 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspALL: Adaptive Structural Compensation from Illumination Variation for Robotic Garment Grasping in Any Low-Light Conditions
Mar 16, 2026Achieving accurate garment grasping under dynamically changing illumination is crucial for all-day operation of service robots.However, the reduced illumination in low-light scenes severely degrades garment structural features, leading to a significant drop in grasping robustness.Existing methods typically enhance RGB features by exploiting the illumination-invariant properties of non-RGB modalities, yet they overlook the varying dependence on non-RGB features under varying lighting conditions, which can introduce misaligned non-RGB cues and thereby weaken the model's adaptability to illumination changes when utilizing multimodal information.To address this problem, we propose GraspALL, an illumination-structure interactive compensation model.The innovation of GraspALL lies in encoding continuous illumination changes into quantitative references to guide adaptive feature fusion between RGB and non-RGB modalities according to varying lighting intensities, thereby generating illumination-consistent grasping representations.Experiments on the self-built garment grasping dataset demonstrate that GraspALL improves grasping accuracy by 32-44% over baselines under diverse illumination conditions.
Collaborative Learning for 3D Hand-Object Reconstruction and Compositional Action Recognition from Egocentric RGB Videos Using Superquadrics
Jan 13, 2025

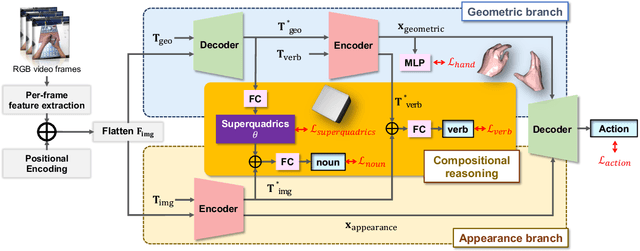

With the availability of egocentric 3D hand-object interaction datasets, there is increasing interest in developing unified models for hand-object pose estimation and action recognition. However, existing methods still struggle to recognise seen actions on unseen objects due to the limitations in representing object shape and movement using 3D bounding boxes. Additionally, the reliance on object templates at test time limits their generalisability to unseen objects. To address these challenges, we propose to leverage superquadrics as an alternative 3D object representation to bounding boxes and demonstrate their effectiveness on both template-free object reconstruction and action recognition tasks. Moreover, as we find that pure appearance-based methods can outperform the unified methods, the potential benefits from 3D geometric information remain unclear. Therefore, we study the compositionality of actions by considering a more challenging task where the training combinations of verbs and nouns do not overlap with the testing split. We extend H2O and FPHA datasets with compositional splits and design a novel collaborative learning framework that can explicitly reason about the geometric relations between hands and the manipulated object. Through extensive quantitative and qualitative evaluations, we demonstrate significant improvements over the state-of-the-arts in (compositional) action recognition.
Joint-Motion Mutual Learning for Pose Estimation in Videos
Aug 05, 2024Human pose estimation in videos has long been a compelling yet challenging task within the realm of computer vision. Nevertheless, this task remains difficult because of the complex video scenes, such as video defocus and self-occlusion. Recent methods strive to integrate multi-frame visual features generated by a backbone network for pose estimation. However, they often ignore the useful joint information encoded in the initial heatmap, which is a by-product of the backbone generation. Comparatively, methods that attempt to refine the initial heatmap fail to consider any spatio-temporal motion features. As a result, the performance of existing methods for pose estimation falls short due to the lack of ability to leverage both local joint (heatmap) information and global motion (feature) dynamics. To address this problem, we propose a novel joint-motion mutual learning framework for pose estimation, which effectively concentrates on both local joint dependency and global pixel-level motion dynamics. Specifically, we introduce a context-aware joint learner that adaptively leverages initial heatmaps and motion flow to retrieve robust local joint feature. Given that local joint feature and global motion flow are complementary, we further propose a progressive joint-motion mutual learning that synergistically exchanges information and interactively learns between joint feature and motion flow to improve the capability of the model. More importantly, to capture more diverse joint and motion cues, we theoretically analyze and propose an information orthogonality objective to avoid learning redundant information from multi-cues. Empirical experiments show our method outperforms prior arts on three challenging benchmarks.
DiffPose: SpatioTemporal Diffusion Model for Video-Based Human Pose Estimation
Aug 05, 2023



Denoising diffusion probabilistic models that were initially proposed for realistic image generation have recently shown success in various perception tasks (e.g., object detection and image segmentation) and are increasingly gaining attention in computer vision. However, extending such models to multi-frame human pose estimation is non-trivial due to the presence of the additional temporal dimension in videos. More importantly, learning representations that focus on keypoint regions is crucial for accurate localization of human joints. Nevertheless, the adaptation of the diffusion-based methods remains unclear on how to achieve such objective. In this paper, we present DiffPose, a novel diffusion architecture that formulates video-based human pose estimation as a conditional heatmap generation problem. First, to better leverage temporal information, we propose SpatioTemporal Representation Learner which aggregates visual evidences across frames and uses the resulting features in each denoising step as a condition. In addition, we present a mechanism called Lookup-based MultiScale Feature Interaction that determines the correlations between local joints and global contexts across multiple scales. This mechanism generates delicate representations that focus on keypoint regions. Altogether, by extending diffusion models, we show two unique characteristics from DiffPose on pose estimation task: (i) the ability to combine multiple sets of pose estimates to improve prediction accuracy, particularly for challenging joints, and (ii) the ability to adjust the number of iterative steps for feature refinement without retraining the model. DiffPose sets new state-of-the-art results on three benchmarks: PoseTrack2017, PoseTrack2018, and PoseTrack21.
Mutual Information-Based Temporal Difference Learning for Human Pose Estimation in Video
Mar 15, 2023



Temporal modeling is crucial for multi-frame human pose estimation. Most existing methods directly employ optical flow or deformable convolution to predict full-spectrum motion fields, which might incur numerous irrelevant cues, such as a nearby person or background. Without further efforts to excavate meaningful motion priors, their results are suboptimal, especially in complicated spatiotemporal interactions. On the other hand, the temporal difference has the ability to encode representative motion information which can potentially be valuable for pose estimation but has not been fully exploited. In this paper, we present a novel multi-frame human pose estimation framework, which employs temporal differences across frames to model dynamic contexts and engages mutual information objectively to facilitate useful motion information disentanglement. To be specific, we design a multi-stage Temporal Difference Encoder that performs incremental cascaded learning conditioned on multi-stage feature difference sequences to derive informative motion representation. We further propose a Representation Disentanglement module from the mutual information perspective, which can grasp discriminative task-relevant motion signals by explicitly defining useful and noisy constituents of the raw motion features and minimizing their mutual information. These place us to rank No.1 in the Crowd Pose Estimation in Complex Events Challenge on benchmark dataset HiEve, and achieve state-of-the-art performance on three benchmarks PoseTrack2017, PoseTrack2018, and PoseTrack21.
2D Human Pose Estimation: A Survey
Apr 15, 2022
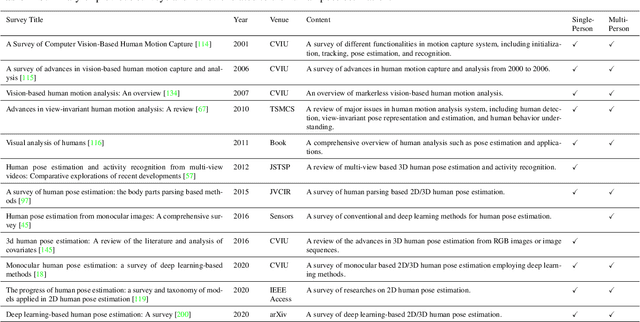
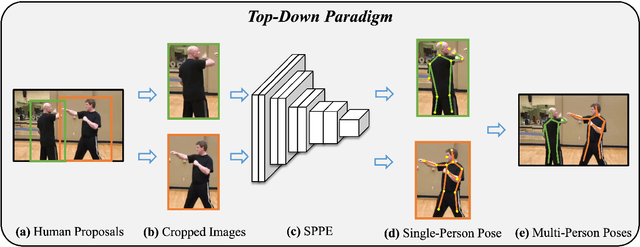
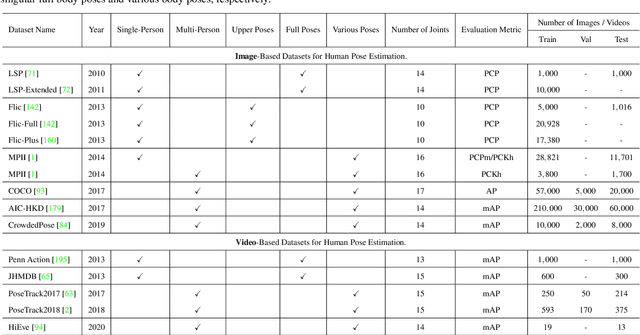
Human pose estimation aims at localizing human anatomical keypoints or body parts in the input data (e.g., images, videos, or signals). It forms a crucial component in enabling machines to have an insightful understanding of the behaviors of humans, and has become a salient problem in computer vision and related fields. Deep learning techniques allow learning feature representations directly from the data, significantly pushing the performance boundary of human pose estimation. In this paper, we reap the recent achievements of 2D human pose estimation methods and present a comprehensive survey. Briefly, existing approaches put their efforts in three directions, namely network architecture design, network training refinement, and post processing. Network architecture design looks at the architecture of human pose estimation models, extracting more robust features for keypoint recognition and localization. Network training refinement tap into the training of neural networks and aims to improve the representational ability of models. Post processing further incorporates model-agnostic polishing strategies to improve the performance of keypoint detection. More than 200 research contributions are involved in this survey, covering methodological frameworks, common benchmark datasets, evaluation metrics, and performance comparisons. We seek to provide researchers with a more comprehensive and systematic review on human pose estimation, allowing them to acquire a grand panorama and better identify future directions.
Temporal Feature Alignment and Mutual Information Maximization for Video-Based Human Pose Estimation
Apr 03, 2022
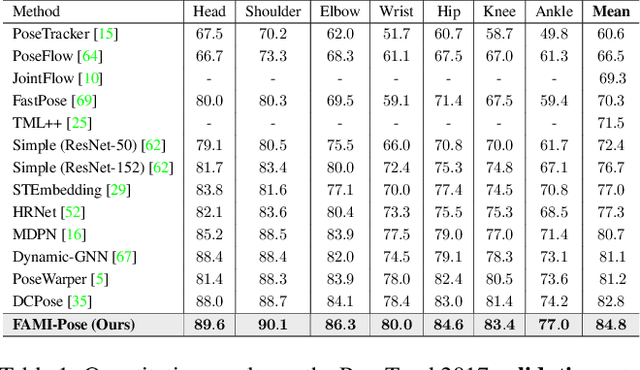
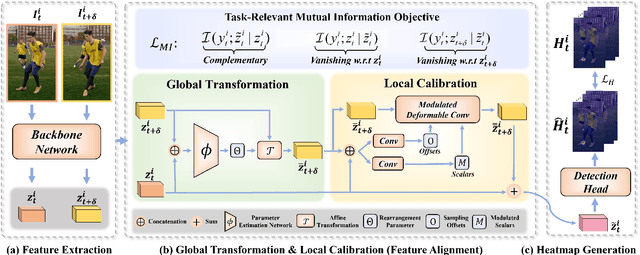
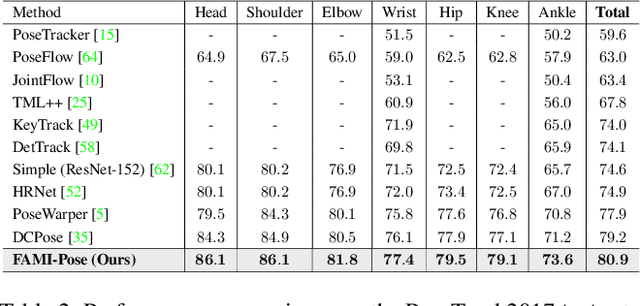
Multi-frame human pose estimation has long been a compelling and fundamental problem in computer vision. This task is challenging due to fast motion and pose occlusion that frequently occur in videos. State-of-the-art methods strive to incorporate additional visual evidences from neighboring frames (supporting frames) to facilitate the pose estimation of the current frame (key frame). One aspect that has been obviated so far, is the fact that current methods directly aggregate unaligned contexts across frames. The spatial-misalignment between pose features of the current frame and neighboring frames might lead to unsatisfactory results. More importantly, existing approaches build upon the straightforward pose estimation loss, which unfortunately cannot constrain the network to fully leverage useful information from neighboring frames. To tackle these problems, we present a novel hierarchical alignment framework, which leverages coarse-to-fine deformations to progressively update a neighboring frame to align with the current frame at the feature level. We further propose to explicitly supervise the knowledge extraction from neighboring frames, guaranteeing that useful complementary cues are extracted. To achieve this goal, we theoretically analyzed the mutual information between the frames and arrived at a loss that maximizes the task-relevant mutual information. These allow us to rank No.1 in the Multi-frame Person Pose Estimation Challenge on benchmark dataset PoseTrack2017, and obtain state-of-the-art performance on benchmarks Sub-JHMDB and Pose-Track2018. Our code is released at https://github. com/Pose-Group/FAMI-Pose, hoping that it will be useful to the community.
Deep Dual Consecutive Network for Human Pose Estimation
Mar 19, 2021
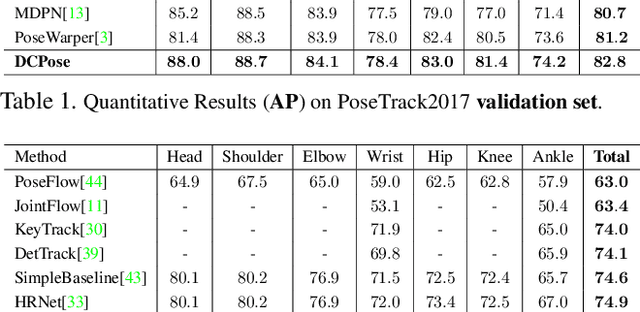
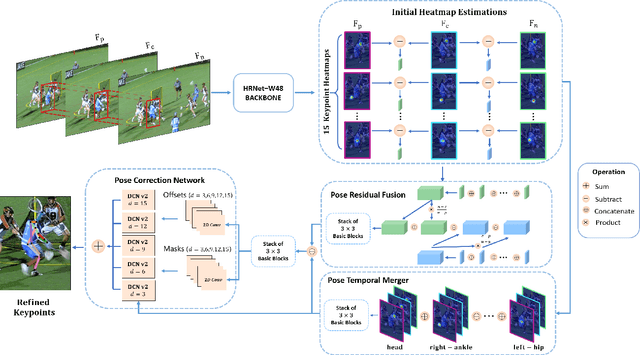
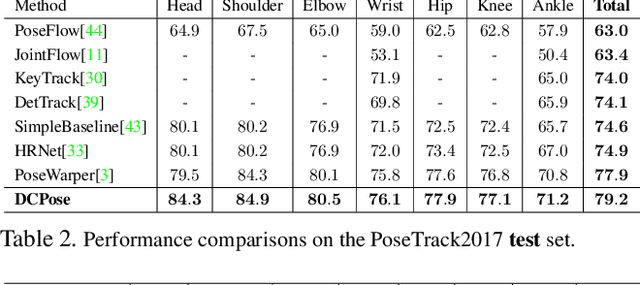
Multi-frame human pose estimation in complicated situations is challenging. Although state-of-the-art human joints detectors have demonstrated remarkable results for static images, their performances come short when we apply these models to video sequences. Prevalent shortcomings include the failure to handle motion blur, video defocus, or pose occlusions, arising from the inability in capturing the temporal dependency among video frames. On the other hand, directly employing conventional recurrent neural networks incurs empirical difficulties in modeling spatial contexts, especially for dealing with pose occlusions. In this paper, we propose a novel multi-frame human pose estimation framework, leveraging abundant temporal cues between video frames to facilitate keypoint detection. Three modular components are designed in our framework. A Pose Temporal Merger encodes keypoint spatiotemporal context to generate effective searching scopes while a Pose Residual Fusion module computes weighted pose residuals in dual directions. These are then processed via our Pose Correction Network for efficient refining of pose estimations. Our method ranks No.1 in the Multi-frame Person Pose Estimation Challenge on the large-scale benchmark datasets PoseTrack2017 and PoseTrack2018. We have released our code, hoping to inspire future research.