lighting sources turned on, resulting in a total of 1,248 close-up head images, border masks, and camera pose pairs.
Relightify: Relightable 3D Faces from a Single Image via Diffusion Models
May 10, 2023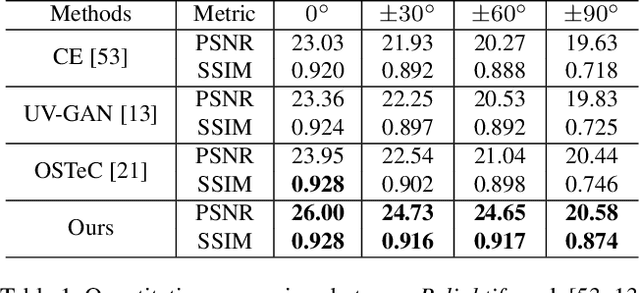
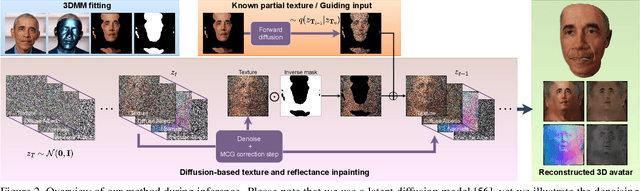

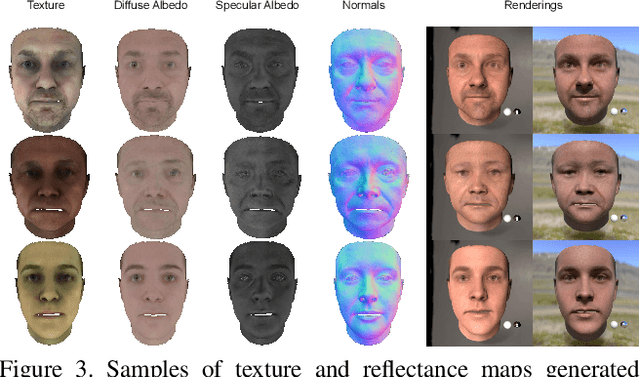
Following the remarkable success of diffusion models on image generation, recent works have also demonstrated their impressive ability to address a number of inverse problems in an unsupervised way, by properly constraining the sampling process based on a conditioning input. Motivated by this, in this paper, we present the first approach to use diffusion models as a prior for highly accurate 3D facial BRDF reconstruction from a single image. We start by leveraging a high-quality UV dataset of facial reflectance (diffuse and specular albedo and normals), which we render under varying illumination settings to simulate natural RGB textures and, then, train an unconditional diffusion model on concatenated pairs of rendered textures and reflectance components. At test time, we fit a 3D morphable model to the given image and unwrap the face in a partial UV texture. By sampling from the diffusion model, while retaining the observed texture part intact, the model inpaints not only the self-occluded areas but also the unknown reflectance components, in a single sequence of denoising steps. In contrast to existing methods, we directly acquire the observed texture from the input image, thus, resulting in more faithful and consistent reflectance estimation. Through a series of qualitative and quantitative comparisons, we demonstrate superior performance in both texture completion as well as reflectance reconstruction tasks.
Neural Emotion Director: Speech-preserving semantic control of facial expressions in "in-the-wild" videos
Dec 01, 2021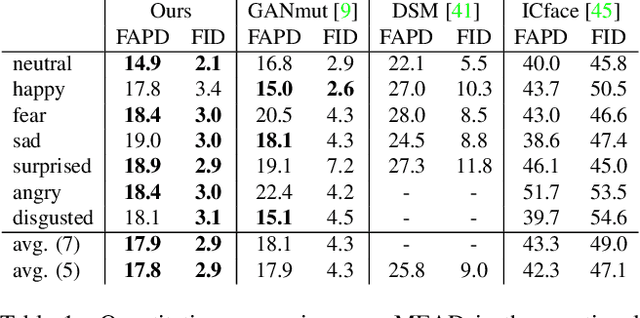
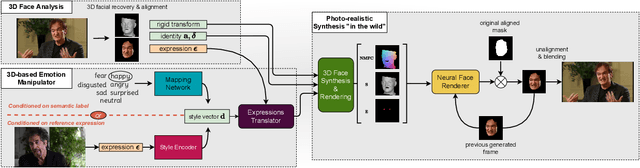


In this paper, we introduce a novel deep learning method for photo-realistic manipulation of the emotional state of actors in "in-the-wild" videos. The proposed method is based on a parametric 3D face representation of the actor in the input scene that offers a reliable disentanglement of the facial identity from the head pose and facial expressions. It then uses a novel deep domain translation framework that alters the facial expressions in a consistent and plausible manner, taking into account their dynamics. Finally, the altered facial expressions are used to photo-realistically manipulate the facial region in the input scene based on an especially-designed neural face renderer. To the best of our knowledge, our method is the first to be capable of controlling the actor's facial expressions by even using as a sole input the semantic labels of the manipulated emotions, while at the same time preserving the speech-related lip movements. We conduct extensive qualitative and quantitative evaluations and comparisons, which demonstrate the effectiveness of our approach and the especially promising results that we obtain. Our method opens a plethora of new possibilities for useful applications of neural rendering technologies, ranging from movie post-production and video games to photo-realistic affective avatars.