 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Video to Control: A Survey of Learning Manipulation Interfaces from Temporal Visual Data
Apr 04, 2026Video is a scalable observation of physical dynamics: it captures how objects move, how contact unfolds, and how scenes evolve under interaction -- all without requiring robot action labels. Yet translating this temporal structure into reliable robotic control remains an open challenge, because video lacks action supervision and differs from robot experience in embodiment, viewpoint, and physical constraints. This survey reviews methods that exploit non-action-annotated temporal video to learn control interfaces for robotic manipulation. We introduce an \emph{interface-centric taxonomy} organized by where the video-to-control interface is constructed and what control properties it enables, identifying three families: direct video--action policies, which keep the interface implicit; latent-action methods, which route temporal structure through a compact learned intermediate; and explicit visual interfaces, which predict interpretable targets for downstream control. For each family, we analyze control-integration properties -- how the loop is closed, what can be verified before execution, and where failures enter. A cross-family synthesis reveals that the most pressing open challenges center on the \emph{robotics integration layer} -- the mechanisms that connect video-derived predictions to dependable robot behavior -- and we outline research directions toward closing this gap.
Collaborative Learning for 3D Hand-Object Reconstruction and Compositional Action Recognition from Egocentric RGB Videos Using Superquadrics
Jan 13, 2025

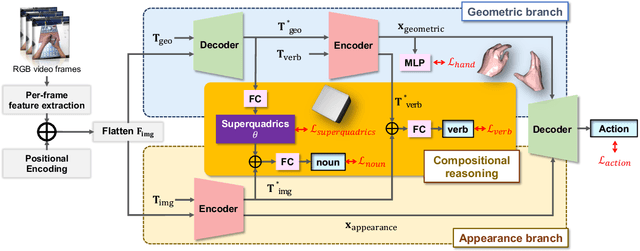

With the availability of egocentric 3D hand-object interaction datasets, there is increasing interest in developing unified models for hand-object pose estimation and action recognition. However, existing methods still struggle to recognise seen actions on unseen objects due to the limitations in representing object shape and movement using 3D bounding boxes. Additionally, the reliance on object templates at test time limits their generalisability to unseen objects. To address these challenges, we propose to leverage superquadrics as an alternative 3D object representation to bounding boxes and demonstrate their effectiveness on both template-free object reconstruction and action recognition tasks. Moreover, as we find that pure appearance-based methods can outperform the unified methods, the potential benefits from 3D geometric information remain unclear. Therefore, we study the compositionality of actions by considering a more challenging task where the training combinations of verbs and nouns do not overlap with the testing split. We extend H2O and FPHA datasets with compositional splits and design a novel collaborative learning framework that can explicitly reason about the geometric relations between hands and the manipulated object. Through extensive quantitative and qualitative evaluations, we demonstrate significant improvements over the state-of-the-arts in (compositional) action recognition.
Object Gaussian for Monocular 6D Pose Estimation from Sparse Views
Sep 04, 2024



Monocular object pose estimation, as a pivotal task in computer vision and robotics, heavily depends on accurate 2D-3D correspondences, which often demand costly CAD models that may not be readily available. Object 3D reconstruction methods offer an alternative, among which recent advancements in 3D Gaussian Splatting (3DGS) afford a compelling potential. Yet its performance still suffers and tends to overfit with fewer input views. Embracing this challenge, we introduce SGPose, a novel framework for sparse view object pose estimation using Gaussian-based methods. Given as few as ten views, SGPose generates a geometric-aware representation by starting with a random cuboid initialization, eschewing reliance on Structure-from-Motion (SfM) pipeline-derived geometry as required by traditional 3DGS methods. SGPose removes the dependence on CAD models by regressing dense 2D-3D correspondences between images and the reconstructed model from sparse input and random initialization, while the geometric-consistent depth supervision and online synthetic view warping are key to the success. Experiments on typical benchmarks, especially on the Occlusion LM-O dataset, demonstrate that SGPose outperforms existing methods even under sparse view constraints, under-scoring its potential in real-world applications.
GeoReF: Geometric Alignment Across Shape Variation for Category-level Object Pose Refinement
Apr 17, 2024Object pose refinement is essential for robust object pose estimation. Previous work has made significant progress towards instance-level object pose refinement. Yet, category-level pose refinement is a more challenging problem due to large shape variations within a category and the discrepancies between the target object and the shape prior. To address these challenges, we introduce a novel architecture for category-level object pose refinement. Our approach integrates an HS-layer and learnable affine transformations, which aims to enhance the extraction and alignment of geometric information. Additionally, we introduce a cross-cloud transformation mechanism that efficiently merges diverse data sources. Finally, we push the limits of our model by incorporating the shape prior information for translation and size error prediction. We conducted extensive experiments to demonstrate the effectiveness of the proposed framework. Through extensive quantitative experiments, we demonstrate significant improvement over the baseline method by a large margin across all metrics.
Multi-Resolution Planar Region Extraction for Uneven Terrains
Nov 21, 2023



This paper studies the problem of extracting planar regions in uneven terrains from unordered point cloud measurements. Such a problem is critical in various robotic applications such as robotic perceptive locomotion. While existing approaches have shown promising results in effectively extracting planar regions from the environment, they often suffer from issues such as low computational efficiency or loss of resolution. To address these issues, we propose a multi-resolution planar region extraction strategy in this paper that balances the accuracy in boundaries and computational efficiency. Our method begins with a pointwise classification preprocessing module, which categorizes all sampled points according to their local geometric properties to facilitate multi-resolution segmentation. Subsequently, we arrange the categorized points using an octree, followed by an in-depth analysis of nodes to finish multi-resolution plane segmentation. The efficiency and robustness of the proposed approach are verified via synthetic and real-world experiments, demonstrating our method's ability to generalize effectively across various uneven terrains while maintaining real-time performance, achieving frame rates exceeding 35 FPS.
HS-Pose: Hybrid Scope Feature Extraction for Category-level Object Pose Estimation
Mar 28, 2023
In this paper, we focus on the problem of category-level object pose estimation, which is challenging due to the large intra-category shape variation. 3D graph convolution (3D-GC) based methods have been widely used to extract local geometric features, but they have limitations for complex shaped objects and are sensitive to noise. Moreover, the scale and translation invariant properties of 3D-GC restrict the perception of an object's size and translation information. In this paper, we propose a simple network structure, the HS-layer, which extends 3D-GC to extract hybrid scope latent features from point cloud data for category-level object pose estimation tasks. The proposed HS-layer: 1) is able to perceive local-global geometric structure and global information, 2) is robust to noise, and 3) can encode size and translation information. Our experiments show that the simple replacement of the 3D-GC layer with the proposed HS-layer on the baseline method (GPV-Pose) achieves a significant improvement, with the performance increased by 14.5% on 5d2cm metric and 10.3% on IoU75. Our method outperforms the state-of-the-art methods by a large margin (8.3% on 5d2cm, 6.9% on IoU75) on the REAL275 dataset and runs in real-time (50 FPS).