 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Learning for 3D Hand-Object Reconstruction and Compositional Action Recognition from Egocentric RGB Videos Using Superquadrics
Jan 13, 2025

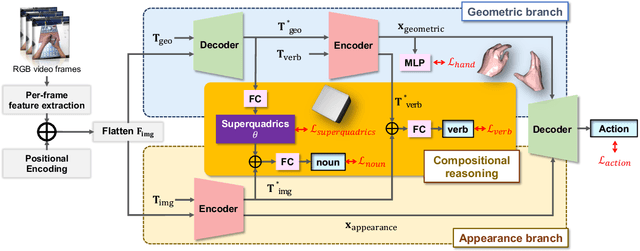

With the availability of egocentric 3D hand-object interaction datasets, there is increasing interest in developing unified models for hand-object pose estimation and action recognition. However, existing methods still struggle to recognise seen actions on unseen objects due to the limitations in representing object shape and movement using 3D bounding boxes. Additionally, the reliance on object templates at test time limits their generalisability to unseen objects. To address these challenges, we propose to leverage superquadrics as an alternative 3D object representation to bounding boxes and demonstrate their effectiveness on both template-free object reconstruction and action recognition tasks. Moreover, as we find that pure appearance-based methods can outperform the unified methods, the potential benefits from 3D geometric information remain unclear. Therefore, we study the compositionality of actions by considering a more challenging task where the training combinations of verbs and nouns do not overlap with the testing split. We extend H2O and FPHA datasets with compositional splits and design a novel collaborative learning framework that can explicitly reason about the geometric relations between hands and the manipulated object. Through extensive quantitative and qualitative evaluations, we demonstrate significant improvements over the state-of-the-arts in (compositional) action recognition.
Agri-LLaVA: Knowledge-Infused Large Multimodal Assistant on Agricultural Pests and Diseases
Dec 03, 2024



In the general domain, large multimodal models (LMMs) have achieved significant advancements, yet challenges persist in applying them to specific fields, especially agriculture. As the backbone of the global economy, agriculture confronts numerous challenges, with pests and diseases being particularly concerning due to their complexity, variability, rapid spread, and high resistance. This paper specifically addresses these issues. We construct the first multimodal instruction-following dataset in the agricultural domain, covering over 221 types of pests and diseases with approximately 400,000 data entries. This dataset aims to explore and address the unique challenges in pest and disease control. Based on this dataset, we propose a knowledge-infused training method to develop Agri-LLaVA, an agricultural multimodal conversation system. To accelerate progress in this field and inspire more researchers to engage, we design a diverse and challenging evaluation benchmark for agricultural pests and diseases. Experimental results demonstrate that Agri-LLaVA excels in agricultural multimodal conversation and visual understanding, providing new insights and approaches to address agricultural pests and diseases. By open-sourcing our dataset and model, we aim to promote research and development in LMMs within the agricultural domain and make significant contributions to tackle the challenges of agricultural pests and diseases. All resources can be found at https://github.com/Kki2Eve/Agri-LLaVA.
bit2bit: 1-bit quanta video reconstruction via self-supervised photon prediction
Oct 30, 2024
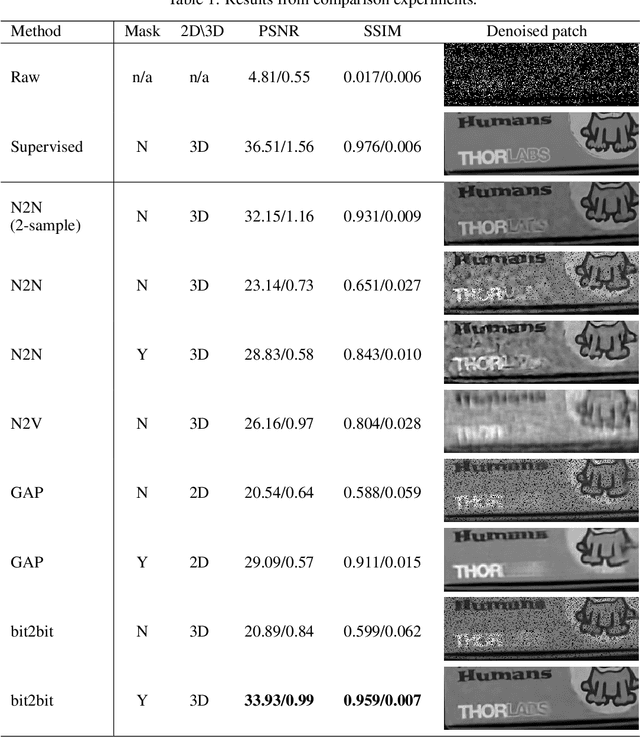


Quanta image sensors, such as SPAD arrays, are an emerging sensor technology, producing 1-bit arrays representing photon detection events over exposures as short as a few nanoseconds. In practice, raw data are post-processed using heavy spatiotemporal binning to create more useful and interpretable images at the cost of degrading spatiotemporal resolution. In this work, we propose bit2bit, a new method for reconstructing high-quality image stacks at the original spatiotemporal resolution from sparse binary quanta image data. Inspired by recent work on Poisson denoising, we developed an algorithm that creates a dense image sequence from sparse binary photon data by predicting the photon arrival location probability distribution. However, due to the binary nature of the data, we show that the assumption of a Poisson distribution is inadequate. Instead, we model the process with a Bernoulli lattice process from the truncated Poisson. This leads to the proposal of a novel self-supervised solution based on a masked loss function. We evaluate our method using both simulated and real data. On simulated data from a conventional video, we achieve 34.35 mean PSNR with extremely photon-sparse binary input (<0.06 photons per pixel per frame). We also present a novel dataset containing a wide range of real SPAD high-speed videos under various challenging imaging conditions. The scenes cover strong/weak ambient light, strong motion, ultra-fast events, etc., which will be made available to the community, on which we demonstrate the promise of our approach. Both reconstruction quality and throughput substantially surpass the state-of-the-art methods (e.g., Quanta Burst Photography (QBP)). Our approach significantly enhances the visualization and usability of the data, enabling the application of existing analysis techniques.
Improving Object Detection via Local-global Contrastive Learning
Oct 07, 2024
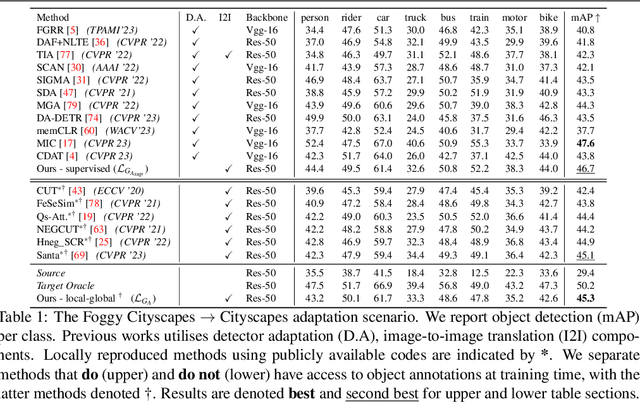
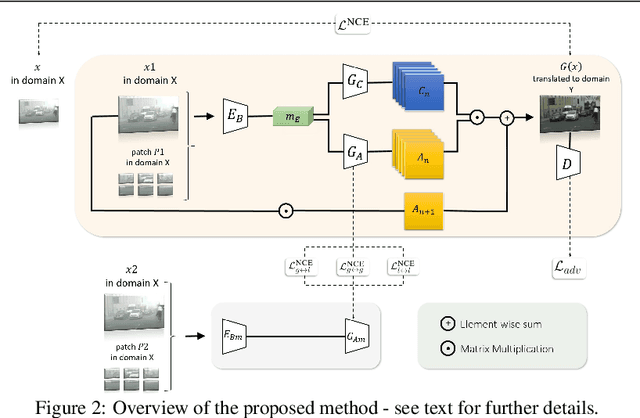
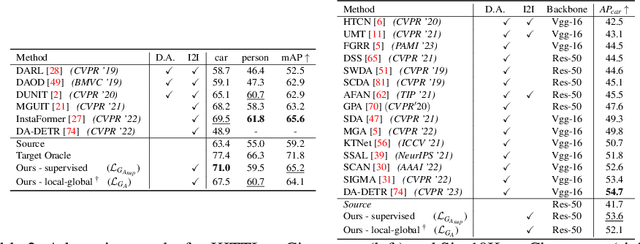
Visual domain gaps often impact object detection performance. Image-to-image translation can mitigate this effect, where contrastive approaches enable learning of the image-to-image mapping under unsupervised regimes. However, existing methods often fail to handle content-rich scenes with multiple object instances, which manifests in unsatisfactory detection performance. Sensitivity to such instance-level content is typically only gained through object annotations, which can be expensive to obtain. Towards addressing this issue, we present a novel image-to-image translation method that specifically targets cross-domain object detection. We formulate our approach as a contrastive learning framework with an inductive prior that optimises the appearance of object instances through spatial attention masks, implicitly delineating the scene into foreground regions associated with the target object instances and background non-object regions. Instead of relying on object annotations to explicitly account for object instances during translation, our approach learns to represent objects by contrasting local-global information. This affords investigation of an under-explored challenge: obtaining performant detection, under domain shifts, without relying on object annotations nor detector model fine-tuning. We experiment with multiple cross-domain object detection settings across three challenging benchmarks and report state-of-the-art performance. Project page: https://local-global-detection.github.io
GeoReF: Geometric Alignment Across Shape Variation for Category-level Object Pose Refinement
Apr 17, 2024Object pose refinement is essential for robust object pose estimation. Previous work has made significant progress towards instance-level object pose refinement. Yet, category-level pose refinement is a more challenging problem due to large shape variations within a category and the discrepancies between the target object and the shape prior. To address these challenges, we introduce a novel architecture for category-level object pose refinement. Our approach integrates an HS-layer and learnable affine transformations, which aims to enhance the extraction and alignment of geometric information. Additionally, we introduce a cross-cloud transformation mechanism that efficiently merges diverse data sources. Finally, we push the limits of our model by incorporating the shape prior information for translation and size error prediction. We conducted extensive experiments to demonstrate the effectiveness of the proposed framework. Through extensive quantitative experiments, we demonstrate significant improvement over the baseline method by a large margin across all metrics.
ILSH: The Imperial Light-Stage Head Dataset for Human Head View Synthesis
Oct 06, 2023



This paper introduces the Imperial Light-Stage Head (ILSH) dataset, a novel light-stage-captured human head dataset designed to support view synthesis academic challenges for human heads. The ILSH dataset is intended to facilitate diverse approaches, such as scene-specific or generic neural rendering, multiple-view geometry, 3D vision, and computer graphics, to further advance the development of photo-realistic human avatars. This paper details the setup of a light-stage specifically designed to capture high-resolution (4K) human head images and describes the process of addressing challenges (preprocessing, ethical issues) in collecting high-quality data. In addition to the data collection, we address the split of the dataset into train, validation, and test sets. Our goal is to design and support a fair view synthesis challenge task for this novel dataset, such that a similar level of performance can be maintained and expected when using the test set, as when using the validation set. The ILSH dataset consists of 52 subjects captured using 24 cameras with all 82 lighting sources turned on, resulting in a total of 1,248 close-up head images, border masks, and camera pose pairs.
Multi-task Learning with 3D-Aware Regularization
Oct 02, 2023

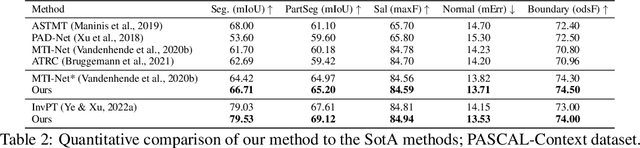
Deep neural networks have become a standard building block for designing models that can perform multiple dense computer vision tasks such as depth estimation and semantic segmentation thanks to their ability to capture complex correlations in high dimensional feature space across tasks. However, the cross-task correlations that are learned in the unstructured feature space can be extremely noisy and susceptible to overfitting, consequently hurting performance. We propose to address this problem by introducing a structured 3D-aware regularizer which interfaces multiple tasks through the projection of features extracted from an image encoder to a shared 3D feature space and decodes them into their task output space through differentiable rendering. We show that the proposed method is architecture agnostic and can be plugged into various prior multi-task backbones to improve their performance; as we evidence using standard benchmarks NYUv2 and PASCAL-Context.
Image Denoising and the Generative Accumulation of Photons
Aug 01, 2023
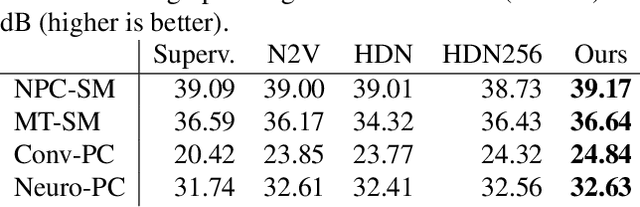
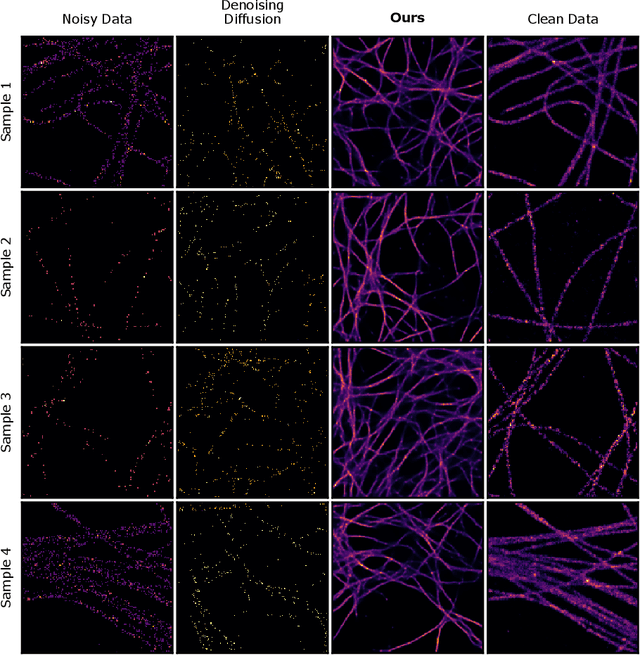

We present a fresh perspective on shot noise corrupted images and noise removal. By viewing image formation as the sequential accumulation of photons on a detector grid, we show that a network trained to predict where the next photon could arrive is in fact solving the minimum mean square error (MMSE) denoising task. This new perspective allows us to make three contributions: We present a new strategy for self-supervised denoising, We present a new method for sampling from the posterior of possible solutions by iteratively sampling and adding small numbers of photons to the image. We derive a full generative model by starting this process from an empty canvas. We call this approach generative accumulation of photons (GAP). We evaluate our method quantitatively and qualitatively on 4 new fluorescence microscopy datasets, which will be made available to the community. We find that it outperforms supervised, self-supervised and unsupervised baselines or performs on-par.
HS-Pose: Hybrid Scope Feature Extraction for Category-level Object Pose Estimation
Mar 28, 2023
In this paper, we focus on the problem of category-level object pose estimation, which is challenging due to the large intra-category shape variation. 3D graph convolution (3D-GC) based methods have been widely used to extract local geometric features, but they have limitations for complex shaped objects and are sensitive to noise. Moreover, the scale and translation invariant properties of 3D-GC restrict the perception of an object's size and translation information. In this paper, we propose a simple network structure, the HS-layer, which extends 3D-GC to extract hybrid scope latent features from point cloud data for category-level object pose estimation tasks. The proposed HS-layer: 1) is able to perceive local-global geometric structure and global information, 2) is robust to noise, and 3) can encode size and translation information. Our experiments show that the simple replacement of the 3D-GC layer with the proposed HS-layer on the baseline method (GPV-Pose) achieves a significant improvement, with the performance increased by 14.5% on 5d2cm metric and 10.3% on IoU75. Our method outperforms the state-of-the-art methods by a large margin (8.3% on 5d2cm, 6.9% on IoU75) on the REAL275 dataset and runs in real-time (50 FPS).
On the Importance of Accurate Geometry Data for Dense 3D Vision Tasks
Mar 26, 2023



Learning-based methods to solve dense 3D vision problems typically train on 3D sensor data. The respectively used principle of measuring distances provides advantages and drawbacks. These are typically not compared nor discussed in the literature due to a lack of multi-modal datasets. Texture-less regions are problematic for structure from motion and stereo, reflective material poses issues for active sensing, and distances for translucent objects are intricate to measure with existing hardware. Training on inaccurate or corrupt data induces model bias and hampers generalisation capabilities. These effects remain unnoticed if the sensor measurement is considered as ground truth during the evaluation. This paper investigates the effect of sensor errors for the dense 3D vision tasks of depth estimation and reconstruction. We rigorously show the significant impact of sensor characteristics on the learned predictions and notice generalisation issues arising from various technologies in everyday household environments. For evaluation, we introduce a carefully designed dataset\footnote{dataset available at https://github.com/Junggy/HAMMER-dataset} comprising measurements from commodity sensors, namely D-ToF, I-ToF, passive/active stereo, and monocular RGB+P. Our study quantifies the considerable sensor noise impact and paves the way to improved dense vision estimates and targeted data fusion.